网络性能-基础优化
极客时间《Linux性能优化实战》倪朋飞 学习笔记
网络综述与网络分层
由于网络处理的流程最复杂,跟我们前面讲到的进程调度、中断处理、内存管理以及 I/O 等都密不可分,所以,我把网络模块作为最后一个资源模块来讲解。
同 CPU、内存以及 I/O 一样,网络也是 Linux 系统最核心的功能。网络是一种把不同计算机或网络设备连接到一起的技术,它本质上是一种进程间通信方式,特别是跨系统的进程间通信,必须要通过网络才能进行。随着高并发、分布式、云计算、微服务等技术的普及,网络的性能也变得越来越重要。
网络问题比我们前面学过的 CPU、内存或磁盘 I/O 都要复杂。无论是应用层的各种 I/O 模型,冗长的网络协议栈和众多的内核选项,抑或是各种复杂的网络环境,都提高了网络的复杂性。
不过,也不要过分担心,只要你掌握了 Linux 网络的基本原理和常见网络协议的工作流程,再结合各个网络层的性能指标来分析,你会发现,定位网络瓶颈并不难。
找到网络性能瓶颈后,下一步要做的就是优化了,也就是如何降低网络延迟,并提高网络的吞吐量。学完相关原理和案例后,我就来讲讲,优化网络性能问题的思路和一些注意事项。
国际标准化组织制定的开放式系统互联通信参考模型(Open System Interconnection Reference Model),简称为 OSI 网络模型。
为了解决网络互联中异构设备的兼容性问题,并解耦复杂的网络包处理流程,OSI 模型把网络互联的框架分为应用层、表示层、会话层、传输层、网络层、数据链路层以及物理层等七层,每个层负责不同的功能。其中,
- 应用层,负责为应用程序提供统一的接口。
- 表示层,负责把数据转换成兼容接收系统的格式。
- 会话层,负责维护计算机之间的通信连接。
- 传输层,负责为数据加上传输表头,形成数据包。
- 网络层,负责数据的路由和转发。
- 数据链路层,负责 MAC 寻址、错误侦测和改错。
- 物理层,负责在物理网络中传输数据帧。
但是 OSI 模型还是太复杂了,也没能提供一个可实现的方法。所以,在 Linux 中,我们实际上使用的是另一个更实用的四层模型,即 TCP/IP 网络模型。
TCP/IP 模型,把网络互联的框架分为应用层、传输层、网络层、网络接口层等四层,其中,
- 应用层,负责向用户提供一组应用程序,比如 HTTP、FTP、DNS 等。
- 传输层,负责端到端的通信,比如 TCP、UDP 等。
- 网络层,负责网络包的封装、寻址和路由,比如 IP、ICMP 等。
- 网络接口层,负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。
为了帮你更形象理解 TCP/IP 与 OSI 模型的关系,我画了一张图,如下所示:
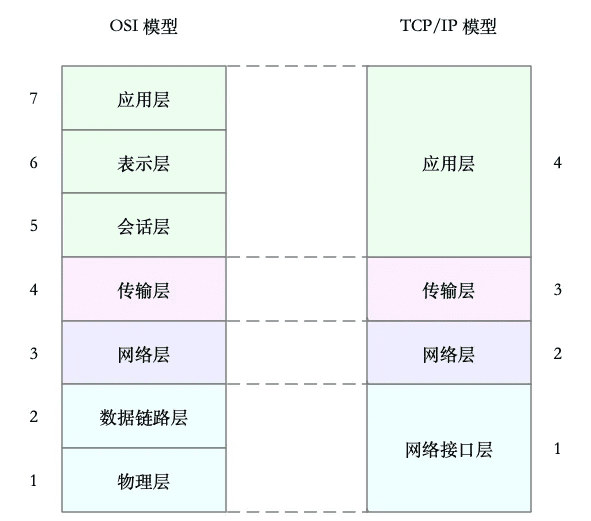
虽说 Linux 实际按照 TCP/IP 模型,实现了网络协议栈,但在平时的学习交流中,我们习惯上还是用 OSI 七层模型来描述。比如,说到七层和四层负载均衡,对应的分别是 OSI 模型中的应用层和传输层(而它们对应到 TCP/IP 模型中,实际上是四层和三层)。
TCP/IP 模型包括了大量的网络协议,这些协议的原理,也是我们每个人必须掌握的核心基础知识。如果你不太熟练,推荐你去学《TCP/IP 详解》的卷一和卷二,或者学习极客时间出品的《趣谈网络协议》专栏。
应用程序数据在tcp/ip各层封装
以通过 TCP 协议通信的网络包为例,通过下面这张图,我们可以看到,应用程序数据在每个层的封装格式。
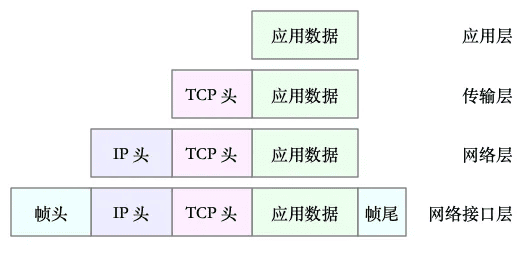
其中:
- 传输层在应用程序数据前面增加了 TCP 头;
- 网络层在 TCP 数据包前增加了 IP 头;
- 而网络接口层,又在 IP 数据包前后分别增加了帧头和帧尾。
这些新增的头部和尾部,都按照特定的协议格式填充,想了解具体格式,你可以查看协议的文档。
这些新增的头部和尾部,增加了网络包的大小,但我们都知道,物理链路中并不能传输任意大小的数据包。网络接口配置的最大传输单元(MTU),就规定了最大的 IP 包大小。在我们最常用的以太网中,MTU 默认值是 1500(这也是 Linux 的默认值)。
一旦网络包超过 MTU 的大小,就会在网络层分片,以保证分片后的 IP 包不大于 MTU 值。显然,MTU 越大,需要的分包也就越少,自然,网络吞吐能力就越好。
理解了 TCP/IP 网络模型和网络包的封装原理后,你很容易能想到,Linux 内核中的网络栈,其实也类似于 TCP/IP 的四层结构。如下图所示,就是 Linux 通用 IP 网络栈的示意图:
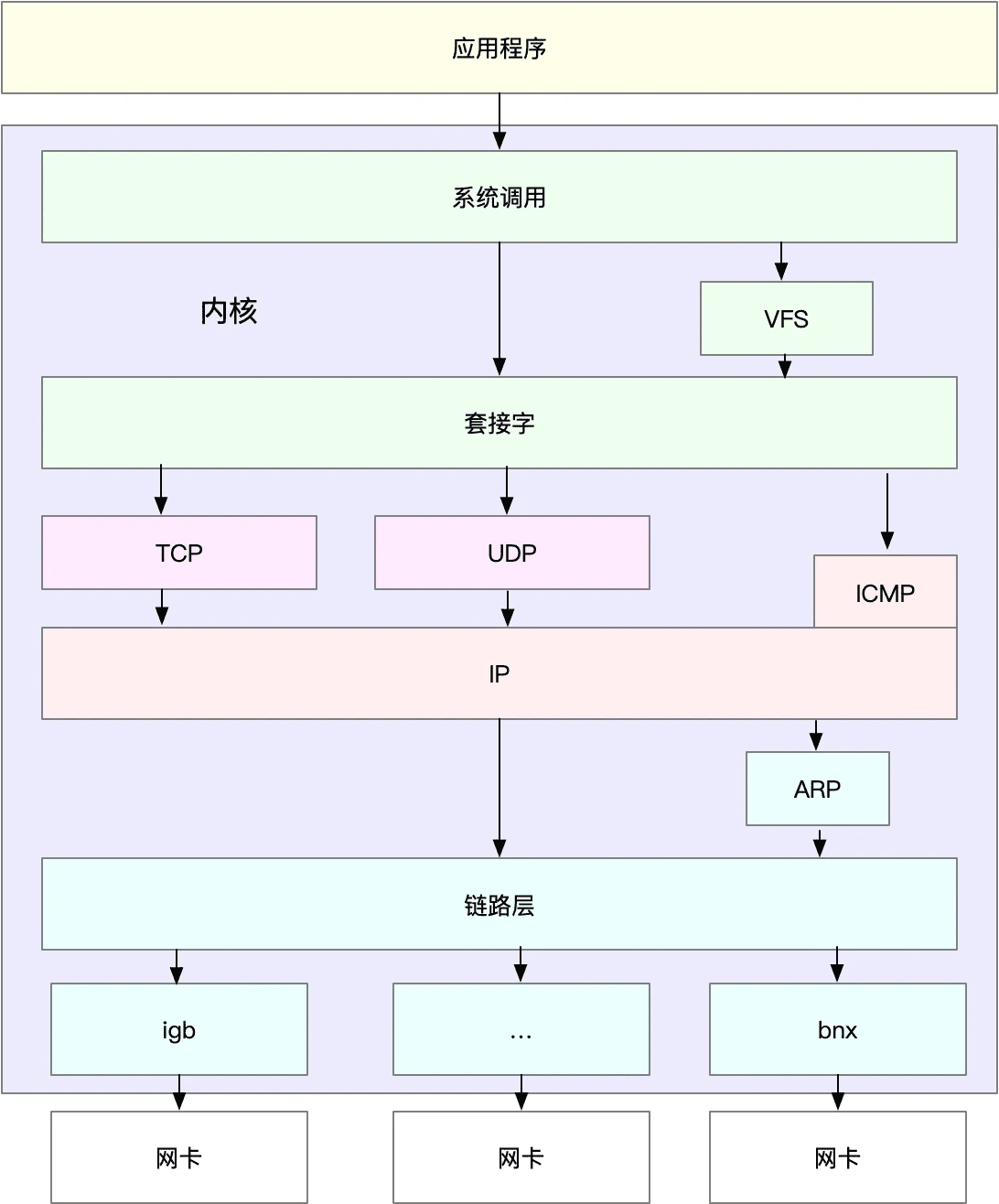 (图片参考《性能之巅》图 10.7 通用 IP 网络栈绘制)
(图片参考《性能之巅》图 10.7 通用 IP 网络栈绘制)
我们从上到下来看这个网络栈,你可以发现,
- 最上层的应用程序,需要通过系统调用,来跟套接字接口进行交互;
- 套接字的下面,就是我们前面提到的传输层、网络层和网络接口层;
- 最底层,则是网卡驱动程序以及物理网卡设备。
这里我简单说一下网卡。网卡是发送和接收网络包的基本设备。在系统启动过程中,网卡通过内核中的网卡驱动程序注册到系统中。而在网络收发过程中,内核通过中断跟网卡进行交互。
再结合前面提到的 Linux 网络栈,可以看出,网络包的处理非常复杂。所以,网卡硬中断只处理最核心的网卡数据读取或发送,而协议栈中的大部分逻辑,都会放到软中断中处理。
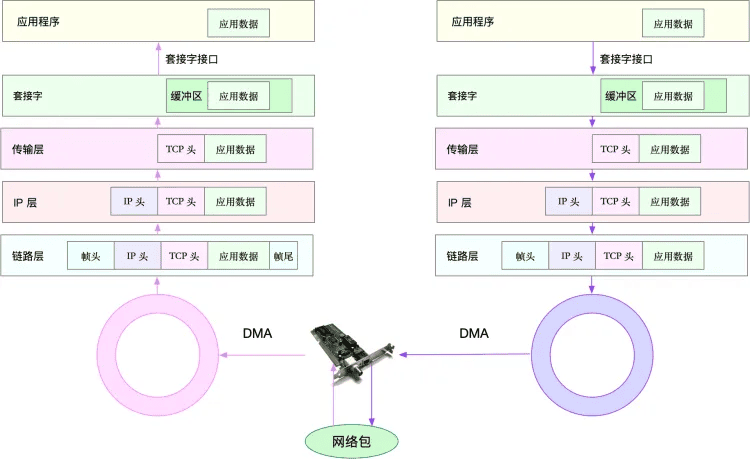
Linux网络收发过程
当一个网络帧到达网卡后,网卡会通过 DMA 方式,把这个网络包放到收包队列中;然后通过硬中断,告诉中断处理程序已经收到了网络包。 接着,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到 sk_buff 缓冲区中;然后再通过软中断,通知内核收到了新的网络帧。 接下来,内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧。比如,
- 在链路层检查报文的合法性,找出上层协议的类型(比如 IPv4 还是 IPv6),再去掉帧头、帧尾,然后交给网络层。
- 网络层取出 IP 头,判断网络包下一步的走向,比如是交给上层处理还是转发。当网络层确认这个包是要发送到本机后,就会取出上层协议的类型(比如 TCP 还是 UDP),去掉 IP 头,再交给传输层处理。
- 传输层取出 TCP 头或者 UDP 头后,根据 < 源 IP、源端口、目的 IP、目的端口 > 四元组作为标识,找出对应的 Socket,并把数据拷贝到 Socket 的接收缓存中。
- 最后,应用程序就可以使用 Socket 接口,读取到新接收到的数据了。
为了更清晰表示这个流程,我画了一张图,这张图的左半部分表示接收流程,而图中的粉色箭头则表示网络包的处理路径。
Linux网络发送过程
了解网络包的接收流程后,就很容易理解网络包的发送流程。网络包的发送流程就是上图的右半部分,很容易发现,网络包的发送方向,正好跟接收方向相反。
首先,应用程序调用 Socket API(比如 sendmsg)发送网络包。
由于这是一个系统调用,所以会陷入到内核态的套接字层中。套接字层会把数据包放到 Socket 发送缓冲区中。
接下来,网络协议栈从 Socket 发送缓冲区中,取出数据包;再按照 TCP/IP 栈,从上到下逐层处理。比如,传输层和网络层,分别为其增加 TCP 头和 IP 头,执行路由查找确认下一跳的 IP,并按照 MTU 大小进行分片。
分片后的网络包,再送到网络接口层,进行物理地址寻址,以找到下一跳的 MAC 地址。然后添加帧头和帧尾,放到发包队列中。这一切完成后,会有软中断通知驱动程序:发包队列中有新的网络帧需要发送。
最后,驱动程序通过 DMA ,从发包队列中读出网络帧,并通过物理网卡把它发送出去。
问题:网络收发过程中,缓冲区位置在哪里?
第一点,是网络收发过程中,收发队列和缓冲区位置的疑问。
在 关于 Linux 网络,你必须要知道这些 中,我曾介绍过 Linux 网络的收发流程。这个流程涉及到了多个队列和缓冲区,包括:
- 网卡收发网络包时,通过 DMA 方式交互的环形缓冲区;
- 网卡中断处理程序为网络帧分配的,内核数据结构 sk_buff 缓冲区;
- 应用程序通过套接字接口,与网络协议栈交互时的套接字缓冲区。
不过相应的,就会有两个问题。
首先,这些缓冲区的位置在哪儿?是在网卡硬件中,还是在内存中?这个问题其实仔细想一下,就很容易明白——这些缓冲区都处于内核管理的内存中。
其中,环形缓冲区,由于需要 DMA 与网卡交互,理应属于网卡设备驱动的范围。
sk_buff 缓冲区,是一个维护网络帧结构的双向链表,链表中的每一个元素都是一个网络帧(Packet)。虽然 TCP/IP 协议栈分了好几层,但上下不同层之间的传递,实际上只需要操作这个数据结构中的指针,而无需进行数据复制。
套接字缓冲区,则允许应用程序,给每个套接字配置不同大小的接收或发送缓冲区。应用程序发送数据,实际上就是将数据写入缓冲区;而接收数据,其实就是从缓冲区中读取。至于缓冲区中数据的进一步处理,则由传输层的 TCP 或 UDP 协议来完成。
其次,这些缓冲区,跟前面内存部分讲到的 Buffer 和 Cache 有什么关联吗?
这个问题其实也不难回答。我在内存模块曾提到过,内存中提到的 Buffer ,都跟块设备直接相关;而其他的都是 Cache。
实际上,sk_buff、套接字缓冲、连接跟踪等,都通过 slab 分配器来管理。你可以直接通过 /proc/slabinfo,来查看它们占用的内存大小。
问题:内核协议栈的运行,是按照一个内核线程的方式吗?在内核中,又是如何执行网络协议栈的呢?
说到网络收发,在中断处理文章中我曾讲过,其中的软中断处理,就有专门的内核线程 ksoftirqd。每个 CPU 都会绑定一个 ksoftirqd 内核线程,比如, 2 个 CPU 时,就会有 ksoftirqd/0 和 ksoftirqd/1 这两个内核线程。
不过要注意,并非所有网络功能,都在软中断内核线程中处理。内核中还有很多其他机制(比如硬中断、kworker、slab 等),这些机制一起协同工作,才能保证整个网络协议栈的正常运行。
关于内核中网络协议栈的工作原理,以及如何动态跟踪内核的执行流程,专栏后续还有专门的文章来讲。如果对这部分感兴趣,你可以先用我们提到过的 perf、systemtap、bcc-tools 等,试着来分析一下。
网络性能指标综述
实际上,我们通常用带宽、吞吐量、延时、PPS(Packet Per Second)等指标衡量网络的性能。
- 带宽,表示链路的最大传输速率,单位通常为 b/s (比特 / 秒)。
- 吞吐量,表示单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者 B/s(字节 / 秒)。吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率。
- 延时(平时也挺多人叫时延、延迟,都是指这个意思),表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT,这个理解更加普适)。
- PPS,是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。(交换机通常不会受到太大影响,即交换机可以线性转发)
除了这些指标,网络的可用性(网络能否正常通信)、并发连接数(TCP 连接数量)、丢包率(丢包百分比)、重传率(重新传输的网络包比例)等也是常用的性能指标。
备注:在其他很多资料种,一般衡量网络性能的四大指标:带宽、时延、抖动、丢包。
比如,可以参考这篇文章的理解:https://www.cnblogs.com/kukuxjx/p/17439357.html
查看系统当前的网络参数,有不少工具,ip/ifconfig(网络配置等),ss/netstat(套接字与协议栈统计等) 这两个参考另外的笔记说明。
如何查看系统当前的网络吞吐量和 PPS。在这里,我推荐使用我们的老朋友 sar,在前面的 CPU、内存和 I/O 模块中,我们已经多次用到它。
给 sar 增加 -n 参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP 等等。执行下面的命令,你就可以得到网络接口统计信息:
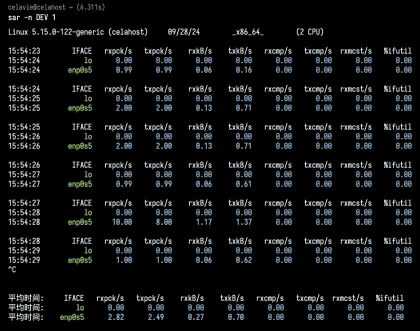
这儿输出的指标比较多,我来简单解释下它们的含义。
- rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
- rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
- %ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth。
其中,Bandwidth 可以用 ethtool 来查询,它的单位通常是 Gb/s 或者 Mb/s,不过注意这里小写字母 b ,表示比特而不是字节。我们通常提到的千兆网卡、万兆网卡等,单位也都是比特。如下你可以看到,我的 eth0 网卡就是一个千兆网卡:

注意:在虚拟机里可能没有这个数据。
简单的网络连通性和延时,可以用ping测试:
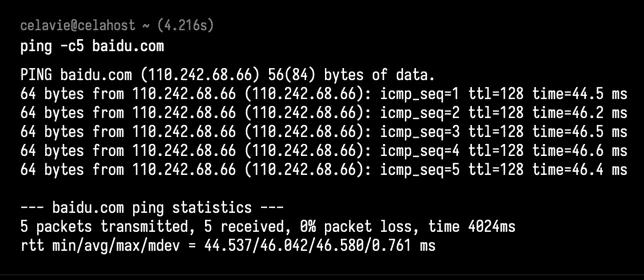
-c5 表示发送5次 ICMP 包后停止。
ping 的输出,可以分为两部分。
- 第一部分,是每个 ICMP 请求的信息,包括 ICMP 序列号(icmp_seq)、TTL(生存时间,或者跳数)以及往返延时。
- 第二部分,则是三次 ICMP 请求的汇总。
通常,我们更常用的是双向的往返通信延迟,比如 ping 测试的结果,就是往返延时 RTT(Round-Trip Time)。
除了网络延迟外,另一个常用的指标是应用程序延迟,它是指,从应用程序接收到请求,再到发回响应,全程所用的时间。通常,应用程序延迟也指的是往返延迟,是网络数据传输时间加上数据处理时间的和。
所以,我们平时要注意对延迟的定义和解释、实现。
上面介绍到,你可以用 ping 来测试网络延迟。ping 基于 ICMP 协议,它通过计算 ICMP 回显响应报文与 ICMP 回显请求报文的时间差,来获得往返延时。这个过程并不需要特殊认证,常被很多网络攻击利用,比如端口扫描工具 nmap、组包工具 hping3 等等。
所以,为了避免这些问题,很多网络服务会把 ICMP 禁止掉,这也就导致我们无法用 ping ,来测试网络服务的可用性和往返延时。这时,你可以用 traceroute 或 hping3 的 TCP 和 UDP 模式,来获取网络延迟。
比如,以 baidu.com 为例,你可以执行下面的 hping3 命令,测试你的机器到百度搜索服务器的网络延迟:
-c 表示发送 3 次请求,-S 表示设置 TCP SYN,-p 表示端口号为 80
hping3 -c 3 -S -p 80 baidu.com当然,我们用 traceroute ,也可以得到类似结果:
--tcp 表示使用 TCP 协议,-p 表示端口号,-n 表示不对结果中的 IP 地址执行反向域名解析
$ traceroute --tcp -p 80 -n baidu.comtraceroute 会在路由的每一跳发送三个包,并在收到响应后,输出往返延时。如果无响应或者响应超时(默认 5s),就会输出一个星号。一般tcp会被禁止,使用icmp好点,在单独的笔记里有记录。
网络延迟,是最核心的网络性能指标。由于网络传输、网络包处理等各种因素的影响,网络延迟不可避免。但过大的网络延迟,会直接影响用户的体验。
所以,在发现网络延迟增大后,你可以用 traceroute、hping3、tcpdump、Wireshark、strace 等多种工具,来定位网络中的潜在问题。比如,
- 使用 hping3 以及 wrk 等工具,确认单次请求和并发请求情况的网络延迟是否正常。
- 使用 traceroute,确认路由是否正确,并查看路由中每一跳网关的延迟。
- 使用 tcpdump 和 Wireshark,确认网络包的收发是否正常。
- 使用 strace 等,观察应用程序对网络套接字的调用情况是否正常。
这样,你就可以依次从路由、网络包的收发、再到应用程序等,逐层排查,直到定位问题根源。
评估网络性能
带宽、吞吐量、延时、PPS,这四个指标中,带宽跟物理网卡配置是直接关联的。一般来说,网卡确定后,带宽也就确定 了(当然,实际带宽会受限于整个网络链路中最小的那个模块)。
另外,你可能在很多地方听说过“网络带宽测试”,这里测试的实际上不是带宽,而是网络吞吐量。Linux 服务器的网络吞吐量一般会比带宽小,而对交换机等专门的网络设备来说,吞吐量一般会接近带宽。
最后的 PPS,则是以网络包为单位的网络传输速率,通常用在需要大量转发的场景中。而对 TCP 或者 Web 服务来说,更多会用并发连接数和每秒请求数(QPS,Query per Second)等指标,它们更能反应实际应用程序的性能。
网络基准测试
基于 HTTP 或者 HTTPS 的 Web 应用程序,显然属于应用层,需要我们测试 HTTP/HTTPS 的性能;
而对大多数游戏服务器来说,为了支持更大的同时在线人数,通常会基于 TCP 或 UDP ,与客户端进行交互,这时就需要我们测试 TCP/UDP 的性能;
当然,还有一些场景,是把 Linux 作为一个软交换机或者路由器来用的。这种情况下, 你更关注网络包的处理能力(即 PPS),重点关注网络层的转发性能。
接下来,我就带你从下往上,了解不同协议层的网络性能测试方法。不过要注意,低层协议 是其上的各层网络协议的基础。自然,低层协议的性能,也就决定了高层的网络性能。
各协议层的性能测试
转发性能
我们首先来看,网络接口层和网络层,它们主要负责网络包的封装、寻址、路由以及发送和接收。在这两个网络协议层中,每秒可处理的网络包数 PPS,就是最重要的性能指标。
说到网络包相关的测试,你可能会觉得陌生。不过,其实在专栏开头的 CPU 性能篇中,我们就接触过一个相关工具,也就是软中断案例中的 hping3。在那个案例中,hping3 作为一个 SYN 攻击的工具来使用。实际上, hping3 更多的用途,是作为一个测试网络包处理能力的性能工具。
今天我再来介绍另一个更常用的工具,Linux 内核自带的高性能网络测试工具 pktgen。pktgen 支持丰富的自定义选项,方便你根据实际需要构造所需网络包,从而更准确地测试出目标服务器的性能。
Linux 内核自带的高性能网络测试工具 pktgen。 pktgen 支持丰富的自定义选项,方便你根据实际需要构造所需网络包,从而更准确地测试 出目标服务器的性能。
不过,在 Linux 系统中,你并不能直接找到 pktgen 命令。因为 pktgen 作为一个内核线程来运行,需要你加载 pktgen 内核模块后,再通过 /proc 文件系统来交互。
不常用,这里直接略过测试环节。
根据上面的结果,我们发现,测试PPS 为 12 万,吞吐量为 61 Mb/s,没有发生错误。那么, 12 万的 PPS 好不好呢? 作为对比,你可以计算一下千兆交换机的 PPS。交换机可以达到线速(满负载时,无差错转发),它的 PPS 就是 1000Mbit 除以以太网帧的大小,即 1000Mbps/((64+20)*8bit) = 1.5 Mpps(其中,20B 为以太网帧前导和帧间距的大小)。
你看,即使是千兆交换机的 PPS,也可以达到 150 万 PPS,比我们测试得到的 12 万大多了。所以,看到这个数值你并不用担心,现在的多核服务器和万兆网卡已经很普遍了,稍做优化就可以达到数百万的 PPS。而且,如果你用了上节课讲到的 DPDK 或 XDP ,还能达到千万数量级。
TCP/UDP 性能
掌握了 PPS 的测试方法,接下来,我们再来看 TCP 和 UDP 的性能测试方法。说到 TCP 和 UDP 的测试,我想你已经很熟悉了,甚至可能一下子就能想到相应的测试工具,比如 iperf 或者 netperf。
特别是现在的云计算时代,在你刚拿到一批虚拟机时,首先要做的,应该就是用 iperf ,测 试一下网络性能是否符合预期。
iperf 和 netperf 都是最常用的网络性能测试工具,测试 TCP 和 UDP 的吞吐量。它们都以客户端和服务器通信的方式,测试一段时间内的平均吞吐量。
接下来,我们就以 iperf 为例,看一下 TCP 性能的测试方法。目前,iperf 的最新版本为 iperf3,你可以运行下面的命令来安装:
# Ubuntu
apt-get install iperf3
# CentOS
yum install iperf3
# macos
brew install iperf3然后,在目标机器上启动 iperf 服务端:
# -s 表示启动服务端,-i 表示汇报间隔,-p 表示监听端口 2
iperf3 -s -i 1 -p 10000

客户端命令:
iperf3 -c 192.168.3.13 -b 1G -t 15 pP2 -p 10000最后的 SUM 行就是测试的汇总结果,包括测试时间、数据传输量以及带宽等。按照发送和接收,这一部分又分为了 sender 和 receiver 两行。
从测试结果你可以看到,这台机器 TCP 接收的带宽(吞吐量)为 860 Mb/s, 跟目标的 1Gb/s 相比,还是有些差距的。(实际上,在虚拟机里面,可能会更差。如下图)
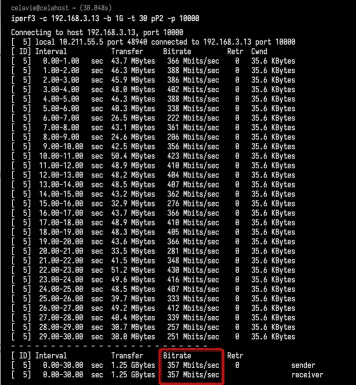
关于iperf3的更多用法,可以参考:
HTTP 性能简单测试
从传输层再往上,到了应用层。有的应用程序,会直接基于 TCP 或 UDP 构建服务。当 然,也有大量的应用,基于应用层的协议来构建服务,HTTP 就是最常用的一个应用层协议。比如,常用的 Apache、Nginx 等各种 Web 服务,都是基于 HTTP。
要测试 HTTP 的性能,也有大量的工具可以使用,比如 ab、webbench 等,都是常用的 HTTP 压力测试工具。其中,ab 是 Apache 自带的 HTTP 压测工具,主要测试 HTTP 服务的每秒请求数、请求延迟、吞吐量以及请求延迟的分布情况等。
运行下面的命令,你就可以安装 ab 工具:
apt-get install -y apache2-utils
yum install -y httpd-tools更好的,还是建议使用wrk和bombardier这两个。具体见单独的笔记。
应用负载性能
当你用 iperf 或者 ab 等测试工具,得到 TCP、HTTP 等的性能数据后,这些数据是否就能表示应用程序的实际性能呢?我想,你的答案应该是否定的。
比如,你的应用程序基于 HTTP 协议,为最终用户提供一个 Web 服务。这时,使用 ab 工具,可以得到某个页面的访问性能,但这个结果跟用户的实际请求,很可能不一致。因为用户请求往往会附带着各种各种的负载(payload),而这些负载会影响 Web 应用程序内部的处理逻辑,从而影响最终性能。
那么,为了得到应用程序的实际性能,就要求性能工具本身可以模拟用户的请求负载,而 iperf、ab 这类工具就无能为力了。幸运的是,我们还可以用 wrk、TCPCopy、Jmeter 或 者 LoadRunner 等实现这个目标。
以 wrk 为例,它是一个 HTTP 性能测试工具,内置了 LuaJIT,方便你根据实际需求,生成所需的请求负载,或者自定义响应的处理方法。
wrk 工具本身不提供 yum 或 apt 的安装方法,需要通过源码编译来安装。比如,你可以运 行下面的命令,来编译和安装 wrk:

wrk 的命令行参数比较简单。比如,我们可以用 wrk ,来重新测一下前面已经启动的 Nginx 的性能。

这里使用 2 个线程、并发 1000 连接,重新测试了 Nginx 的性能。你可以看到,每秒请求数为 9641,吞吐量为 7.82MB,平均延迟为 65ms,比前面 ab 的测试结果要好很多。
这也说明,性能工具本身的性能,对性能测试也是至关重要的。不合适的性能工具,并不能准确测出应用程序的最佳性能。
当然,wrk 最大的优势,是其内置的 LuaJIT,可以用来实现复杂场景的性能测试。wrk 在调用 Lua 脚本时,可以将 HTTP 请求分为三个阶段,即 setup、running、done,如下图所示:
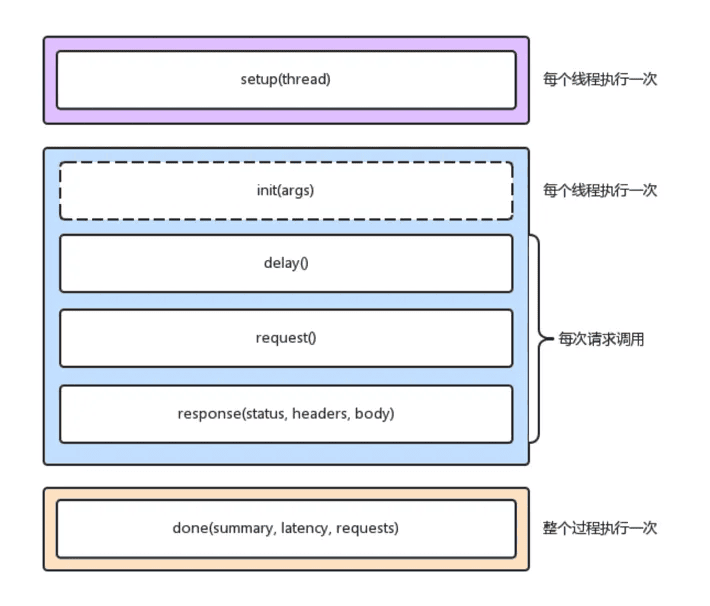
wrk 可以使用 Lua 脚本,来构造请求负载。这对于大部分场景来说,可能已经足够了 。不过,它的缺点也正是,所有东西都需要代码来构造,并且工具本身不提供 GUI 环境。
像 Jmeter 或者 LoadRunner(商业产品),则针对复杂场景提供了脚本录制、回放、GUI 等更丰富的功能,使用起来也更加方便。
综上,成本最低的,功能最强大的应用负载性能测试,是Jmeter。需要另外学习,另做笔记。
确定优化目标
性能评估是优化网络性能的前提,只有在你发现网络性能瓶颈时,才需要进行网络性能优化。根据 TCP/IP 协议栈的原理,不同协议层关注的性能重点不完全一样,也就对应不同的性能测试方法。比如,
- 在应用层,你可以使用 wrk、Jmeter 等模拟用户的负载,测试应用程序的每秒请求数、处理延迟、错误数等;
- 而在传输层,则可以使用 iperf 等工具,测试 TCP 的吞吐情况;
- 再向下,你还可以用 Linux 内核自带的 pktgen ,测试服务器的 PPS。
跟 CPU 和 I/O 方面的性能优化一样,优化前,我会先问问自己,网络性能优化的目标是什么?换句话说,我们观察到的网络性能指标,要达到多少才合适呢?
实际上,虽然网络性能优化的整体目标,是降低网络延迟(如 RTT)和提高吞吐量(如 BPS 和 PPS),但具体到不同应用中,每个指标的优化标准可能会不同,优先级顺序也大相径庭。
就拿上一节提到的 NAT 网关来说,由于其直接影响整个数据中心的网络出入性能,所以 NAT 网关通常需要达到或接近线性转发,也就是说, PPS 是最主要的性能目标。
再如,对于数据库、缓存等系统,快速完成网络收发,即低延迟,是主要的性能目标。
而对于我们经常访问的 Web 服务来说,则需要同时兼顾吞吐量和延迟。
所以,为了更客观合理地评估优化效果,我们首先应该明确优化的标准,即要对系统和应用程序进行基准测试,得到网络协议栈各层的基准性能。
在怎么评估系统的网络性能中,我已经介绍过,网络性能测试的方法。简单回顾一下,Linux 网络协议栈,是我们需要掌握的核心原理。它是基于 TCP/IP 协议族的分层结构,我用一张图来表示这个结构。
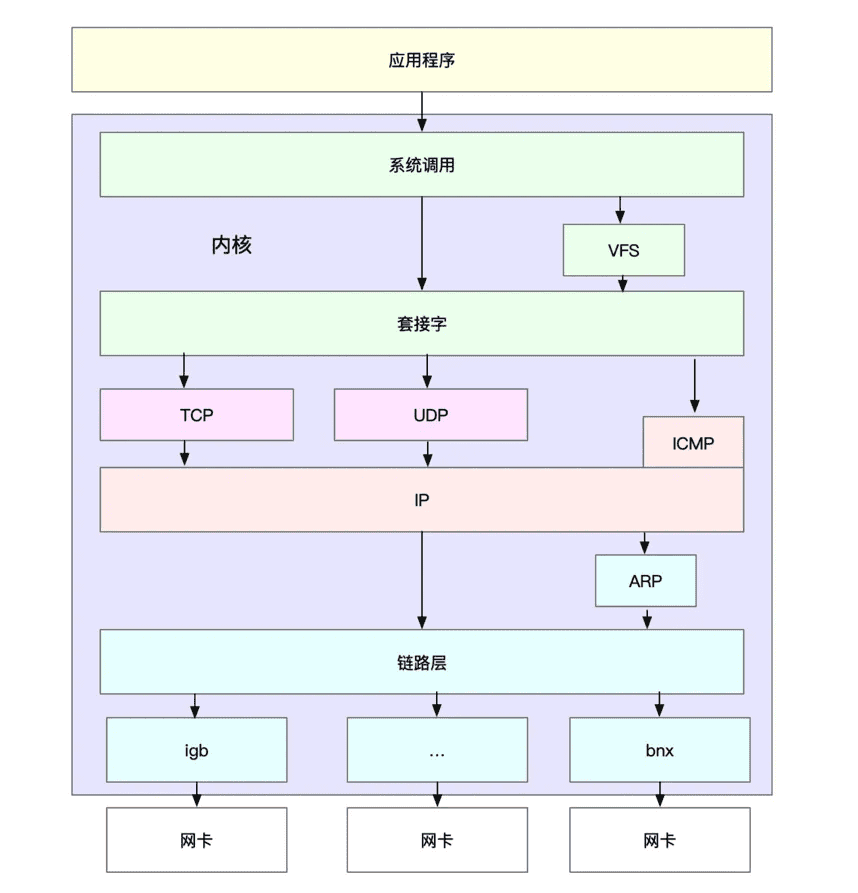
明白了这一点,在进行基准测试时,我们就可以按照协议栈的每一层来测试。由于底层是其上方各层的基础,底层性能也就决定了高层性能。所以我们要清楚,底层性能指标,其实就是对应高层的极限性能。我们从下到上来理解这一点。
首先是网络接口层和网络层,它们主要负责网络包的封装、寻址、路由,以及发送和接收。每秒可处理的网络包数 PPS,就是它们最重要的性能指标(特别是在小包的情况下)。你可以用内核自带的发包工具 pktgen ,来测试 PPS 的性能。
再向上到传输层的 TCP 和 UDP,它们主要负责网络传输。对它们而言,吞吐量(BPS)、连接数以及延迟,就是最重要的性能指标。你可以用 iperf 或 netperf ,来测试传输层的性能。
不过要注意,网络包的大小,会直接影响这些指标的值。所以,通常,你需要测试一系列不同大小网络包的性能。
最后,再往上到了应用层,最需要关注的是吞吐量(BPS)、每秒请求数以及延迟等指标。你可以用 wrk、ab 等工具,来测试应用程序的性能。
不过,这里要注意的是,测试场景要尽量模拟生产环境,这样的测试才更有价值。比如,你可以到生产环境中,录制实际的请求情况,再到测试中回放。
总之,根据这些基准指标,再结合已经观察到的性能瓶颈,我们就可以明确性能优化的目标。
网络性能工具
同前面学习一样,我建议从指标和工具两个不同维度出发,整理记忆网络相关的性能工具。
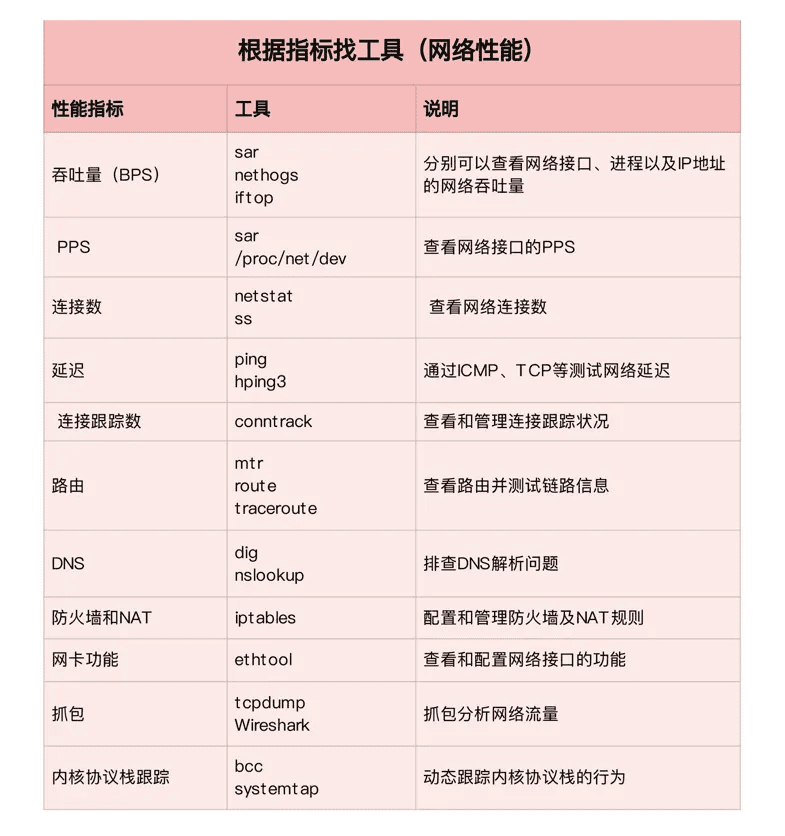
第一个维度,从网络性能指标出发,你更容易把性能工具同系统工作原理关联起来,对性能问题有宏观的认识和把握。这样,当你想查看某个性能指标时,就能清楚知道,可以用哪些工具。
这里,我把提供网络性能指标的工具,做成了一个表格,方便你梳理关系和理解记忆。你可以把它保存并打印出来,随时查看。当然,你也可以把它当成一个“指标工具”指南来使用。
根据性能指标查找工具:
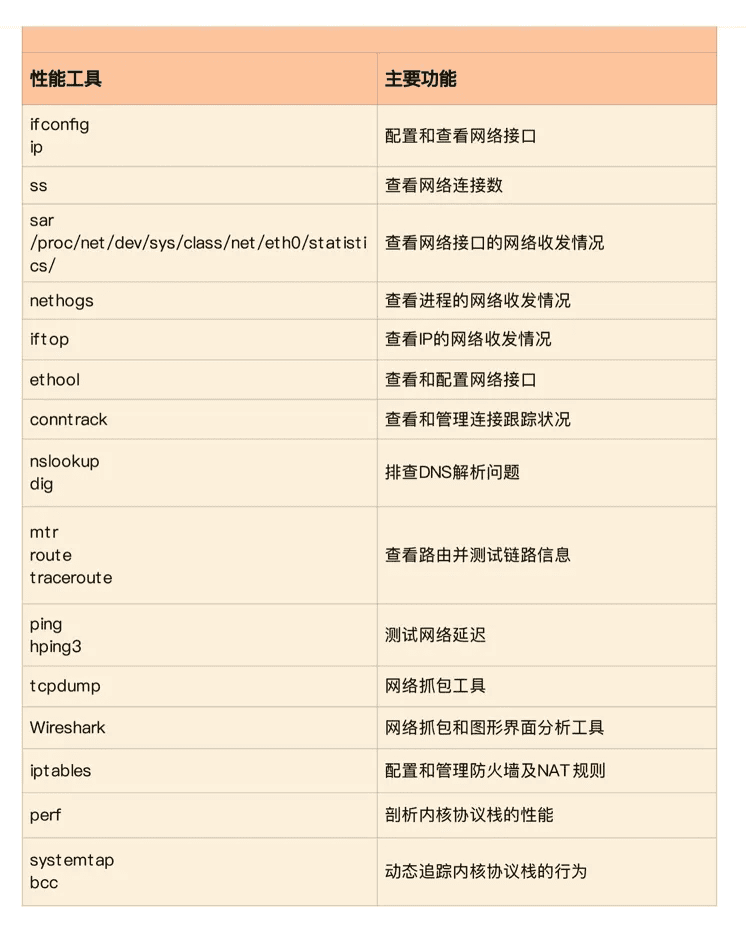
再来看第二个维度,从性能工具出发。这可以让你更快上手使用工具,迅速找出想要观察的性能指标。特别是在工具有限的情况下,我们更要充分利用好手头的每一个工具,用少量工具也要尽力挖掘出大量信息。
同样的,我也将这些常用工具,汇总成了一个表格,方便你区分和理解。自然,你也可以当成一个“工具指标”指南使用,需要时查表即可。
根据工具名称联系对应的性能指标:
网络性能优化
总的来说,先要获得网络基准测试报告,然后通过相关性能工具,定位出网络性能瓶颈。再接下来的优化工作,就是水到渠成的事情了。
当然,还是那句话,要优化网络性能,肯定离不开 Linux 系统的网络协议栈和网络收发流程的辅助。你可以结合下面这张图再回忆一下这部分的知识。
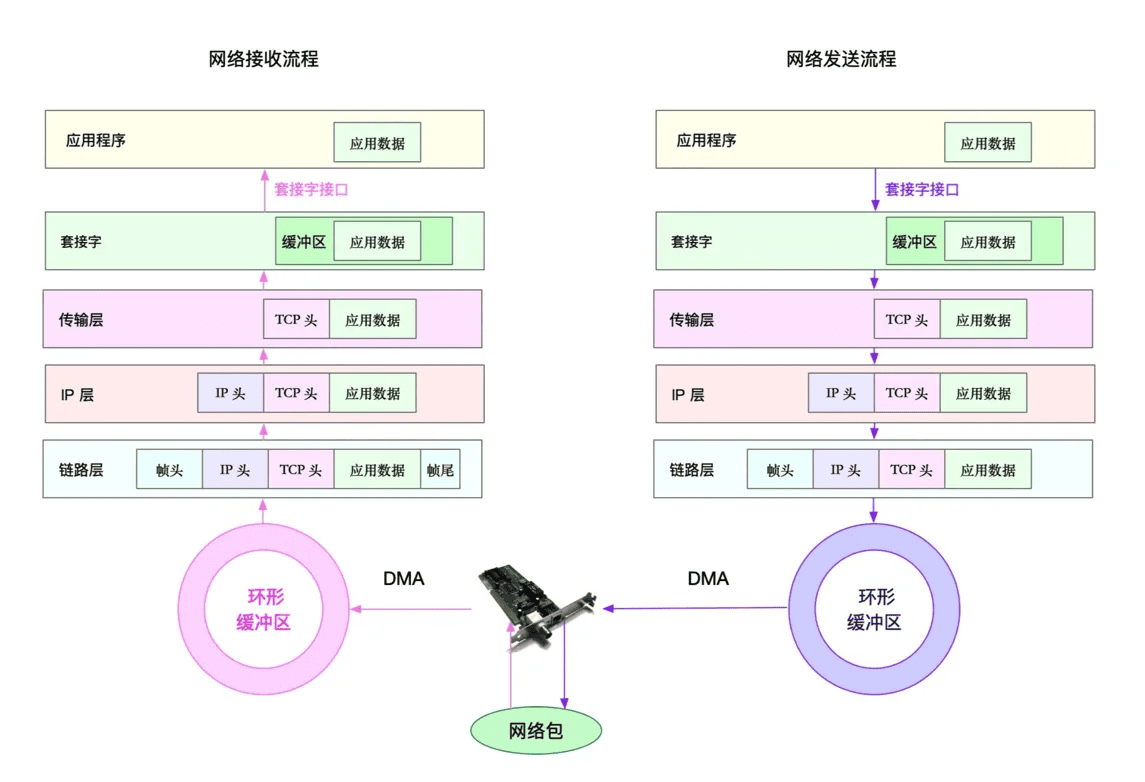
接下来,我们就可以从应用程序、套接字、传输层、网络层以及链路层等几个角度,分别来看网络性能优化的基本思路。
应用程序
应用程序,通常通过套接字接口进行网络操作。由于网络收发通常比较耗时,所以应用程序的优化,主要就是对网络 I/O 和进程自身的工作模型的优化。
相关内容,其实我们在 C10K 和 C1000K 回顾 的文章中已经学过了。这里我们简单回顾一下。
从网络 I/O 的角度来说,主要有下面两种优化思路。
第一种是最常用的 I/O 多路复用技术 epoll,主要用来取代 select 和 poll。这其实是解决 C10K 问题的关键,也是目前很多网络应用默认使用的机制。
第二种是使用异步 I/O(Asynchronous I/O,AIO)。AIO 允许应用程序同时发起很多 I/O 操作,而不用等待这些操作完成。等到 I/O 完成后,系统会用事件通知的方式,告诉应用程序结果。不过,AIO 的使用比较复杂,你需要小心处理很多边缘情况。 而从进程的工作模型来说,也有两种不同的模型用来优化。
第一种,主进程 + 多个 worker 子进程。其中,主进程负责管理网络连接,而子进程负责实际的业务处理。这也是最常用的一种模型。
第二种,监听到相同端口的多进程模型。在这种模型下,所有进程都会监听相同接口,并且开启 SO_REUSEPORT 选项,由内核负责,把请求负载均衡到这些监听进程中去。
除了网络 I/O 和进程的工作模型外,应用层的网络协议优化,也是至关重要的一点。我总结了常见的几种优化方法。
- 使用长连接取代短连接,可以显著降低 TCP 建立连接的成本。在每秒请求次数较多时,这样做的效果非常明显。
- 使用内存等方式,来缓存不常变化的数据,可以降低网络 I/O 次数,同时加快应用程序的响应速度。
- 使用 Protocol Buffer 等序列化的方式,压缩网络 I/O 的数据量,可以提高应用程序的吞吐。
- 使用 DNS 缓存、预取、HTTPDNS 等方式,减少 DNS 解析的延迟,也可以提升网络 I/O 的整体速度。
套接字
套接字可以屏蔽掉 Linux 内核中不同协议的差异,为应用程序提供统一的访问接口。每个套接字,都有一个读写缓冲区。
读缓冲区,缓存了远端发过来的数据。如果读缓冲区已满,就不能再接收新的数据。
写缓冲区,缓存了要发出去的数据。如果写缓冲区已满,应用程序的写操作就会被阻塞。
所以,为了提高网络的吞吐量,你通常需要调整这些缓冲区的大小。比如:
增大每个套接字的缓冲区大小 net.core.optmem_max;
增大套接字接收缓冲区大小 net.core.rmem_max 和发送缓冲区大小 net.core.wmem_max;
增大 TCP 接收缓冲区大小 net.ipv4.tcp_rmem 和发送缓冲区大小 net.ipv4.tcp_wmem。
至于套接字的内核选项,我把它们整理成了一个表格,方便你在需要时参考:
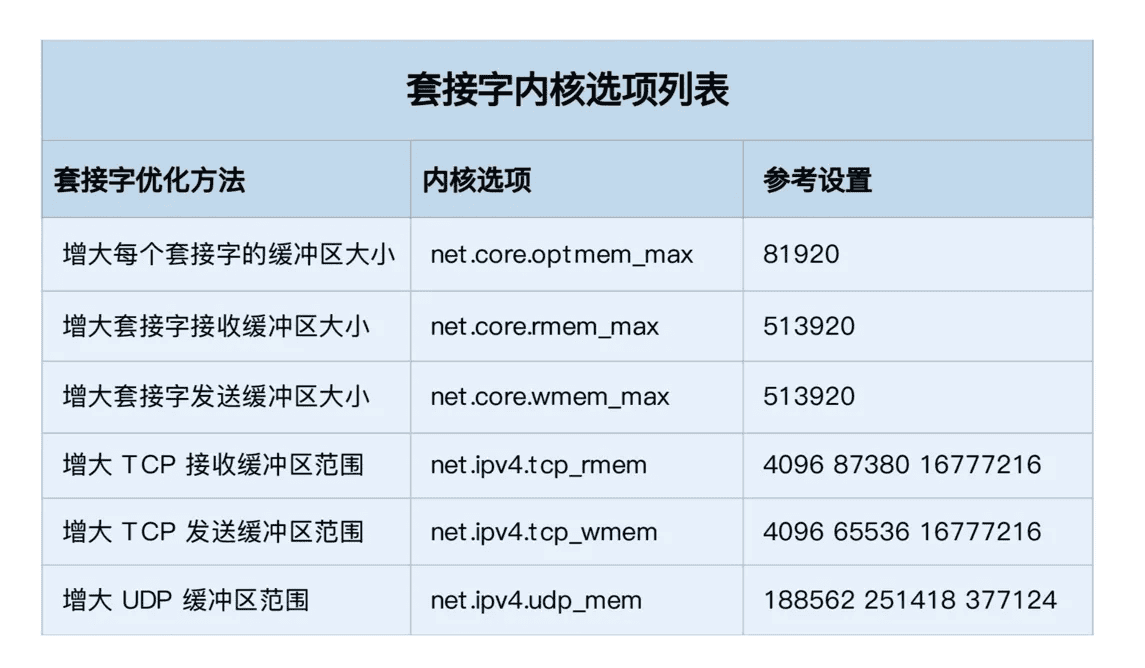
不过有几点需要你注意。
- tcp_rmem 和 tcp_wmem 的三个数值分别是 min,default,max,系统会根据这些设置,自动调整 TCP 接收 / 发送缓冲区的大小。
- udp_mem 的三个数值分别是 min,pressure,max,系统会根据这些设置,自动调整 UDP 发送缓冲区的大小。
当然,表格中的数值只提供参考价值,具体应该设置多少,还需要你根据实际的网络状况来确定。比如,发送缓冲区大小,理想数值是吞吐量 * 延迟,这样才可以达到最大网络利用率。
除此之外,套接字接口还提供了一些配置选项,用来修改网络连接的行为:
- 为 TCP 连接设置 TCP_NODELAY 后,就可以禁用 Nagle 算法;
- 为 TCP 连接开启 TCP_CORK 后,可以让小包聚合成大包后再发送(注意会阻塞小包的发送);
- 使用 SO_SNDBUF 和 SO_RCVBUF ,可以分别调整套接字发送缓冲区和接收缓冲区的大小。
在优化网络性能时,你可以结合 Linux 系统的网络协议栈和网络收发流程,然后从应用程序、套接字、传输层、网络层再到链路层等,进行逐层优化。
当然,其实我们分析、定位网络瓶颈,也是基于这些进行的。定位出性能瓶颈后,就可以根据瓶颈所在的协议层进行优化。比如,今天我们学了应用程序和套接字的优化思路:
- 在应用程序中,主要优化 I/O 模型、工作模型以及应用层的网络协议;
- 在套接字层中,主要优化套接字的缓冲区大小。
传输层
传输层最重要的是 TCP 和 UDP 协议,所以这儿的优化,其实主要就是对这两种协议的优化。
我们首先来看 TCP 协议的优化。
TCP 提供了面向连接的可靠传输服务。要优化 TCP,我们首先要掌握 TCP 协议的基本原理,比如流量控制、慢启动、拥塞避免、延迟确认以及状态流图(如下图所示)等。
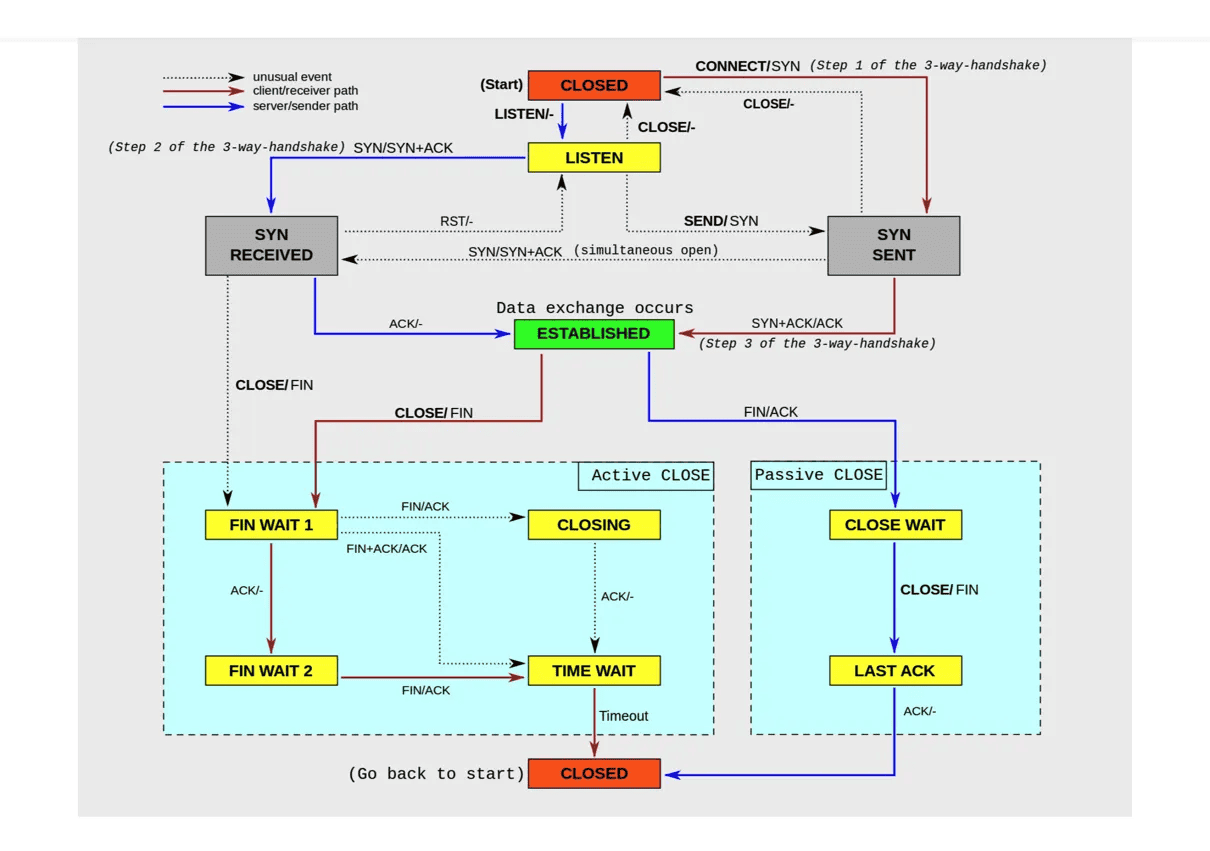
关于这些原理的细节,我就不再展开讲解了。如果你还没有完全掌握,建议你先学完这些基本原理后再来优化,而不是囫囵吞枣地乱抄乱试。
掌握这些原理后,你就可以在不破坏 TCP 正常工作的基础上,对它进行优化。下面,我分几类情况详细说明。
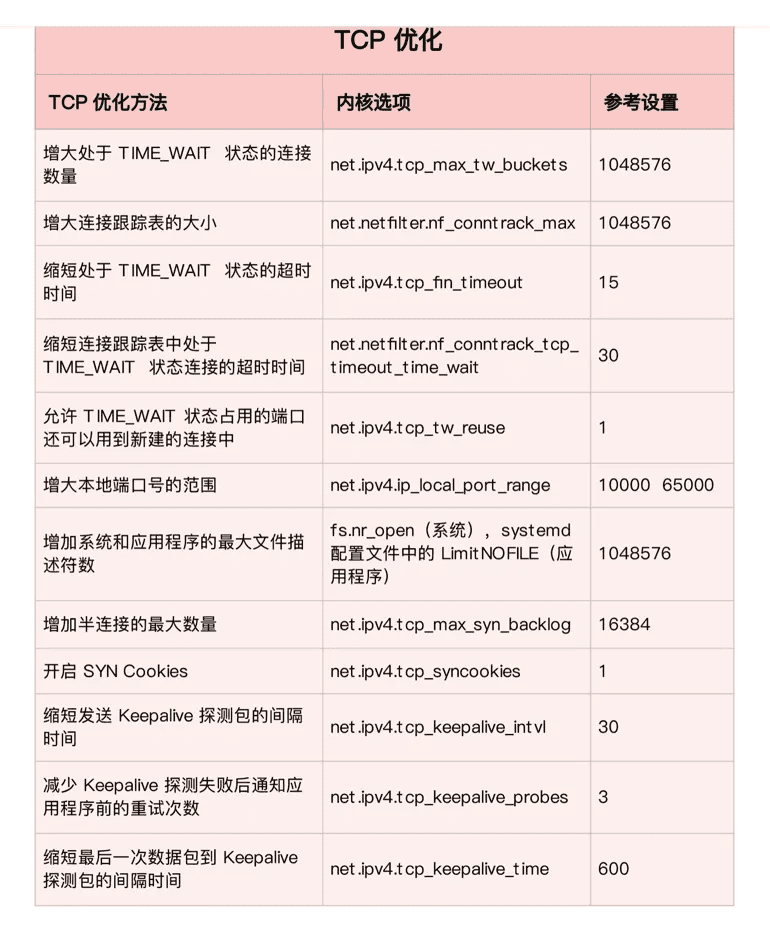
第一类,在请求数比较大的场景下,你可能会看到大量处于 TIME_WAIT 状态的连接,它们会占用大量内存和端口资源。这时,我们可以优化与 TIME_WAIT 状态相关的内核选项,比如采取下面几种措施。
- 增大处于 TIME_WAIT 状态的连接数量 net.ipv4.tcp_max_tw_buckets ,并增大连接跟踪表的大小 net.netfilter.nf_conntrack_max。
- 减小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait ,让系统尽快释放它们所占用的资源。
- 开启端口复用 net.ipv4.tcp_tw_reuse。这样,被 TIME_WAIT 状态占用的端口,还能用到新建的连接中。
- 增大本地端口的范围 net.ipv4.ip_local_port_range 。这样就可以支持更多连接,提高整体的并发能力。
- 增加最大文件描述符的数量。你可以使用 fs.nr_open 和 fs.file-max ,分别增大进程和系统的最大文件描述符数;或在应用程序的 systemd 配置文件中,配置 LimitNOFILE ,设置应用程序的最大文件描述符数。
第二类,为了缓解 SYN FLOOD 等,利用 TCP 协议特点进行攻击而引发的性能问题,你可以考虑优化与 SYN 状态相关的内核选项,比如采取下面几种措施。
- 增大 TCP 半连接的最大数量 net.ipv4.tcp_max_syn_backlog ,或者开启 TCP SYN Cookies net.ipv4.tcp_syncookies ,来绕开半连接数量限制的问题(注意,这两个选项不可同时使用)。
- 减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数 net.ipv4.tcp_synack_retries。
第三类,在长连接的场景中,通常使用 Keepalive 来检测 TCP 连接的状态,以便对端连接断开后,可以自动回收。但是,系统默认的 Keepalive 探测间隔和重试次数,一般都无法满足应用程序的性能要求。所以,这时候你需要优化与 Keepalive 相关的内核选项,比如:
- 缩短最后一次数据包到 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_time;
- 缩短发送 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_intvl;
- 减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数 net.ipv4.tcp_keepalive_probes。
讲了这么多 TCP 优化方法,我也把它们整理成了一个表格,方便你在需要时参考(数值仅供参考,具体配置还要结合你的实际场景来调整):
优化 TCP 性能时,你还要注意,如果同时使用不同优化方法,可能会产生冲突。
比如,就像网络请求延迟的案例中我们曾经分析过的,服务器端开启 Nagle 算法,而客户端开启延迟确认机制,就很容易导致网络延迟增大。
另外,在使用 NAT 的服务器上,如果开启 net.ipv4.tcp_tw_recycle ,就很容易导致各种连接失败。实际上,由于坑太多,这个选项在内核的 4.1 版本中已经删除了。
说完 TCP,我们再来看 UDP 的优化。
UDP 提供了面向数据报的网络协议,它不需要网络连接,也不提供可靠性保障。所以,UDP 优化,相对于 TCP 来说,要简单得多。这里我也总结了常见的几种优化方案。
- 跟上篇套接字部分提到的一样,增大套接字缓冲区大小以及 UDP 缓冲区范围;
- 跟前面 TCP 部分提到的一样,增大本地端口号的范围;
- 根据 MTU 大小,调整 UDP 数据包的大小,减少或者避免分片的发生。
网络层
接下来,我们再来看网络层的优化。
网络层,负责网络包的封装、寻址和路由,包括 IP、ICMP 等常见协议。在网络层,最主要的优化,其实就是对路由、 IP 分片以及 ICMP 等进行调优。
第一种,从路由和转发的角度出发,你可以调整下面的内核选项。
- 在需要转发的服务器中,比如用作 NAT 网关的服务器或者使用 Docker 容器时,开启 IP 转发,即设置 net.ipv4.ip_forward = 1。
- 调整数据包的生存周期 TTL,比如设置 net.ipv4.ip_default_ttl = 64。注意,增大该值会降低系统性能。
- 开启数据包的反向地址校验,比如设置 net.ipv4.conf.eth0.rp_filter = 1。这样可以防止 IP 欺骗,并减少伪造 IP 带来的 DDoS 问题。
第二种,从分片的角度出发,最主要的是调整 MTU(Maximum Transmission Unit)的大小。
通常,MTU 的大小应该根据以太网的标准来设置。以太网标准规定,一个网络帧最大为 1518B,那么去掉以太网头部的 18B 后,剩余的 1500 就是以太网 MTU 的大小。
在使用 VXLAN、GRE 等叠加网络技术时,要注意,网络叠加会使原来的网络包变大,导致 MTU 也需要调整。
比如,就以 VXLAN 为例,它在原来报文的基础上,增加了 14B 的以太网头部、 8B 的 VXLAN 头部、8B 的 UDP 头部以及 20B 的 IP 头部。换句话说,每个包比原来增大了 50B。
所以,我们就需要把交换机、路由器等的 MTU,增大到 1550, 或者把 VXLAN 封包前(比如虚拟化环境中的虚拟网卡)的 MTU 减小为 1450。
另外,现在很多网络设备都支持巨帧,如果是这种环境,你还可以把 MTU 调大为 9000,以提高网络吞吐量。
第三种,从 ICMP 的角度出发,为了避免 ICMP 主机探测、ICMP Flood 等各种网络问题,你可以通过内核选项,来限制 ICMP 的行为。
- 比如,你可以禁止 ICMP 协议,即设置 net.ipv4.icmp_echo_ignore_all = 1。这样,外部主机就无法通过 ICMP 来探测主机。
- 或者,你还可以禁止广播 ICMP,即设置 net.ipv4.icmp_echo_ignore_broadcasts = 1。
链路层
网络层的下面是链路层,所以最后,我们再来看链路层的优化方法。
链路层负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。自然,链路层的优化,也是围绕这些基本功能进行的。接下来,我们从不同的几个方面分别来看。
由于网卡收包后调用的中断处理程序(特别是软中断),需要消耗大量的 CPU。所以,将这些中断处理程序调度到不同的 CPU 上执行,就可以显著提高网络吞吐量。这通常可以采用下面两种方法。
- 比如,你可以为网卡硬中断配置 CPU 亲和性(smp_affinity),或者开启 irqbalance 服务。
- 再如,你可以开启 RPS(Receive Packet Steering)和 RFS(Receive Flow Steering),将应用程序和软中断的处理,调度到相同 CPU 上,这样就可以增加 CPU 缓存命中率,减少网络延迟。
另外,现在的网卡都有很丰富的功能,原来在内核中通过软件处理的功能,可以卸载到网卡中,通过硬件来执行。
- TSO(TCP Segmentation Offload)和 UFO(UDP Fragmentation Offload):在 TCP/UDP 协议中直接发送大包;而 TCP 包的分段(按照 MSS 分段)和 UDP 的分片(按照 MTU 分片)功能,由网卡来完成 。
- GSO(Generic Segmentation Offload):在网卡不支持 TSO/UFO 时,将 TCP/UDP 包的分段,延迟到进入网卡前再执行。这样,不仅可以减少 CPU 的消耗,还可以在发生丢包时只重传分段后的包。
- LRO(Large Receive Offload):在接收 TCP 分段包时,由网卡将其组装合并后,再交给上层网络处理。不过要注意,在需要 IP 转发的情况下,不能开启 LRO,因为如果多个包的头部信息不一致,LRO 合并会导致网络包的校验错误。
- GRO(Generic Receive Offload):GRO 修复了 LRO 的缺陷,并且更为通用,同时支持 TCP 和 UDP。
- RSS(Receive Side Scaling):也称为多队列接收,它基于硬件的多个接收队列,来分配网络接收进程,这样可以让多个 CPU 来处理接收到的网络包。
- VXLAN 卸载:也就是让网卡来完成 VXLAN 的组包功能。
最后,对于网络接口本身,也有很多方法,可以优化网络的吞吐量。
- 比如,你可以开启网络接口的多队列功能。这样,每个队列就可以用不同的中断号,调度到不同 CPU 上执行,从而提升网络的吞吐量。
- 再如,你可以增大网络接口的缓冲区大小,以及队列长度等,提升网络传输的吞吐量(注意,这可能导致延迟增大)。
- 你还可以使用 Traffic Control 工具,为不同网络流量配置 QoS。
到这里,我就从应用程序、套接字、传输层、网络层,再到链路层,分别介绍了相应的网络性能优化方法。通过这些方法的优化后,网络性能就可以满足绝大部分场景了。
最后,别忘了一种极限场景。还记得我们学过的的 C10M 问题吗?
在单机并发 1000 万的场景中,对 Linux 网络协议栈进行的各种优化策略,基本都没有太大效果。因为这种情况下,网络协议栈的冗长流程,其实才是最主要的性能负担。
这时,我们可以用两种方式来优化。
第一种,使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率。
第二种,使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理,这样也可以实现很好的性能。
小结
在优化网络的性能时,我们可以结合 Linux 系统的网络协议栈和网络收发流程,从应用程序、套接字、传输层、网络层再到链路层等,对每个层次进行逐层优化。
实际上,我们分析和定位网络瓶颈,也是基于这些网络层进行的。而定位出网络性能瓶颈后,我们就可以根据瓶颈所在的协议层,进行优化。具体而言:
- 在应用程序中,主要是优化 I/O 模型、工作模型以及应用层的网络协议;
- 在套接字层中,主要是优化套接字的缓冲区大小;
- 在传输层中,主要是优化 TCP 和 UDP 协议;
- 在网络层中,主要是优化路由、转发、分片以及 ICMP 协议;
- 最后,在链路层中,主要是优化网络包的收发、网络功能卸载以及网卡选项。
如果这些方法依然不能满足你的要求,那就可以考虑,使用 DPDK 等用户态方式,绕过内核协议栈;或者,使用 XDP,在网络包进入内核协议栈前进行处理。