深入理解计算机系统
豆瓣:https://book.douban.com/subject/26912767/
读书笔记,其中穿插一些《程序员的自我修养》的摘抄,哈工大本书课程的讲义。
其实直译为《从程序员的角度来理解计算机系统》也许更加贴切,因为该书虽然涉及的范围很广但是讲解的内容其实并不算特别深入。
非常好的书,翻译得也不错,值得长时间反复学习回味。关于操作系统,个人觉得最好的书,殿堂级别的著作。目标:阅读不下三遍。
注意
这本书的学习曲线对不少人来说比较陡峭(跟Vim编辑器一样),可以借助一些解读视频和笔记辅助学习,反复对照理解。反复咀嚼消化。
哈工大也是以这本为教材,github地址:https://github.com/HITLittleZheng/HITCS
笔记与各种视频讲解资料:
第1章 计算机系统漫游
编译系统
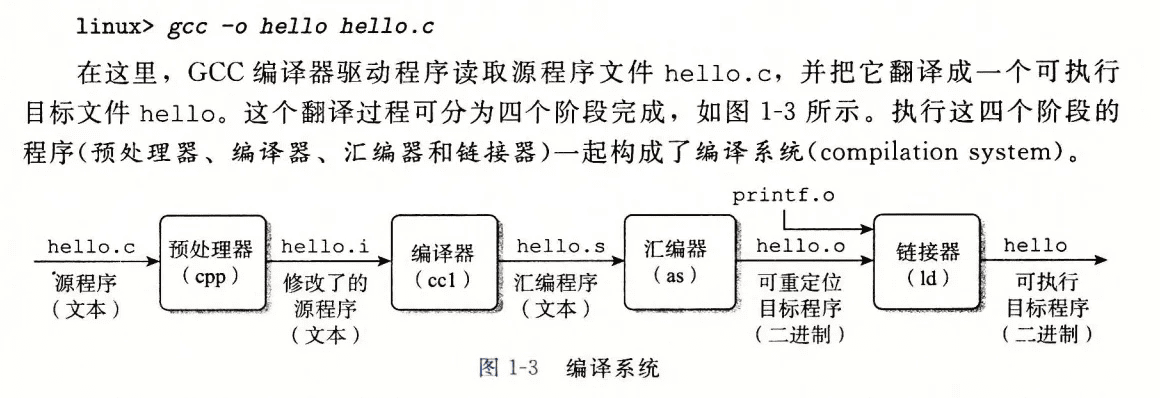
存储器层次结构
每个 I/O 设备都通过一个控制器或适配器与总线相连。控制器和适配器之间的区别主要在于它们的封装方式。控制器是 I/O设备本身或者系统的主板上的芯片组。而适配器则是一块插在主板插槽上的卡。它们的功能都是 I/O 总线和 I/O 设备之间传递信息。例如:USB控制器、磁盘控制器、图形适配器、网络适配器等。
操作系统有两个基本功能: (1) 防止硬件被失控的应用程序滥用; (2) 向应用程序提供简单一致的机制来控制复杂而又通常大不相同的低级硬件设备。操作系统通过几个基本的抽象概念(进程、虚拟内存和文件)来实现这两个功能。
进程是计算机科学中最重要和最成功的概念之一。进程是操作系统对一个正在运行的程序的一种抽象。在一个系统上可以同时运行多个进程,而每个进程都好像在独占地使用硬件。而并发运行,则是说一个进程的指令和另个进程的指令是交错执行的。
内核不是一个独立的进程。相反,它是系统管理全部进程所用代码和数据结构的集合。
Amdahl定律

注意
如果 60% 的系统能够加速到不花时间的程度,我们获得的净加速比将仍只有1/ 0. 4=2. 5X。
一个芯片含多个物理核
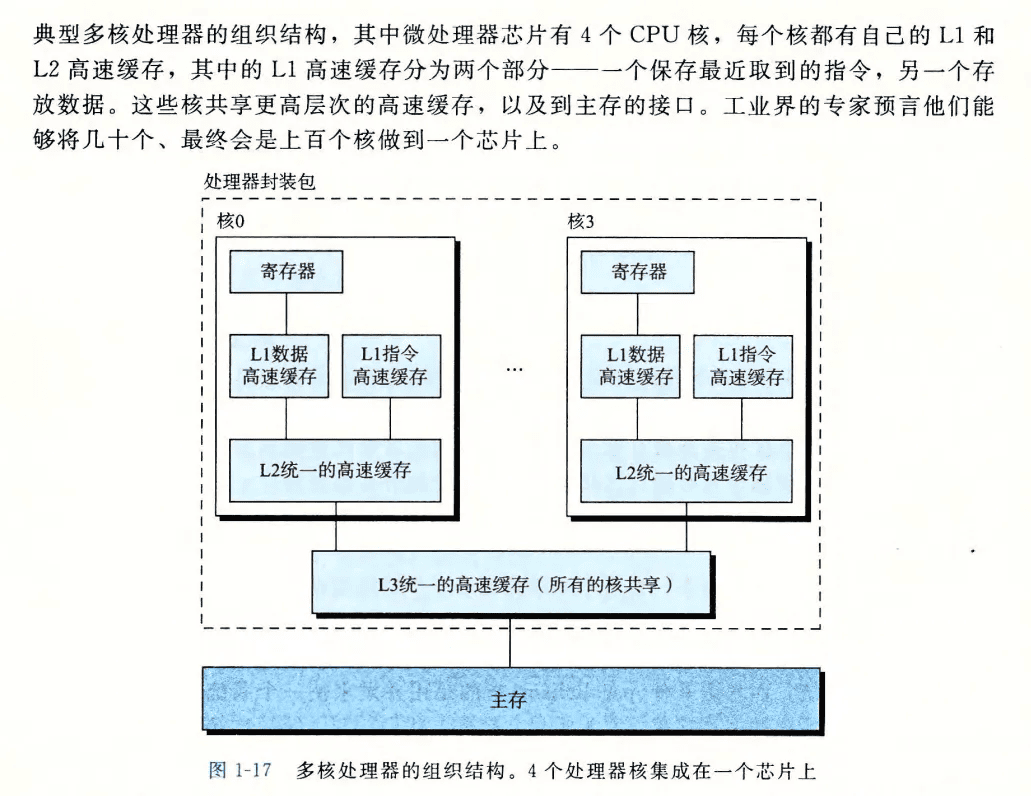
举例来说,Intel Core i7 处理器可以让每个核执行两个线程,所以一个4核的系统实际上可以并行地 执行8个线程。
计算机系统中的抽象
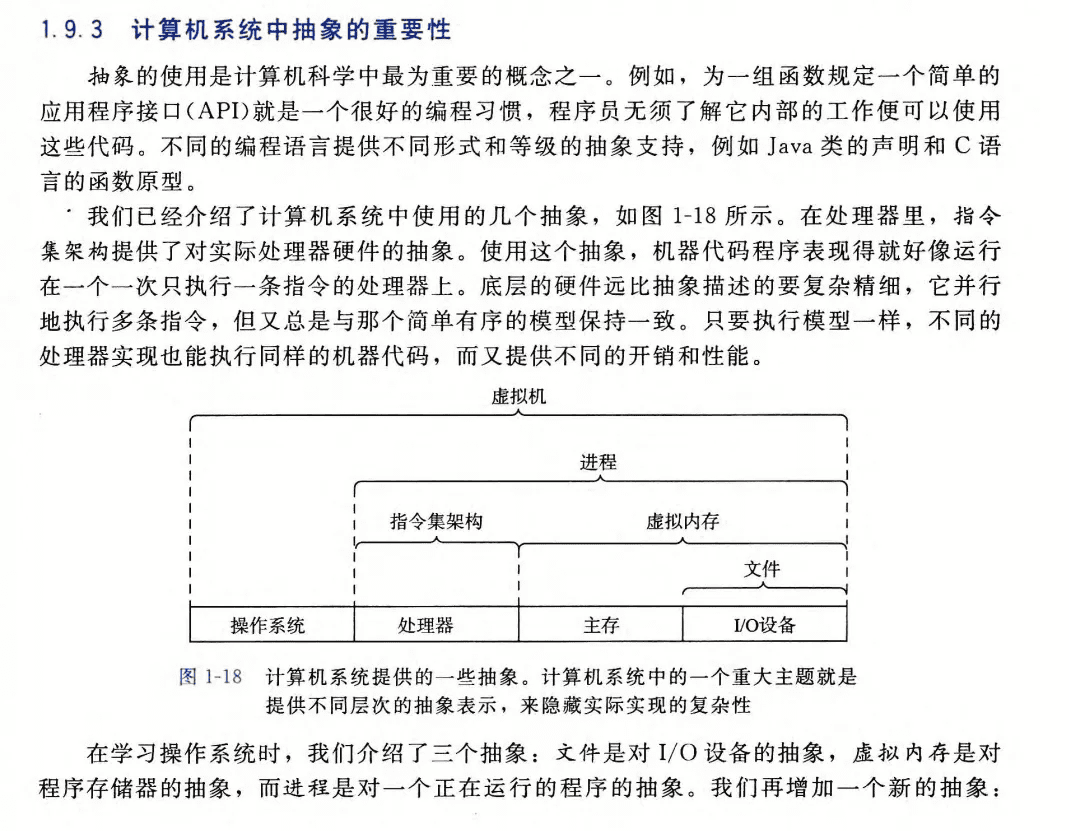

抽象的使用是计算机科学中最为重要的概念之一。
Keynote
文件是对I/O设备的抽象;虚拟内存是对程序存储器的抽象,而进程是对一个正在运行的程序的抽象。虚拟机是对整个计算机的抽象,包括操作系统、处理器和程序。
感悟
抽象:隐藏细节,只关注当前问题。计算机的精妙抽象,堪称伟大。
第2章 信息的表示和处理
C语言中一个指针的值(无论它指向一个整数、一个结构或是某个其他程序对象)都是某个存储块的第一个字节的虚拟地址。 编译器还把每个指针和类型信息联系起来,这样就可以根据指针值的类型,生成不同的机器级代码来访问存储在指针所指向位置处的值。
逻辑右移和算术右移:逻辑右移在左端补0,算术右移在左端补最高位的值。C语言标准并没有明确定义对于有符号数应该使用哪种类型的右移——算术右移或者逻辑右移都可以。几乎所有的编译器都对有符号数使用算术右移,无符号数则使用逻辑右移。
整数的表示虽然只能编码一个相对较小的数值范围,但这种表示是精确的;
浮点数可以编码一个较大的范围,但这种表示只是近似的。

32位程序和64位程序,区别在于程序是如何编译的,而不是其运行的机器类型。
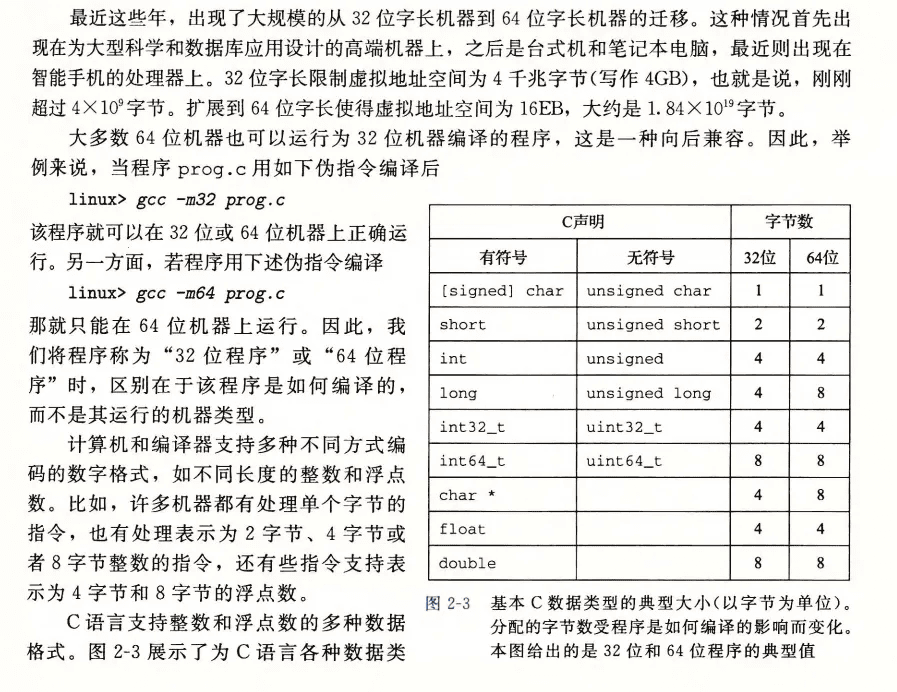
指针大小,32位编译下是4字节,64位编译是8字节。long的大小也不一样,其他基本一样。
为了避免由于依赖"典型”大小和不同编译器设置带来的奇怪行为, ISO C99 引入了一类数据类型,其数据大小是固定的,不随编译器和机器设置而变化,其中就有数据类型int32_t和int64_t,它们分别为4个字节和8个字节。使用确定大小的整数类型是程序员准确控制数据表示的最佳途径。

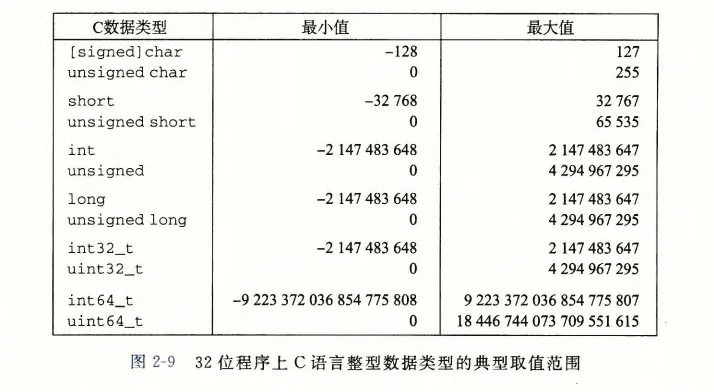

关于大端与小端,总结,目前基本所有移动设备和pc都是小端。
关于反码与补码:
- 反码:对于正数,其反码与原码相同;对于负数,其反码是将原码除符号位外的所有位取反。例如,十进制数-1的原码是10000001,其反码是1111111036。
- 补码:正数的补码与其原码相同;负数的补码是其反码加1。
- 计算机内部通常使用补码来存储和处理数字,因为这样可以避免使用专门的减法电路,简化了硬件设计。
- 补码的一个重要特性是它允许表示一个额外的负数。例如,在8位二进制中,使用原码或反码可以表示的范围是-127到+127,而使用补码可以表示的范围是-128到+127。
- 补码也解决了正零和负零的问题。在补码表示中,只有一个零的表示方式,即所有位都是0。
高德纳在《计算机程序设计的艺术》指出,虽然早在1946年就有人将二分查找的方法公诸于世,但直到1962年才有人写出没有bug的二分查找程序。
第3章 程序的机器级表示
汇编代码是机器代码的文本表示(人类可读)。用高级语言编写的程序可以在很多不同的机器上编译和执行,而汇编代码则是与特定机器密切相关的。
关于汇编,应该去读王爽的《汇编语言》,这里不再做笔记。
第4章 处理器体系架构
第5章 优化程序性能
第6章 存储器层次结构
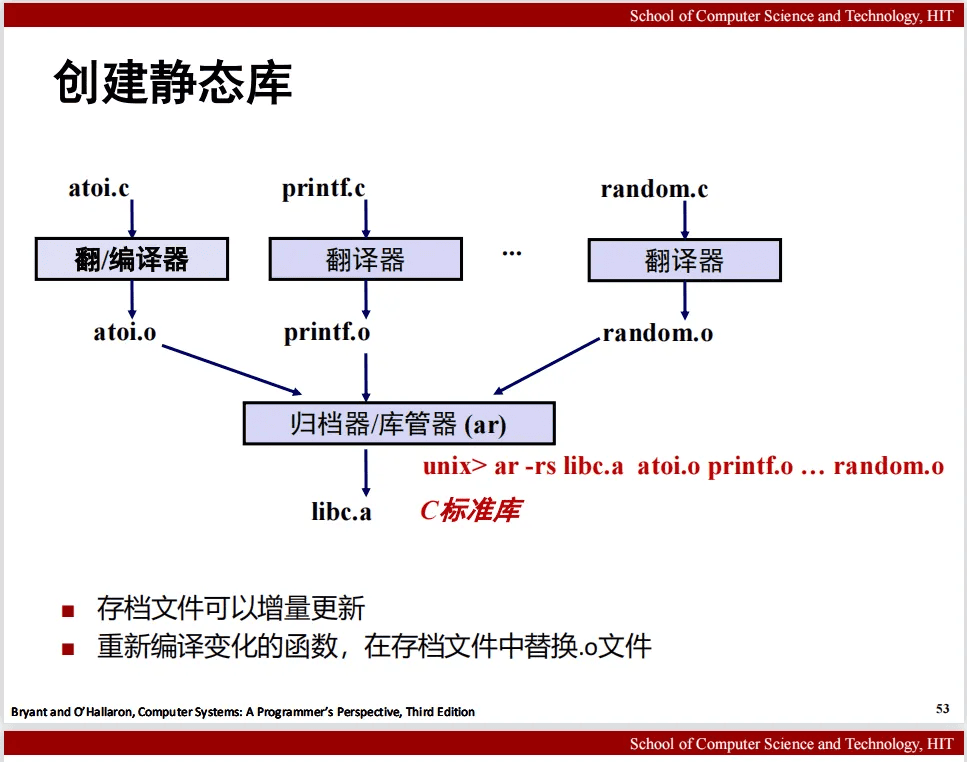
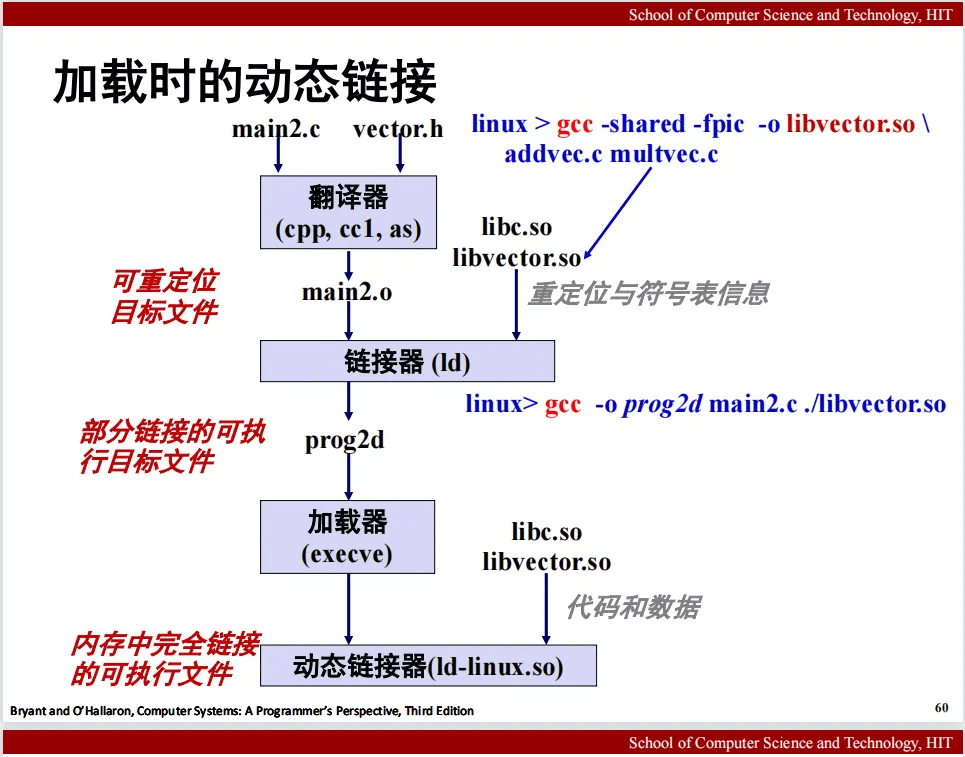
第7章 链接
参考哈工大讲义:

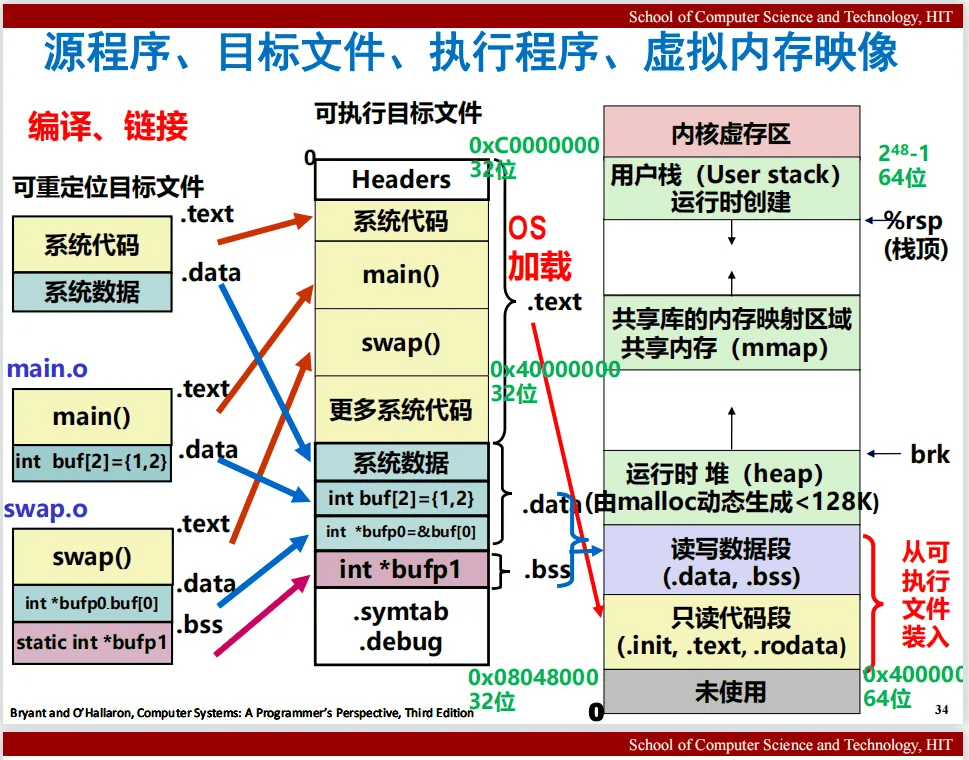


第8章 异常控制流
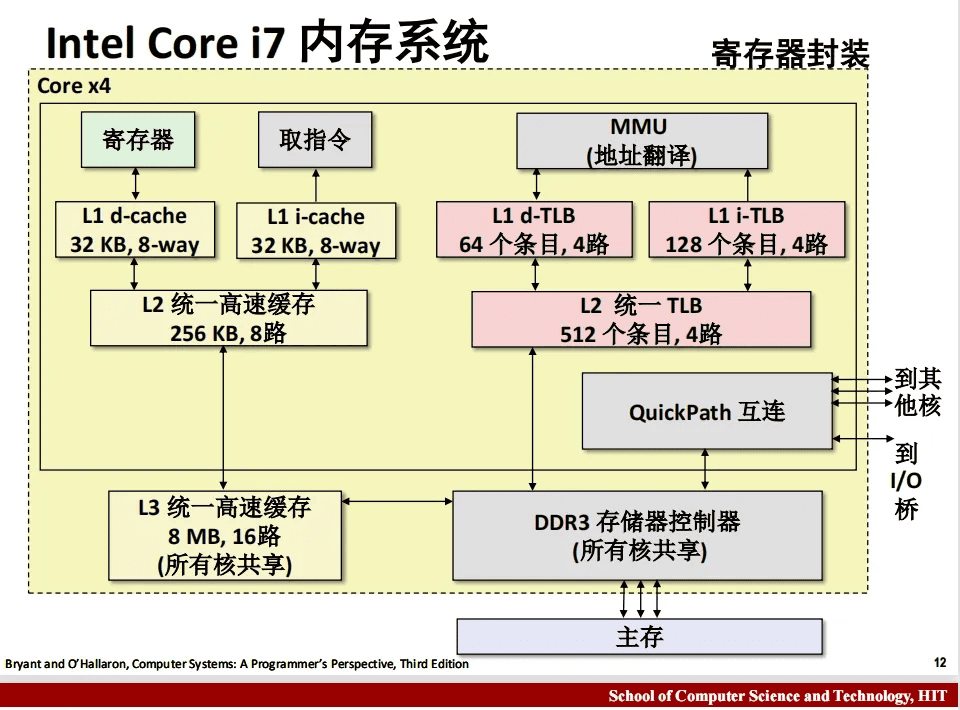
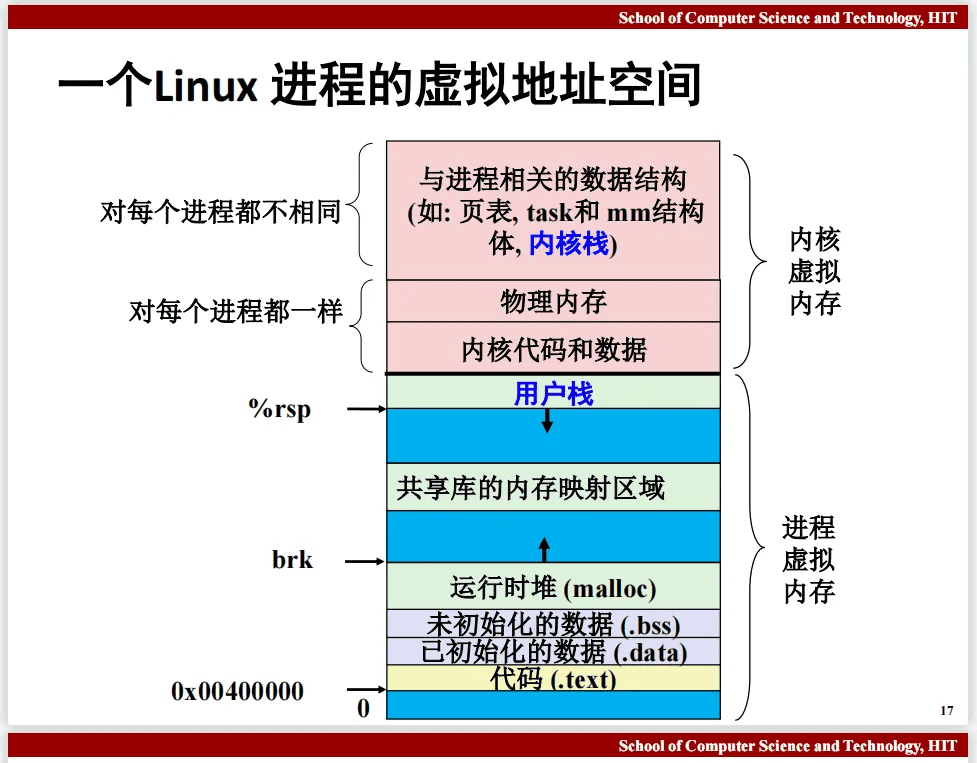
第9章 虚拟内存
参考哈工大讲义:

程序员的自我休养:链接、装载与库
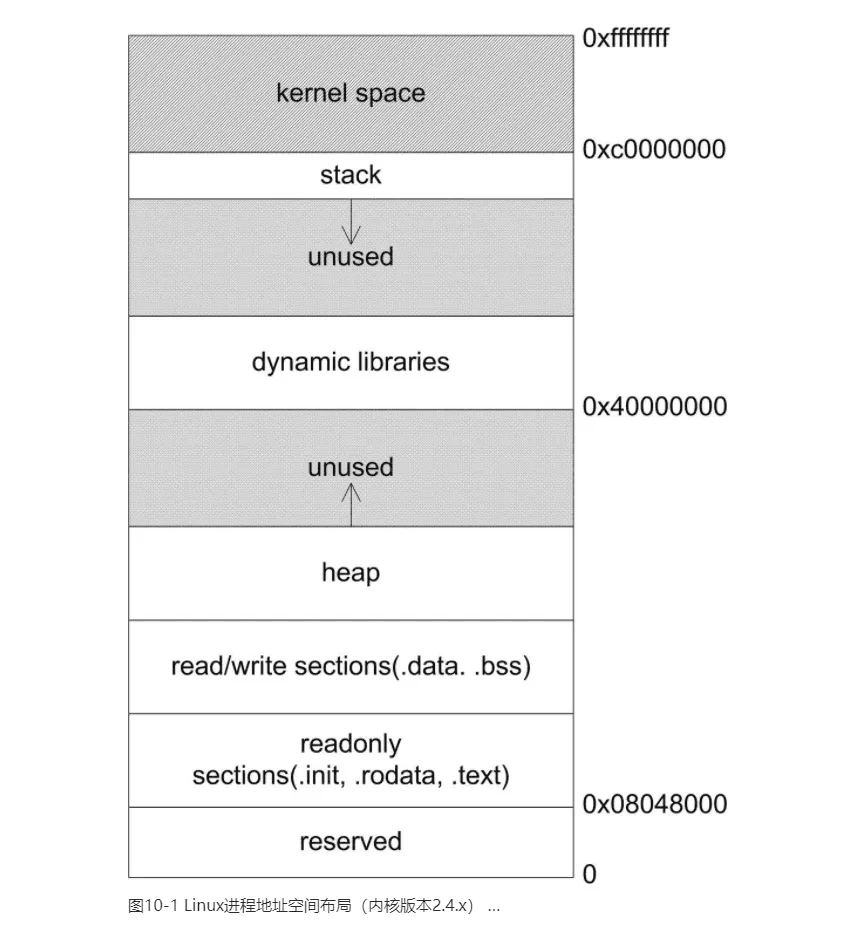
Q:我在有些书里看到说堆总是向上增长,是这样的吗?
A:不是,有些较老的书籍针对当时的系统曾做出过这样的断言,这在当时可能是正确的。因为当时的系统多是类unix系统,它们使用类似于brk的方法来分配堆空间,而brk的增长方向是向上的。但随着Windows的出现,这个规律被打破了。在Windows里,大部分堆使用HeapCreate产生,而HeapCreate系列函数却完全不遵照向上增长这个规律。
Q:调用malloc会不会最后调用到系统调用或者API?
A:这个取决于当前进程向操作系统批发的那些空间还够不够用,如果够用了,那么它可以直接在仓库里取出来卖给用户;如果不够用了,它就只能通过系统调用或者API向操作系统再进一批货了。
Q:malloc申请的内存,进程结束以后还会不会存在?
A:这是一个很常见的问题,答案是很明确的:不会存在。因为当进程结束以后,所有与进程相关的资源,包括进程的地址空间、物理内存、打开的文件、网络链接等都被操作系统关闭或者收回,所以无论malloc申请了多少内存,进程结束以后都不存在了。
Q:malloc申请的空间是不是连续的?
A:在分析这个问题之前,我们首先要分清楚“空间”这个词所指的意思。如果“空间”是指虚拟空间的话,那么答案是连续的,即每一次malloc分配后返回的空间都可以看做是一块连续的地址;如果空间是指“物理空间”的话,则答案是不一定连续,因为一块连续的虚拟地址空间有可能是若干个不连续的物理页拼凑而成的。
以上是《程序员的自我修养》第10章,内存部分摘抄。
第10章 系统级I/O
第11章 网络编程

第12章 并发编程
线程的数据共享

线程的并发与状态
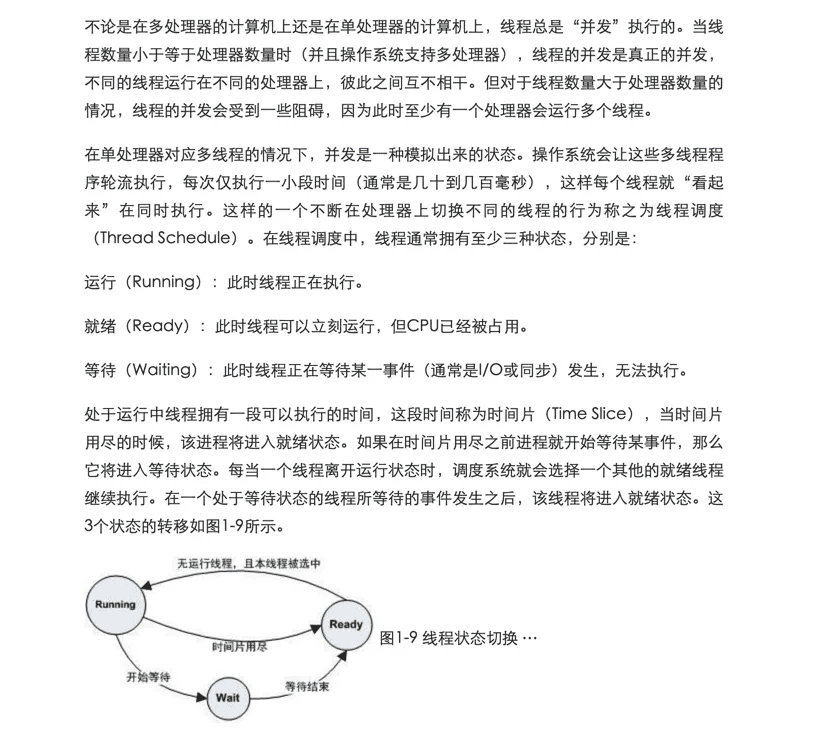
io与cpu密集型的优先级
频繁等待的线程通常只占用很少的时间,CPU也喜欢先捏软柿子。我们一般把频繁等待的线程称之为IO密集型线程(IO Bound Thread),而把很少等待的线程称为CPU密集型线程(CPU Bound Thread)。IO密集型线程总是比CPU密集型线程容易得到优先级的提升。
Linux的多线程
Windows对进程和线程的实现如同教科书一般标准,Windows内核有明确的线程和进程的概念。在Windows API中,可以使用明确的API:CreateProcess和CreateThread来创建进程和线程,并且有一系列的API来操纵它们。但对于Linux来说,线程并不是一个通用的概念。
Linux对多线程的支持颇为贫乏,事实上,在Linux内核中并不存在真正意义上的线程概念。Linux将所有的执行实体(无论是线程还是进程)都称为任务(Task),每一个任务概念上都类似于一个单线程的进程,具有内存空间、执行实体、文件资源等。不过,Linux下不同的任务之间可以选择共享内存空间,因而在实际意义上,共享了同一个内存空间的多个任务构成了一个进程,这些任务也就成了这个进程里的线程。
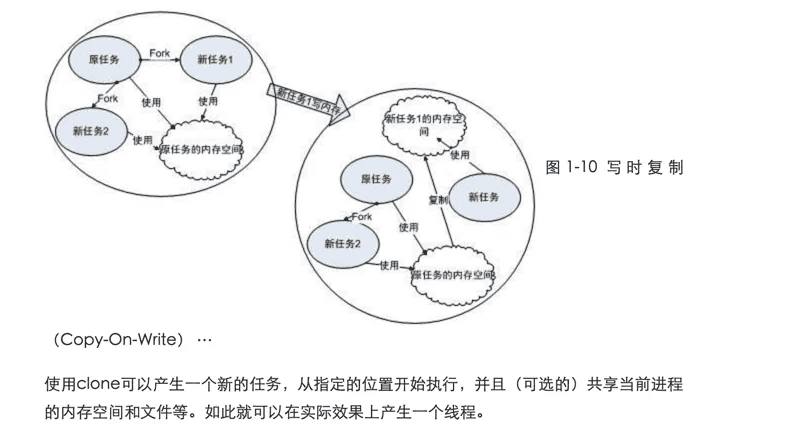
fork函数调用之后,新的任务将启动并和本任务一起从fork函数返回。但不同的是本任务的fork将返回新任务pid,而新任务的fork将返回0。
fork产生新任务的速度非常快,因为fork并不复制原任务的内存空间,而是和原任务一起共享一个写时复制(Copy on Write, COW)的内存空间(见图1-10)。所谓写时复制,指的是两个任务可以同时自由地读取内存,但任意一个任务试图对内存进行修改时,内存就会复制一份提供给修改方单独使用,以免影响到其他的任务使用。
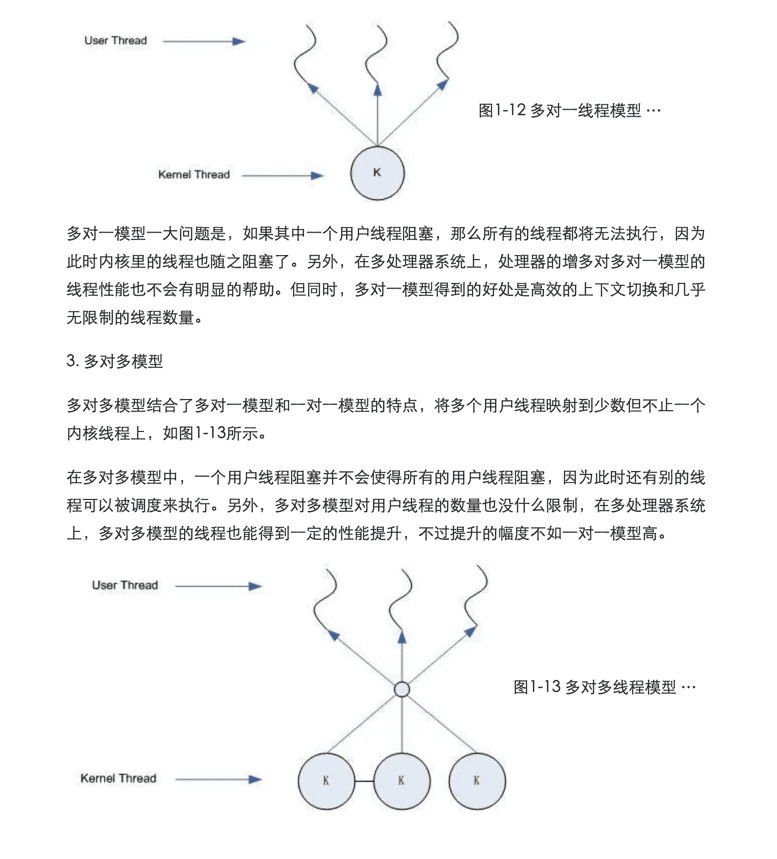
三种线程模型
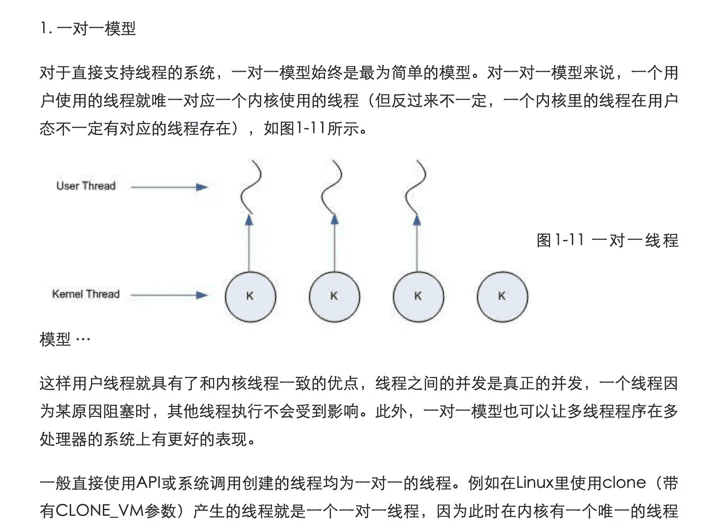
多对一模型将多个用户线程映射到一个内核线程上,线程之间的切换由用户态的代码来进行,因此相对于一对一模型,多对一模型的线程切换要快速许多。多对一的模型如图所示。
上述为《程序员的自我修养》第一章内容摘抄。