深入理解Linux网络
豆瓣:https://book.douban.com/subject/35922722/
张彦飞 2022年出版
关于Linux网络很好的一本书,理论结合源码,结合实践思考,很有启发性;彩色印刷,插图精美,阅读体验很好。
第1章 绪论
作者工作中的困惑与思考:
- 过多的time_wait,有哪些开销和问题?怎么解决?
- 长连接开销,一条空闲的tcp连接到底有多大开销?服务器和客户端可以支撑多少条tcp连接?
- 负载低,但cpu很高的场景
- 访问127.0.0.1/192.168.0.1经过网卡吗?
- 软中断与硬中断
- 零拷贝
- DPDK
关于Kb,kb,大写K代表1024,小写k代表1000。
更正规的K和k
其实更加正规的单位是KiB、Kib等,中间有个小写的i。IEC定义的标准单位,加了i表示2的10次方,即1024。
一些术语:
- skb:skb是struct sk_buff对象的简称。struct sk_buff是Linux网络模块中的核心结构体,各个层用到的数据包都是存在这个结构体里的。
第2章 内核是如何接收网络包的
关于本章,笔记也可以参考别人的读书笔记:https://joytsing.cn/posts/20149/
网络模块是Linux内核中最复杂的模块了,看起来一个简单的收包过程就涉及许多内核组件之间的交互,如网卡驱动、协议栈、内核ksoftirqd线程等。
图2.1 TCP/IP网络分层模型 第12页
用户进程在应用层,网卡网线是物理层,中间则是Linux内核,包括协议栈(传输层和网络层)和驱动(网络设备驱动,属链路层)。用户进程调用socket,就通过系统调用进入内核态了。
内核和网络设备驱动式通过中断的方式来处理的。
Linux的中断处理函数是分上半部分和下半部分的。硬中断是通过给CPU物理引脚施加电压变化实现的,而软中断式通过给内存中的一个变量赋予二进制值以标记有软中断发生,由ksoftirqd内核线程全权处理。
图2.2 内核收包路径 第13页
图2.10 硬中断处理 第23页
图 2.11 软中断处理 第25页
软中断与硬中断的关联:只要硬中断在哪个CPU上被响应,那么软中断页是在这个CPU上处理的。
如果发现软中断的CPU消耗都集中在一个核上,应该调整硬中断的CPU亲和性,将硬中断打散到不同的CPU核上。这样硬中断后面的软中断CPU开销也将由多个核来分担。
大致总结收包过程,当数据到来以后,第⼀个迎接它的是⽹卡:
- ⽹卡将数据帧DMA到内存的RingBuffer中,然后向CPU发起中断通知。
- CPU响应中断请求,调⽤⽹卡启动时注册的中断处理函数。
- 中断处理函数⼏乎没⼲什么,只发起了软中断请求。
- 内核线程ksoftirqd发现有软中断请求到来,先关闭硬中断。
- ksoftirqd线程开始调⽤网卡驱动的poll函数收包。
- poll函数将收到的包送到协议栈注册的ip_rcv函数中。
- ip_rcv函数将包送到udp_rcv函数中(对于TCP包是送到tcp_rcv_v4)。
关于RingBuffer
RingBuffer是内存中的一块特殊区域,网卡在收到数据的时候以DMA的方式将包写到RingBuffer中。
RingBuffer这个数据结构包括igb_rx_buffer环形队列数组、e1000_adv_rx_desc环形队列数组及众多的skb,如下图所示:
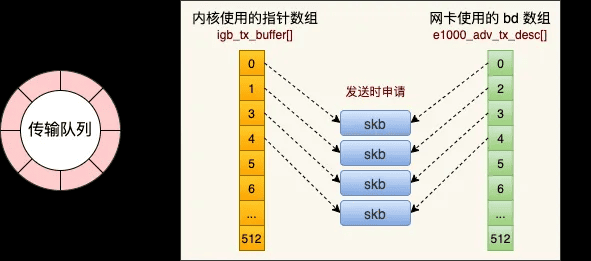
网卡在收到数据的时候以DMA的方式将包写到RingBuffer中。
软中断收包的时候来这里把skb取走,并申请新的skb重新挂上去。
RingBuffer中指针数组是预先分配好的,而skb虽然也会预先分配好,但是在后面收包过程中会不断动态地分配申请。
如果内核处理得不及时导致RingBuffer满了,那后面新来的数据包就会被丢弃。
RingBuffer是有大小和长度限制的,长度可以通过ethtool工具查看。
bash
ethtool -g eth0如果内核处理得不及时导致RingBuffer满了,那后面的数据包就会被丢弃,通过ethtool或ifconfig工具可以查看是否有溢出发生。(书中第35页)
bash
ethtool -S eth0ksoftirqd内核线程
一台两核的虚拟机上有两个ksoftirqd内核线程。机器上有几个核,内核就会创建几个ksoftirqd线程出来。 内核线程ksoftirqd包含了所有的软中断处理函数。
软中断都是在ksoftirqd内核线程中执行的。软中断的信息可以从/proc/softirqs读取。
网卡开启多队列
现在的主流网卡基本上都是支持多队列的,通过ethtool可以查看当前网卡的多队列情况。
bash
ethtool -l eth0Combined表示网卡支持的队列数。也可以通过ethtool加大队列。书中第37页。
每个队列都会有独立的、不同的中断号,而中断号亲和的CPU不同,不同的队列在将数据收到自己的RingBuffer后,可以分别向不同的CPU发起硬中断通知。
而在硬中断的处理中,哪个核响应的硬中断,那么该硬中断发起的软中断任务就必然由这个核来处理,所以在工作实践中,如果网络包的接收频率高而导致个别核si偏高,那么通过加大网卡队列数,并设置每个队列中断号上的smp_affinity,将各个队列的硬中断打散到不同的CPU上就行了。
网络接收过程中的CPU开销
在网络的接收过程中,主要工作集中在硬中断和软中断上,二者的消耗都可以通过top命令来查看。其中hi是CPU处理硬中断的开销,si是处理软中断的开销,都是以百分比的形式来展示的。
如果发现某个核的si过高,那么很有可能你的业务上当前数据包的接收已经非常频繁了,需要通过上面说的多队列网卡配置让其他核参与进来,分担这个核接收包的内核工作量。
tcpdump与iptable/netfilter
tcpdump工作在设备层(网络设备层),是通过虚拟协议的方式工作的。它通过调用packet_create将抓包函数以协议的形式挂到ptype_all上。数据包先送到ptype_all抓包点,然后再将包送到协议栈函数(ip_rcv、arp_rcv等)。
iptable/netfilter主要是在IP、ARP等层实现的。
图2.13 收包工作过程 第38页
收包和发包的顺序是相反的,所以收包时肯定先经过tcpdump;发包则先经过iptable/netfilter,会被过滤,tcpdump就抓不到包了。
图2.13 发包工作过程 第39页
DPDK
用户进程能否绕开内核协议栈,自己直接从网卡接收数据呢?DPDK就是其中一种。可以避开繁杂的内核协议栈处理、内核态到用户态内存拷贝开销、唤醒用户进程开销等。
第3章 内核与用户进程协作
协议栈接收、处理完输入包以后,要通知到用户进程,让用户进程能够收到并处理这些数据。用户进程与内核配合有很多种方案,两种典型的:
- 同步阻塞(Java中叫BIO)
- IO多路复用(Java中叫NIO)
Linux上多路复用方案有select、poll、epoll,其中epoll的性能表现是最优秀的。
同步阻塞
阻塞是进程因为等待某个事件而主动让出CPU挂起的操作。主要看有没有放弃CPU。
在网络IO中,当进程等待socket上的数据时,如果数据还没有到来,那就把当前进程状态从TASK_RUNNING修改成TASK_INTERRUPTIBLE,然后让出CPU。由调度器来调度下一个就绪状态的进程来执行。
图3.4 同步阻塞工作流程 第47页
图3.5 recvfrom系统调用 第48页
图3.9 软中断接收数据过程 第52页
图3.12 同步阻塞流程汇总 第58页
同步阻塞有哪些开销?
阻塞让出CPU有一次上下文切换,数据就绪的时候,睡眠进程又被唤醒,又一次上下文切换。最关键的是,一个进程同时只能等待一条连接(socket),高并发就需要很多进程,每个进程大约占用几MB的内存。
epoll
IO多路复用,这里的复用指的是对进程的复用。
和epoll相关的函数有三个:
- epoll_create:创建一个epoll对象
- epoll_ctl:向epoll对象添加要管理的连接
- epoll_wait:等待其管理的连接上的IO事件
为什么epoll要使用红黑树:为了让epoll在查找效率、插入效率、内存开销等多个方面比较均衡。
当没有IO事件的时候,epoll也会阻塞掉当前进程。这个是合理的,因为没有事情可做了占着CPU页没什么意义。epoll本身是阻塞的,但一般会把socket设置成非阻塞。
图3.26 epoll原理汇总 第79页
图中可看到,epoll_wait管理:
- 就绪队列空,主动放弃CPU,产生阻塞
- 数据包进来,epoll就绪队列不为空,唤醒epoll_wait
实践中,只要活儿足够多,epoll_wait根部不会让进程阻塞。
多路复用提高网络性能主要是减少了无用的上下文切换,还可以服用进程,一个进程可以处理多条socket,只要一直干活,epoll_wait就不会出让CPU,即不会阻塞。
阻塞不会导致低性能,过多过频繁的阻塞才会。epoll的阻塞和它的高性能并不冲突。
Redis在网络IO性能上表现非常突出,单进程的服务器在极限情况下可以达到10万qps。
Redis的主要业务逻辑就是在本机内存上的数据结构的读写,几乎每有网络IO和磁盘IO,单个请求处理起来很快,所以它主服务干脆就做成单进程的,这样省去了多进程之间协作的负担,也更大程度减少了进程切换。进程主要的工作就是用epoll_wait等待事件,有事件以后处理,处理完以后再调用epoll_wait。
Redis6.0以后也开始支持多进程了,不过默认情况下仍然是关闭的。(触碰到单实例的瓶颈。)
第4章 内核是如何发送网络包的
图4.1 网络发送过程概览 第86页
图4.2 网络发送过程 第87、88页
图4.3 发送完毕清理 第89页
图4.4 网卡的接收和发送队列 第90页
图4.5 发送队列细节 第92页
邻居子系统是位于网络层和数据链路层中间的一个系统,其作用是为网络层提供一个下层的封装,让网络层不必关心下层的地址信息,让下层来决定发送到哪个MAC地址。
图4.15 邻居子系统位置 第103页
图4.16 邻居子系统 第104页
图4.17 网络设备子系统 第106页
图4.21 RingBuffer回收 第114页
图4.22 网络发送过程汇总 第116页
图4.24 read+send系统调用发送文件经过的拷贝过程 第118页
图4.25 sendfile系统调用发送文件的过程 第118页
在sendfile系统调用里,数据不需要拷贝到用户空间,在内核态就能完成发送处理,显著减少了需要拷贝的次数。 Kafka高性能的原因之一就是采用了sendfile系统调用来发送网络数据包,减少了内核态和用户态之间的频繁数据拷贝。
发送数据的时候涉及哪些内存拷贝操作?
- 第一次拷贝操作是内核申请完skb后,将用户传递进来的buffer里的数据内容都拷贝到skb。
- 第二次拷贝操作是从传输层进入网络层的时候,每一个skb都会被浅拷贝(只拷贝skb描述符本身,所指向的数据还是复用的)出来一个新的副本,对方没有发回ack的时候,才能重传,保证可靠传输。
- 第三次不是必须的,ip层发现skb大于MTU的时候才需要进行切片。此时会再申请额外的skb,并将原来的skb拷贝为多个小的skb。(尽量控制数据包小于MTU,杜绝了分片开销,也降低了重传率)
大家在谈论网络性能优化经常听到零拷贝,这个词有点扩张。TCP为了保证可靠性,第二次拷贝没法省去,包大于MTU,分片拷贝也避免不了。
关于零拷贝,这篇文章也写得很好:
第5章 深度理解本机网络IO
图5.6 单次跨机网络通信过程 第127页
图5.13 本机网络IO过程 第137页
主要区别:本机节约了驱动上的一些开销,发送数据不需要进RingBuffer的驱动队列,直接把skb传给接收协议栈(经过软中断)。另外,由于并不真的经过网卡,所以网卡的收发过程,硬中断就省去了,直接从软中断开始。其他的系统调用、协议栈、设备子系统、驱动程序都走了。
本机有办法绕开协议栈的开销,要动用eBPF,使用eBPF的sockmap和sk redirect可以达到真正不走协议栈的目的。
本机ip和127.0.0.1一样都是走环回设备lo。这是因为内核在设置ip的时候,把所有本机ip都初始化到local路由表里了,类型写死了是RTN_LOCAL。可以通过抓包验证。
第6章 理解TCP连接建立过程
为什么服务端程序都需要先listen一下?
c
int main(int argc, char const *argv[])
{
int fd = socket(AF_INET, SOCK_STREAM, 0);
bind(fd, ...);
listen(fd, 128);
accept(fd, ...);
}服务端核心逻辑是创建socket绑定端口,listen监听,最后accept接收客户端的请求。
用户态的socket文件描述符只是一个整数而已,内核是没有办法直接用的。所以该函数中第一行代码就是根据用户传入的文件描述符来查找对应的socket内核对象。
listen最主要的工作就是申请和初始化接收队列,包括全连接队列和半连接队列。
重点:全连接队列与半连接队列的长度计算方式 第148页。
图6.4 socket数据结构 第149页
当遇到CANNOT ASSIGN REQUESTED ADDRESS错误,就应该想到去查一下net.ipv4.ip_local_port_range中设置的可用端口范围是不是太小了。
记住四元组确认一条TCP/UDP连接,只要有一个不一样,就可以继续使用。所以一台客户端机器最大能建立的连接数不是65535,只要服务端足够多,单机发出百万条连接没有任何问题。如果目标服务器ip固定,那就不行了,由四元组的组合数量确定。
客户端connect分析:
c
int main()
{
fd = socket(AF_INET, SOCKET_STREAM, 0);
connect(fd, ...);
......
}客户端的核心逻辑是创建socket,然后调用connect系统调用去连接服务端。
客户端在执行connect函数的时候,把本地的socket状态设置成了TCP_SYN_SENT,选了一个可用的端口,接着发出SYN握手请求并启动重传定时器。
默认情况下一个端口只会被使用一次,对于客户端角色的socket,不建议使用bind。
connect的时候,会随机地从ip_local_port_range选择一个位置开始循环判断,找到可用端口后,发出syn握手包。如果段鸥被用光了,这时候内核就大概率要把循环多执行很多轮才能找到可用端口,导致connect系统调用的CPU开销上涨。
图6.6 三次握手 第158页
服务端收到syn握手包后的判断。第161页。
- 首先判断半连接队列是否满了,如果满了,且未开启tcp_syncookies,那么该握手包将被直接丢弃。
- 接着判断全连接队列是否满了,因为全连接队列满了会导致握手异常,所以第一次握手的时候也判断了。如果全连接队列满了,且young_ack(未处理完的半连接请求)数量大于1,那也是同样会直接丢弃。
都没满的话,发出synack,半连接队列+1,同样启动定时器。
客户端响应来自服务端的synack时清楚了connect时设置的重传定时器,把当前socket状态设置为ESTALISHED,开启保活计时器后发出第三次握手的ack确认。
第三次握手,服务端这里又继续判断一次全连接队列是否满了,如果满了修改一下计时器就丢弃了。如果不满,就创建新的sock对象加入全连接队列,把连接请求块从半连接队列中删除,设置连接为ESTALISHED。
图6.7 三次握手详细过程
一条TCP连接建立的时间组成:
- 内核消耗CPU进行接收、发送和处理,包括系统该调用、软中断和上下文切换,它们的耗时都是几微秒左右。
- 网络传输,包经过各式各样的网线、交换机和路由器。耗时相比CPU处理,就要高多了,根据网络远近一般在几毫秒到几百毫秒不等。
tcp三次传输,加上双方少许的CPU开销,总共比1.5RTT大一点。但是对客户端和服务端来说,基本是一个RTT左右。(客户端接发送第三次ack的时候基本就可以开始请求了,服务端收到syn到收到第三个ack,也是一个RTT左右。)
图6.10 连接队列满异常 第173页
默认重传1秒后,然后2秒,4秒,8秒。。
图6.12 第三次握手丢包 第177页
第三次握手丢包后,服务端重发synack(半连接定时器控制的)。客户端此时认为已经建立成功了,不会重发。
图6.13 连接成功前的数据包被无视 第177页
全连接队列长度确认:
bash
ss -nltSend-Q 表示全连接长度,如果Recv-Q已经逼近Send-Q,那么不需要等到丢白也应该加大全连接队列了。
全连接队列溢出查看:
bash
watch 'netstat -s | grep overflowed'netstat -s 这个结果是准确的,因为此项只有在全连接队列满的时候才会增加;但是半连接队列就不能通过这种方式查看了。至于半连接,不用纠结怎么查看,直接设置tcp_syncookies为1就可以了,永远不溢出。如果不设置又想查看是否溢出:
bash
netstat -antp | grep SYN_RECV然后判断这个数量是否达到理论上的半连接队列长度(计算麻烦,不建议这种方式)。
服务器在北京,在纽约访问,一个RTT往返时间是: 15000千米 x 2 / 光速 = 100毫秒
这还是最理想,不计算路由转发延迟。一般一个RTT要200毫秒以上。所以实际体验会很差。
如果在火星上,连接地球,一个RTT大概是366秒到2666秒之间。
第7章 一条TCP连接消耗的内存
服务器上一条ESTABLISHED状态的空连接需要消耗多少内存?
假设没有发送和接收缓冲区的开销,那么一个socket创建的内核对象内存加起来大概是3.3KB,6万条大概是20MB,对内存来说忽略不计。没有收发,CPU开销可以忽略不计。
3万多条TIME_WAIT状态的连接,内存开销多大?
一条TIME_WAIT状态的连接,大概占用0.4KB左右的内存,比空闲的ESTABLISHED小一个数量级,更加可以忽略不计。可能需要考虑的是,如果设置的端口范围比较小,而且连接的对象比较单一,那端口可能不够用。
以上ESTABLISHED还是TIME_WAIT数量过多,最多只能算是warning,不是error。
第8章 一台机器支持多少条TCP
理解最大文件描述符限制:
打开文件会消耗内存,Linux出于安全考虑,在多个位置限制了可打开的文件描述符的数量。由于TCP连接的socket也是文件,讨论并发连接数量必然先讨论最大文件描述符限制。
限制打开文件数的内核参数包含这三个nofile、fs.nr_open、fs.file-max。
nofile、fs.nr_open是进程级限制,进程打开文件数如果超过这两个参数,就会报错。这两个参数作用一样,他们都是用来限制单个进程的最大文件数量,区别是soft nofile可以按用户来配置,而所有用户只能配一个fs.nr_open(系统全局的)。
fs.file-max是系统级限制。它表示整个系统可打开的最大文件数,但不限制root用户。
这几个参数之间还有耦合关系:
- soft nofile和hard nofile要一起调整,实际生效的值会按二者最低的来。
- 如果加大了hard nofile,那fs.nr_open也需要跟着一起调整,如果不小心把hard nofile设置得比fs.nr_open大,会导致该用户无法登录。如果设置的是
*,那么所有的用户都无法登录。 - echo方式修改内核参数,重启会失效,还是无法登录,不要用echo方式修改内核参数。
如果想让进程可以打开100万个文件描述符,可以参考一下:
vi /etc/sysctl.conf
fs.file-max=1100000 // 系统级别设置110万,留点buffer
fs.nr_open=1100000 // 进程级别也设置成110万,要保证比hard nofile大
# sysctl -p
vim /etc/security/limits.conf
// 用户进程级别都设置成100万
* soft nofile 1000000
* hard nofile 1000000
// 如果是debian系列,需要指出具体的用户,不能用通配符*,centos可以。配置得当,4GB内存,发起100万条长连接都是没问题的,空连接一条3.3KB左右,如果发送/接收数据,会增加内存开销,因为内核对象会开启发送/接收缓冲区;此外,数据包会经过内核协议栈,所以也会消耗CPU。
接收缓冲区大小限制是通过一组内核参数控制的,可以查看和修改:
bash
sysctl -a | grep rmem发送缓冲区:
bash
sysctl -a | grep wmem综上,如果TCP连接上发送、接收很多,而且业务处理逻辑复杂的话(这是常态),那么别说100万了,可能1000并发就得躺倒了。
端口的配置范围最大是ip_local_port_range:1024 65535。针对一个服务端(单ip单端口)来说,最多只能发起6万4千个请求连接。
可以通过5台客户端,发起100万连接。不发送数据的话,4GB内存确实可以顶住100万条空连接。
查看活动的连接数量:
bash
ss -n | grep ESTAB | wc -l清理缓存:操作系统在运行的时候会生成很多的内核对象缓存,做实验之前最好是把这些缓存都清理了。使用如下命令清理pagecache/dentries和inodes这些缓存。
bash
echo "3" > /proc/sys/vm/drop_caches做一个长连接推送产品,支持1亿用户需要多少台机器?
对于长连接推送模块这种服务来说,给客户端发送数据只是偶尔的,绝大部分时间TCP连接都会空闲,CPU开销可以忽略。
再来考虑内存,假设服务器内存128GB,一台服务器可以考虑支持500万并发,大约消耗不到20GB内存去保存socket。剩下100多GB,用来应对发送和接收缓冲区等其他开销差不多够了。所以1亿用户,大概需要20台服务器。
第9章 网络性能优化建议
本章基本是关于之前内容的性能相关部分的汇总。
第10章 容器网络虚拟化
关于容器里网络命令空间、隔离抽象、veth、bridge、路由、nat、iptables的简要介绍。