SRE与DevOps
SRE与Devops
谷歌的一名SRE出了一本书叫《SRE:Google运维解密》,通过这本书,我们知道了谷歌SRE的一些方法论:
- 运维工作50%,另外50%精力用于开发自动化工具;
- 保障服务的前提下最大化迭代速度,不追求100%可靠性;
- 通过监控预案缩短平均恢复时间MTTR;
- 部署变更管理:渐进发布,精确检测,安全回滚;
总体来说,SRE就是运维开发一体化的一套方法论,而在国内这种运维开发一体化的模式叫做Devops。
现在国内传统运维都在向Devops转,所以说SRE和传统运维相似度很高其实是没搞明白SRE是什么。
如何搭建SRE能力
好文学习:
原文链接:https://www.infoq.cn/article/vSjY7L6ykpLBlHD7RuxQ
部分摘录:业务需要哪些技术支撑能力?
运维本质是一类技术支撑能力,跟基础架构团队很像,有些活放到运维团队是可以的,放到基础架构团队问题也不大,甚至有些公司直接把这类人放到业务研发团队,我们暂且不管分工的问题,先来梳理一下业务需要什么样的技术支撑能力。
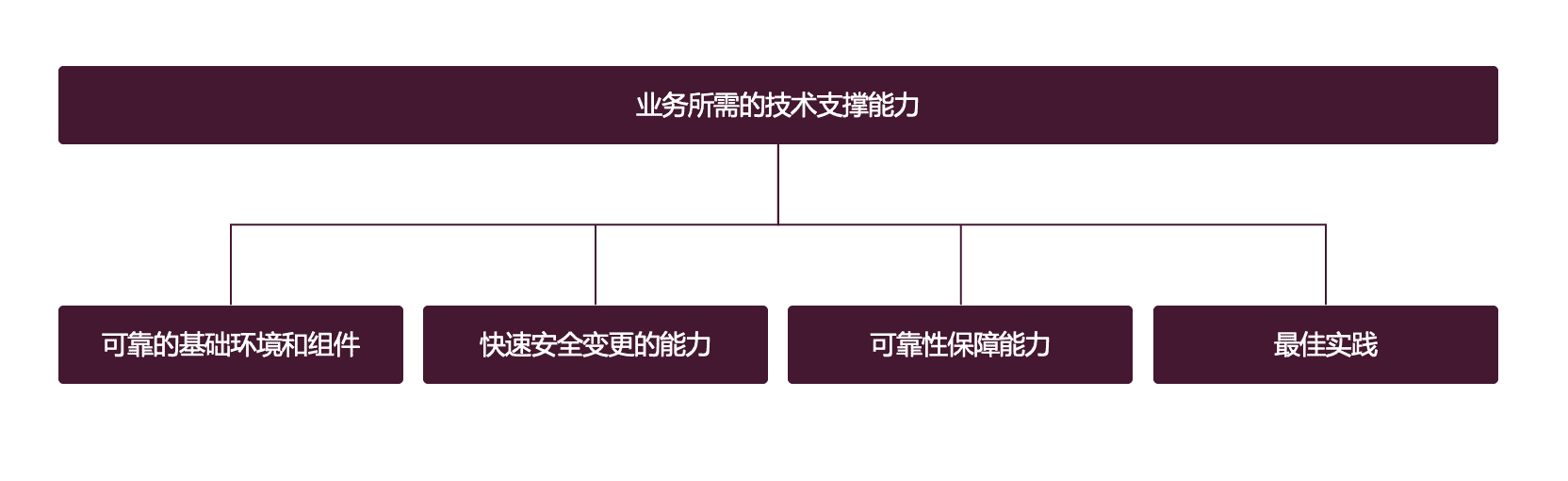
这个图其实已经很能说明问题了,我再稍微啰嗦一下:
- 可靠的基础环境和组件:业务程序要运行,需要基础网络、硬件、操作系统、数据库、中间件等,需要这些环境和组件稳定可靠
- 快速安全变更的能力:快速变更的能力,大家很容易理解,作为研发人员,写了一个 feature 或者做了个 bugfix,肯定很想快速交付,但是变更很容易导致故障,变更需要受控,需要尽量确保安全
- 可靠性保障能力:软件部署到生产环境之后,可能会遇到各类问题,如何能够提前做好风险量化,如何能快速发现问题、定位问题、快速止损,这可能是业务侧对运维侧最重要的诉求了
- 最佳实践:业务依赖很多基础支撑能力,这些能力用的如何?是不是业界最佳实践?是不是公司内其他大部分业务的最佳实践?需要基础支撑团队反哺给业务
从零设计DevOps运维服务体系
好文学习
原文链接:https://zhuanlan.zhihu.com/p/181415402
部分摘录:
运维工作一直围绕高SLA和低成本的业务目标运转着,只是工具在围绕着体系变来变去。从开发的角度理解,运维体系就像是算法,实现算法的语言就像是工具,DevOps就是工具的升级。
工具的本质其实是一个基础支撑,有了这个支撑,一系列目标的实现才更科学、高效,简单示意如下。
原始阶段,运维工程师与各部门无数的磨合、探索下,慢慢形成了最初的体系,其无形的规范着运维的工作和注意事项,工程师通过这个纲领开展日常工作并保障业务的健康发展,这个阶段可以说是制度为王、制度规范,没有系统的运维平台,有的只是零散的一些大小工具,各种事物基本靠人工、靠制度、靠约束,虽是原始阶段,但也是运维最真实的样子,忙碌而又忙碌,效率总跟不上需求,制度总跟不上执行,与开发的协作总难同一频道,需要大量的运维人力。
再向后发展,为了提高效率的同时解决与开发间的沟通协作问题,提出了DevOps,大家开始做自动化、做DevOps文化,这个自动化其本质是把运维体系落在一个到多个系统上,通过自动化系统来提高工作效率,同时用系统来实现制度,开发和运维都在一个系统上协作,遵守同样的规则,协作上也高效多了,这个阶段到了技术为王、平台规范,市场上出现了运维开发,出现了SRE,各种问题得到了有效的解决,当然解决的程度取决DevOps系统做的优劣,这个就参差不齐了,但出现了这个发展方向。
再向后发展,行业领头羊提出要进一步减少人工参与,用机器自动化替换人工自动化,进而出现了AiOps。
细心观察,从原始运维向DevOps的演进过程,就是越来越注重技术解决问题的过程,人员需要越来越少,能用技术替代的岗位慢慢被替代,随着自动化平台的成熟稳定,理论上理想的终极状态可能只留"运维平台+业务运维",其他运维转岗业务运维,业务运维转岗技术运营。
那么我们如何思考设计一套DevOps运维服务体系呢?总结下来,一个最小的模型为定业务规范、建工作制度、搭DevOps系统,以此为最小单元循环往复、迭代升级。
基于DevOps打造高效运维团队
好文学习
原文链接:http://www.uml.org.cn/devops/201812113.asp
部分摘录:
工程师文化是比较虚的东西,这里我们提出一个新的东西叫“故障文化”。
产品交付的过程当中永远高效会产生问题和故障,这时候通过这样的维度去做是可以的,我们制定了非常详细的故障管理制度,这个制度可以评估到每一个问题和故障。
每一个问题最终怎么样去提前发现问题?解决问题?在问题之后怎么样去跟进并且改进,改进有时间点、人,这套体系框住了问题之前、问题之后涉及到的人,怎么样去考核和关注。
前面说到我们会定非常详细的故障制度,故障制度其中有一个点就是评估每一个问题和故障。
怎么评估?比如说影响维度、影响时长、影响比例、影响用户数、问题所处的时间段,问题所处的产品是核心功能还是非核心功能等等,我们从五六个维度做核心评估,会有一个公式,比如说会影响什么,这个公式会对于每个问题和故障上会有一个分值,这个分值出来之后就可以评估,然后所有的东西都可以考核到团队,它是非常等量化、非常数据化的评估。
每一个问题发生的时候会有故障小组的人员跟进协调故障,在之后会形成详细的故障报告,这包含了一些要素。不要看非常简单,实际上它的体系非常丰富,它涵盖的面都有。
这里还有一些实际的问题,比如说每个产品评估标准是不是不一样?这里也做了通用评估和自定义评估,通用评估提到了通用维度的评估,还有些产品把金钱的维度纳入了进来。
所以我们在越来越细的过程中,也会深入每个产品,每个产品都会制定自己的故障评估制度,这个故障之后会有公式,公式计算出分值,所以这套体系制度非常重要,A级故障、B级故障、C级故障多少个,再做月报、半年报的分析。
这是故障制度里的东西,我们强调的是故障文化,你出问题不用怕,这时候你监控层面做的比较好的话,能提前监控和解决也是OK的。
故障文化我们通过培训来做,你不用害怕,该发生的问题发生也OK,我们更多强调后面如何改进,比如说这个故障发生了就列出来三个部门要改进什么样的东西,随着改进越来越多,整个服务的体系以及稳定性会得到极大的提升,这整体收益是非常大的,一方面有有效的制度,一方面有故障文化。