网络综合知识
代理的层次
“代理”也分不同的层次。比较常见的有如下几种:
- TCP 代理(TCP 端口转发)——4层(传输层)
- SOCKS 代理——5层(会话层)
- HTTP 代理——7层(应用层)
网关
严格来讲,“网关”是一个逻辑概念,不要把它当成具体的网络设备。充当“网关”的东东,可能是:路由器 or XX层交换机 or XX层防火墙 or 代理服务器......
“网关”也分不同的层次。如果不加定语,通常指的是“3层网关”(网络层网关)。列几种比较常见的,供参考:
- 路由器充当网关——3层(网络层)
- 3层交换机充当网关——3层(网络层)
- 4层交换机充当网关——4层(传输层)
- 应用层防火墙充当网关——7层(应用层)
- 代理服务器充当网关——(取决于代理的层次)
VPN种类
跨域问题
常见问题:引荐来源网址政策 strict-origin-when-cross-origin
原因以及解决:
提交表单发送ajax请求时,chrome 请求返回Referrer Policy: strict-origin-when-cross-origin错误,360浏览器返回 引用站点策略:no-referrer-when-downgrade,出现此类问题解决办法如下。
- 网站当前访问是使用 https,而提交表单或 ajax 请求却使用的是 http,可以归类为跨域问题。只需要将表单或ajax请求由http也修改为https即可。
- 谷歌浏览器,输入:
chrome://flags/#block-insecure-private-network-requests,将Block insecure private network requests这个插件设置为 Disabled 就行了。
adguard公共dns
官网:https://adguard-dns.io/en/public-dns.html
明文dns server
Default servers AdGuard DNS will block ads and trackers. IPv4: 94.140.14.14 94.140.15.15 IPv6: 2a10:50c0::ad1:ff 2a10:50c0::ad2:ff Non-filtering servers AdGuard DNS will not block ads, trackers, or any other DNS requests. IPv4: 94.140.14.140 94.140.14.141 IPv6: 2a10:50c0::1:ff 2a10:50c0::2:ff Family protection servers AdGuard DNS will block ads, trackers, adult content, and enable Safe Search and Safe Mode, where possible. IPv4: 94.140.14.15 94.140.15.16 IPv6: 2a10:50c0::bad1:ff 2a10:50c0::bad2:ff
DoH
Default server AdGuard DNS will block ads and trackers.
https://dns.adguard-dns.com/dns-queryNon-filtering server AdGuard DNS will not block ads, trackers, or any other DNS requests.
https://unfiltered.adguard-dns.com/dns-queryFamily protection server AdGuard DNS will block ads, trackers, adult content, and enable Safe Search and Safe Mode, where possible.
https://family.adguard-dns.com/dns-queryNAT
关于网络nat知识的笔记和摘要
NAT 原理
NAT 技术可以重写 IP 数据包的源 IP 或者目的 IP,被普遍地用来解决公网 IP 地址短缺的问题。它的主要原理就是,网络中的多台主机,通过共享同一个公网 IP 地址,来访问外网资源。同时,由于 NAT 屏蔽了内网网络,自然也就为局域网中的机器提供了安全隔离。
你既可以在支持网络地址转换的路由器(称为 NAT 网关)中配置 NAT,也可以在 Linux 服务器中配置 NAT。如果采用第二种方式,Linux 服务器实际上充当的是“软”路由器的角色。
NAT 的主要目的,是实现地址转换。根据实现方式的不同,NAT 可以分为三类:
- 静态 NAT,即内网 IP 与公网 IP 是一对一的永久映射关系;
- 动态 NAT,即内网 IP 从公网 IP 池中,动态选择一个进行映射;
- 网络地址端口转换 NAPT(Network Address and Port Translation),即把内网 IP 映射到公网 IP 的不同端口上,让多个内网 IP 可以共享同一个公网 IP 地址。
NAPT 是目前最流行的 NAT 类型,我们在 Linux 中配置的 NAT 也是这种类型。而根据转换方式的不同,我们又可以把 NAPT 分为三类。
第一类是源地址转换 SNAT,即目的地址不变,只替换源 IP 或源端口。SNAT 主要用于,多个内网 IP 共享同一个公网 IP ,来访问外网资源的场景。
第二类是目的地址转换 DNAT,即源 IP 保持不变,只替换目的 IP 或者目的端口。DNAT 主要通过公网 IP 的不同端口号,来访问内网的多种服务,同时会隐藏后端服务器的真实 IP 地址。
第三类是双向地址转换,即同时使用 SNAT 和 DNAT。当接收到网络包时,执行 DNAT,把目的 IP 转换为内网 IP;而在发送网络包时,执行 SNAT,把源 IP 替换为外部 IP。
双向地址转换,其实就是外网 IP 与内网 IP 的一对一映射关系,所以常用在虚拟化环境中,为虚拟机分配浮动的公网 IP 地址。
为了帮你理解 NAPT,我画了一张图。我们假设:
- 本地服务器的内网 IP 地址为 192.168.0.2;
- NAT 网关中的公网 IP 地址为 100.100.100.100;
- 要访问的目的服务器 baidu.com 的地址为 123.125.115.110。
那么 SNAT 和 DNAT 的过程,就如下图所示:
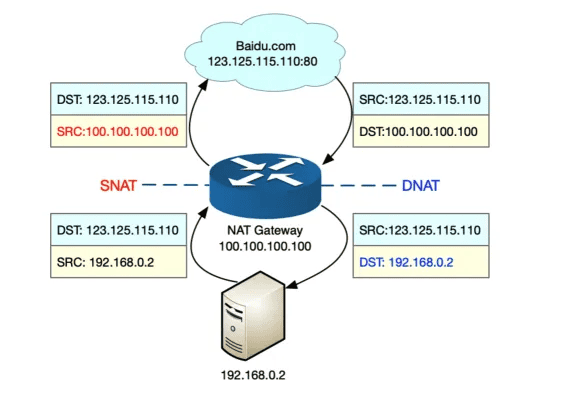
从图中,你可以发现:
- 当服务器访问 baidu.com 时,NAT 网关会把源地址,从服务器的内网 IP 192.168.0.2 替换成公网 IP 地址 100.100.100.100,然后才发送给 baidu.com;
- 当 baidu.com 发回响应包时,NAT 网关又会把目的地址,从公网 IP 地址 100.100.100.100 替换成服务器内网 IP 192.168.0.2,然后再发送给内网中的服务器。
概括总结
NAT 技术能够重写 IP 数据包的源 IP 或目的 IP,所以普遍用来解决公网 IP 地址短缺的问题。
它可以让网络中的多台主机,通过共享同一个公网 IP 地址,来访问外网资源。
同时,由于 NAT 屏蔽了内网网络,也为局域网中机器起到安全隔离的作用。
Linux 中的 NAT ,基于内核的连接跟踪模块实现。所以,它维护每个连接状态的同时,也会带来很高的性能成本。
以下很难,记住结论:
由于 NAT 基于 Linux 内核的连接跟踪机制来实现。所以,在分析 NAT 性能问题时,我们可以先从 conntrack 角度来分析,比如用 systemtap、perf 等,分析内核中 conntrack 的行文;然后,通过调整 netfilter 内核选项的参数,来进行优化。
其实,Linux 这种通过连接跟踪机制实现的 NAT,也常被称为有状态的 NAT,而维护状态,也带来了很高的性能成本。
所以,除了调整内核行为外,在不需要状态跟踪的场景下(比如只需要按预定的 IP 和端口进行映射,而不需要动态映射),我们也可以使用无状态的 NAT (比如用 tc 或基于 DPDK 开发),来进一步提升性能。
从Equifax信息泄露看数据安全
摘抄自:左耳听风-极客时间-陈皓
数据泄露介绍以及历史回顾
类似于 Equifax 这样的大规模数据泄露事件在互联网时代时不时地会发生。上一次如此大规模的数据泄露事件主角应该是雅虎。
继 2013 年大规模数据泄露之后,雅虎在 2014 年又遭遇攻击,泄露出 5 亿用户的密码,直到 2016 年有人在黑市公开交易这些数据时才为大众所知。雅虎股价在事件爆出的第二天就下跌了 2.4%。而此次 Equifax 的股价下跌超过 30%,市值缩水约 53 亿。这让各大企业不得不警惕。
类似的,LinkedIn 在 2012 年也泄露了 6500 万用户名和密码。事件发生后,LinkedIn 为了亡羊补牢,及时阻止被黑账户的登录,强制被黑用户修改密码,并改进了登录措施,从单步认证增强为带短信验证的两步认证。
国内也有类似的事件。2014 年携程网安全支付日志存在漏洞,导致大量用户信息如姓名、身份证号、银行卡类别、银行卡号、银行卡 CVV 码等信息泄露。这意味着,一旦这些信息被黑客窃取,在网络上盗刷银行卡消费将易如反掌。
如果说网络运维安全是一道防线,那么社会工程学攻击则可能攻破另一道防线——人。2011 年,RSA 公司声称他们被一种复杂的网络攻击所侵害,起因是有两个小组的员工收到一些钓鱼邮件。邮件的附件是带有恶意代码的 Excel 文件。当一个 RSA 员工打开该 Excel 文件时,恶意代码攻破了 Adobe Flash 中的一个漏洞。
该漏洞让黑客能用 Poison Ivy 远程管理工具来取得对机器的管理权,并访问 RSA 内网中的服务器。这次攻击主要威胁的是 SecurID 系统,最终导致了其母公司 EMC 花费 6630 万美元来调查、加固系统,并最终召回和重新分发了 30000 家企业客户的 SecurID 卡片。
数据泄露攻击
以这些公司为例,我们来看看这些攻击是怎样实现的。
- 利用程序框架或库的已知漏洞。比如这次 Equifax 被攻击,就是通过 Apache Struts 的已知漏洞。RSA 被攻击,也利用了 Adobe Flash 的已知漏洞。还有之前的“心脏流血”也是使用了 OpenSSL 的漏洞……
- 暴力破解密码。利用密码字典库或是已经泄露的密码来“撞库”。
- 代码注入。通过程序员代码的安全性问题,如 SQL 注入、XSS 攻击、CSRF 攻击等取得用户的权限。
- 利用程序日志不小心泄露的信息。携程的信息泄露就是本不应该能被读取的日志没有权限保护被读到了。
- 社会工程学。RSA 被攻击,第一道防线是人——RSA 的员工。只有员工的安全意识增强了,才能抵御此类攻击。其它的如钓鱼攻击也属于此类。
然后,除了表面的攻击之外,窃取到的信息也显示了一些数据管理上的问题。
- 只有一层安全。Equifax 只是被黑客攻破了管理面板和数据库,就造成了数据泄露。显然这样只有一层安全防护是不够的。
- 弱密码。Equifax 数据泄露事件绝对是管理问题。至少,密码系统应该不能让用户设置如此简单的密码,而且还要定期更换。最好的方式是通过数据证书、VPN、双因子验证的方式来登录。
- 向公网暴露了内部系统。在公司网络管理上出现了非常严重的问题。
- 对系统及时打安全补丁。监控业内的安全漏洞事件,及时做出响应,这是任何一个有高价值数据的公司都需要干的事。
- 安全日志被暴露。安全日志往往包含大量信息,被暴露是非常危险的。携程的 CVV 泄露就是从日志中被读到的。
- 保存了不必要保存的用户数据。携程保存了用户的信用卡号、有效期、姓名和 CVV 码,这些信息足以让人在网上盗刷信用卡。其实对于临时支付来说,这些信息完全可以不保存在磁盘上,临时在内存中处理完毕立即销毁,是最安全的做法。即便是快捷支付,也没有必要保存 CVV 码。安全日志也没有必要将所有信息都保存下来,比如可以只保存卡号后四位,也同样可以用于处理程序故障。
- 密码没有被合理地散列。以现代的安全观念来说,以明文方式保存密码是很不专业的做法。进一步的是只保存密码的散列值(用安全散列算法),LinkedIn 就是这样做的。但是,散列一则需要用目前公认安全的算法(比如 SHA-2 256),而已知被攻破的算法则最好不要使用(如 MD5,能人为找到碰撞,对密码验证来说问题不大),二则要加一个安全随机数作为盐(salt)。LinkedIn 的问题正在于没有加盐,导致密码可以通过预先计算的彩虹表(rainbow table)反查出明文。这些密码明文可以用来做什么事,就不好说了,撞库什么的都有可能了。对用户来说,最好是不同网站用不同密码。
专家建议
Contrast Security 是一家安全公司,其 CTO 杰夫·威廉姆斯( Jeff Williams)在博客中表示,虽说最佳实践是确保不使用有漏洞的程序库,但是在现实中并不容易做到这一点,因为安全更新来得比较频繁。
“经常,为了做这些安全性方面的更改,需要重新编写、测试和部署整个应用程序,而整个周期可能要花费几个月。我最近和几个大的组织机构聊过,他们在应对 CVE-2017-5638 这件事上花了至少四个月的时间。即便是在运营得最好的组织机构中,也经常在漏洞被发布和应用程序被更新之间有几个月的时间差。”威廉姆斯写道。
- Apache Struts 的副总裁雷内·吉伦(René Gielen)在 Apache 软件基金会的官方博客中写道,为了避免被攻击,对于使用了开源或闭源的支持性程序库的软件产品或服务,建议如下的 5 条最佳实践。理解你的软件产品中使用了哪些支持性框架和库,它们的版本号分别是多少。时刻跟踪影响这些产品和版本的最新安全性声明。
- 建立一个流程,来快速地部署带有安全补丁的软件产品发布版,这样一旦需要因为安全方面的原因而更新支持性框架或库,就可以快速地发布。最好能在几个小时或几天内完成,而不是几周或几个月。我们发现,绝大多数被攻破的情况是因为几个月或几年都没有更新有漏洞的软件组件而引起的。
- 所有复杂的软件都有漏洞。不要基于“支持性软件产品没有安全性漏洞”这样的假设来建立安全策略。
- 建立多个安全层。在一个面向公网的表示层(比如 Apache Struts 框架)后面建立多级有安全防护的层次,是一种良好的软件工程实践。就算表示层被攻破,也不会直接提供出重要(或所有)后台信息资源的访问权。
- 针对公网资源,建立对异常访问模式的监控机制。现在有很多侦测这些行为模式的开源和商业化产品,一旦发现异常访问就能发出警报。作为一种良好的运维实践,我们建议针对关键业务的网页服务应用一定要有这些监控机制。
在吉伦提的第二点中说到,理想的更新时间是在几个小时到几天。我们知道,作为企业,部署了一个版本的程序库,在更新前需要在测试系统上测试各个业务模块,确保兼容以后才能上线。
否则,盲目上线一个新版本,一旦遇到不兼容的情况,业务会部分或全部停滞,给客户留下不良印象,经济损失将是不可避免的。因此,这个更新周期必须通过软件工程手段来保证。
一个有力的解决方案是自动化测试。对以数据库为基础的程序库,设置专门的、初始时全空的测试用数据库来进行 API 级别的测试。对于 UI 框架,使用 UI 自动化测试工具进行自动化测试。
测试在原则上必须覆盖上层业务模块所有需要的功能,并对其兼容性加以验证。业务模块要连同程序库一起做集成的自动化测试,同时也要有单元测试。
升级前的人工测试也有必要,但由于安全性更新的紧迫性,覆盖主要和重要路径即可。
如果测试发现不兼容性,无法立即升级,那么要考虑的第二点是缓解措施(mitigation)。比如,能否禁用有漏洞的部分而不影响业务?如果不可行,那么是否可以通过 WAF 的设置来把一定特征的攻击载荷挡在门外?这些都是临时解决方案,要到开发部门把业务程序更新为能用新版本库,才能上线新版本的应用程序。
技术上的安全做法
除了上面所说的,那些安全防范的方法,我想在这里再加入一些我自己的经验。
从技术上来说,安全防范最好是做到连自己内部员工都能防,因为无论是程序的 BUG 还是漏洞,都是为了取得系统的权限而获得数据。如果我们能够连内部人都能防的话,那么就可以不用担心绝大多数的系统漏洞了。所谓“家贼难防”,如果要做到这一点,一般来说,有如下的一些方式。
首先,我们需要把我们的关键数据定义出来,然后把这些关键数据隔离出来,隔离到一个安全级别非常高的地方。所谓安全级别非常高的地方,即这个地方需要有各种如安全审计、安全监控、安全访问的区域。
一般来说,在这个区域内,这些敏感数据只入不出。通过提供服务接口来让别的系统只能在这个区域内操作这些数据,而不是把数据传出去,让别的系统在外部来操作这些数据。
举个例子,用户的手机号是敏感信息。如果有外部系统需要使用手机号,一般来说是想发个短信,那么我们这个掌管手机号数据的系统就对外提供发短信的功能,而外部系统通过 UID 或是别的抽像字段来调用这个系统的发短信的 API。信用卡也一样,提供信用卡的扣款 API 而不是把卡号返回给外部系统。
另外,如果业务必需返回用户的数据,一般来说,最终用户可能需要读取自己的数据,那么,对于像信用卡这样的关键数据是死也不能返回全部数据的,只能返回一个被“马赛克”了的数据(隐藏掉部分信息)。就算需要返回一些数据(如用户的地址),那么也需要在传输层上加密返回。
而用户加密的算法一定要采用非对称加密的方式,而且还要加上密钥的自动化更换,比如:在外部系统调用 100 次或是第一个小时后就自动更换加密的密钥。这样,整个系统在运行时就完全是自动化的了,而就算黑客得到了密钥,密匙也会过期,这样可以控制泄露范围。
通过上述手段,我们可以把数据控制在一个比较小的区域内。
而在这个区域内,我们依然会有相关的内部员工可以访问,因此,这个区域中的数据也是需要加密存放的,而加密使用的密钥则需要放在另外一个区域中。
也就是说,被加密的数据和用于加密的密钥是由不同的人来管理的,有密钥的人没有数据,有数据的人没有密钥,这两拨人可以有访问自己系统的权限,但是没有访问对方系统的权限。这样可以让这两拨人互相审计,互相牵制,从而提高数据的安全性。比如,这两拨人是不同公司的。
而密钥一定要做到随机生成,最好是对于不同用户的数据有不同的密钥,并且时不时地就能自动化更新一下,这样就可以做到内部防范。注明一下,按道理来说,用户自己的私钥应该由用户自己来保管,而公司的系统是不存的。而用户需要更新密钥时,需要对用户做身份鉴别,可以通过双因子认证,也可以通过更为严格的物理身份验证。例如,到银行柜台拿身份证重置密码。
最后,每当这些关键信息传到外部系统,需要做通知,最好是通知用户和自己的管理员。并且限制外部系统的数据访问量,超过访问量后,需要报警或是拒绝访问。
上述的这些技术手段是比较常见的做法,虽然也不能确保 100% 防止住,但基本上来说已经将安全级别提得非常高了。
不管怎么样,安全在今天是一个非常严肃的事,能做到绝对的安全基本上是不可能的,我们只能不断提高黑客入侵的门槛。当黑客的投入和收益大大不相符时,黑客也就失去了入侵的意义。
此外,安全还在于“风控”,任何系统就算你做得再完美,也会出现数据泄露的情况,只是我们可以把数据泄露的范围控制在一个什么样的比例,而这个比例就是我们的“风控”。
所谓的安全方案基本上来说就是能够把这个风险控制在一个很小的范围。对于在这个很小范围出现的一些数据安全的泄露,我们可以通过“风控基金”来做业务上的补偿,比如赔偿用户损失,等等。因为从经济利益上来说,如果风险可以控制在一个——我防范它的成本远高于我赔偿它的成本,那么,还不如赔偿了。
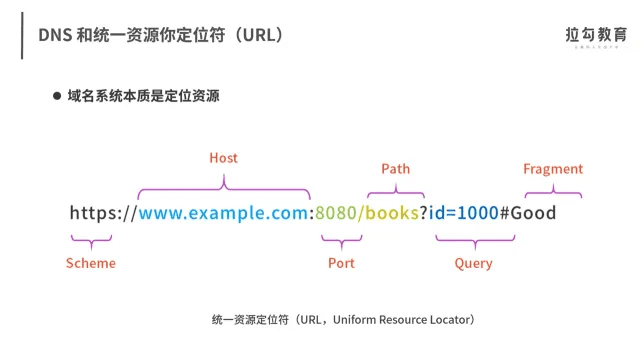
DNS与PTR
关于DNS与PTR基本说明
当你发现针对相同的网络服务,使用 IP 地址快而换成域名却慢很多时,就要想到,有可能是 DNS 在捣鬼。DNS 的解析,不仅包括从域名解析出 IP 地址的 A 记录请求,还包括性能工具帮你,“聪明”地从 IP 地址反查域名的 PTR 请求。
事实上,并非所有 IP 地址都会定义 PTR 记录,所以 PTR 查询很可能会失败。
在你使用 ping 时,如果发现结果中的延迟并不大,而 ping 命令本身却很慢,不要慌,有可能是背后的 PTR 在搞鬼。如何验证?可以使用tcpdump和wireshark抓包分析,这里省略。
知道问题后,解决起来就比较简单了,只要禁止 PTR 就可以。还是老路子,执行 man ping 命令,查询使用手册,就可以找出相应的方法,即加上 -n 选项禁止名称解析。
实际上,根据 IP 地址反查域名、根据端口号反查协议名称,是很多网络工具默认的行为, 而这往往会导致性能工具的工作缓慢。
所以,通常,网络性能工具都会提供一个选项(比如 -n 或者 -nn),来禁止名称解析。
比如ping、tcpdump等等:
bash
ping -n -c3 geektime.org
tcpdump -nn udp port 53 or host 35.190.27.188解释一下这条tcpdump命令。
- -nn ,表示不解析抓包中的域名(即不反向解析)、协议以及端口号。
- udp port 53 ,表示只显示 UDP 协议的端口号(包括源端口和目的端口)为 53 的包。
- host 35.190.27.188 ,表示只显示 IP 地址(包括源地址和目的地址)为 35.190.27.188 的包。
- 这两个过滤条件中间的“ or ”,表示或的关系,也就是说,只要满足上面两个条件中的任一个,就可以展示出来。
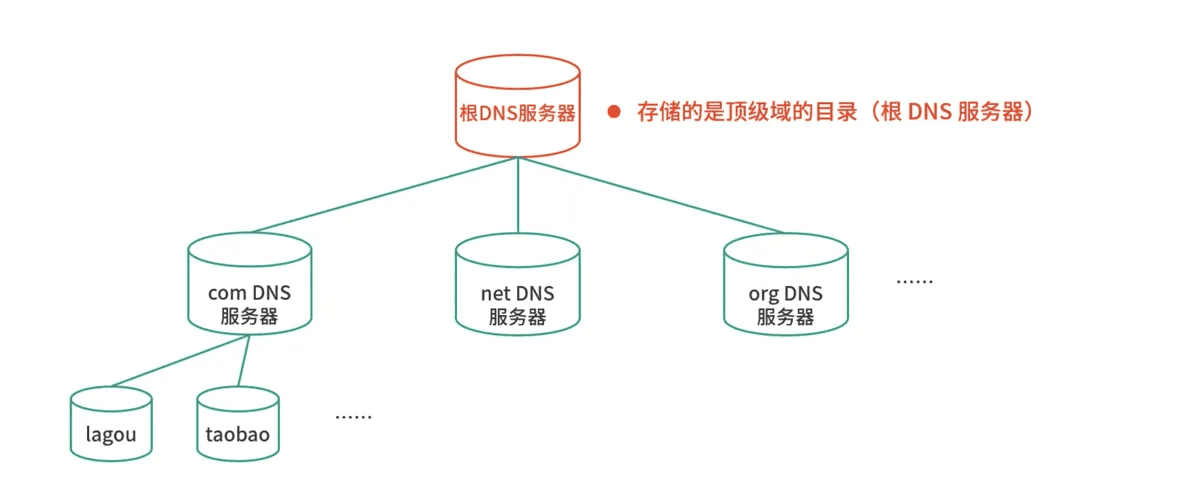
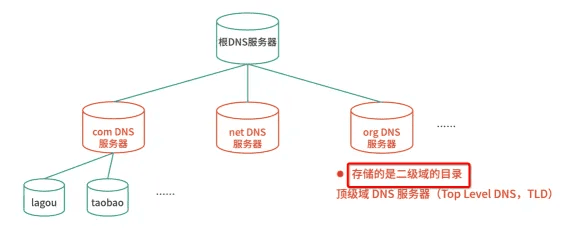
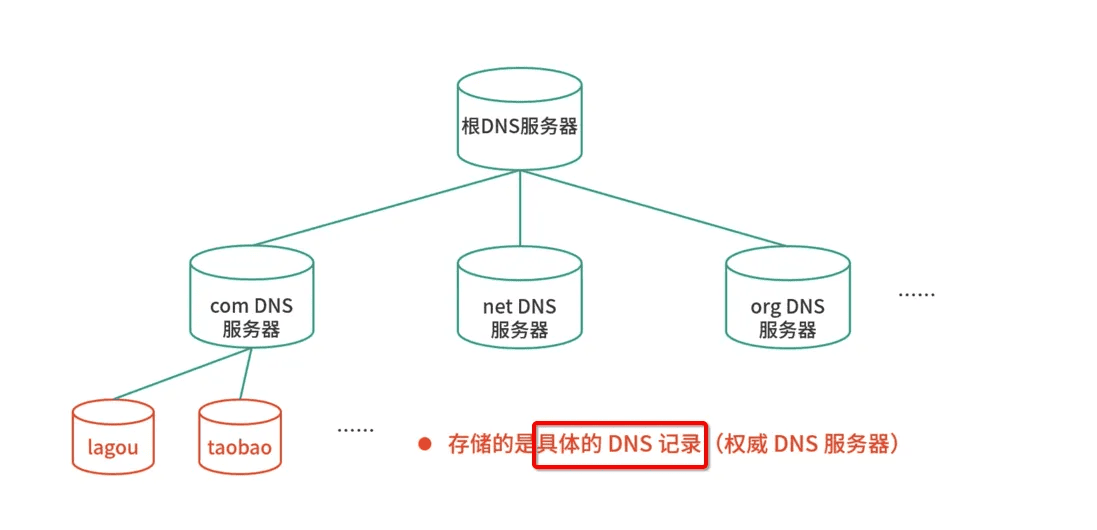
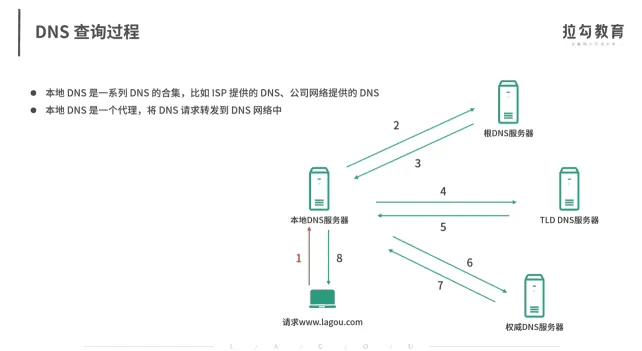
既然域名以分层的结构进行管理,相对应的,域名解析其实也是用递归的方式(从顶级开始,以此类推),发送给每个层级的域名服务器,直到得到解析结果。
不过不要担心,递归查询的过程并不需要你亲自操作,DNS 服务器会替你完成,你要做的,只是预先配置一个可用的 DNS 服务器就可以了。
当然,我们知道,通常来说,每级 DNS 服务器,都会有最近解析记录的缓存。当缓存命中时,直接用缓存中的记录应答就可以了。如果缓存过期或者不存在,才需要用刚刚提到的递归方式查询。
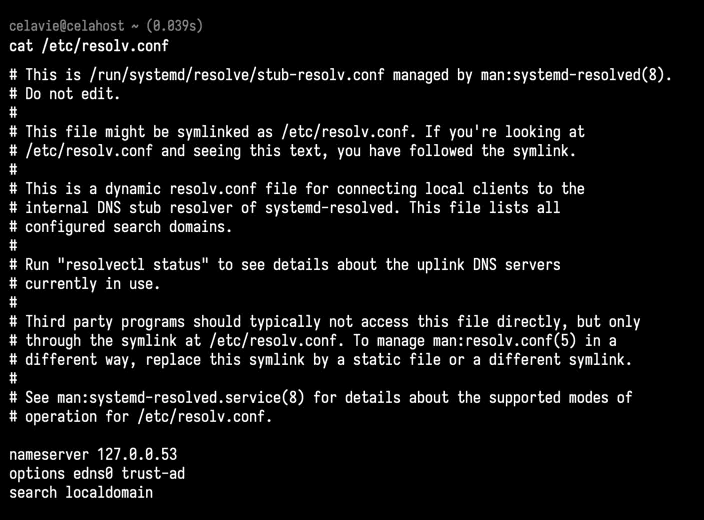
所以,系统管理员在配置 Linux 系统的网络时,除了需要配置 IP 地址,还需要给它配置 DNS 服务器,这样它才可以通过域名来访问外部服务。
cat /etc/resolv.conf (虚拟机示例)
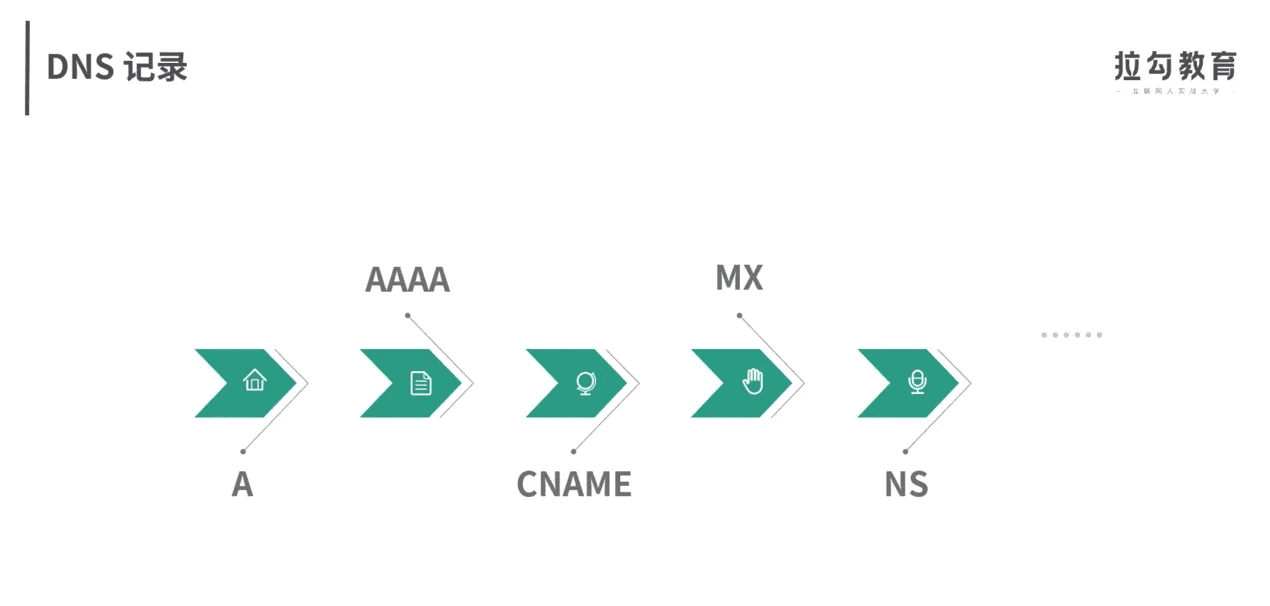
DNS 服务通过资源记录的方式,来管理所有数据,它支持 A、CNAME、MX、NS、PTR 等多种类型的记录。比如:
- A 记录,用来把域名转换成 IP 地址;
- CNAME 记录,用来创建别名;
- 而 NS 记录,则表示该域名对应的域名服务器地址。
简单来说,当我们访问某个网址时,就需要通过 DNS 的 A 记录,查询该域名对应的 IP 地址,然后再通过该 IP 来访问 Web 服务。
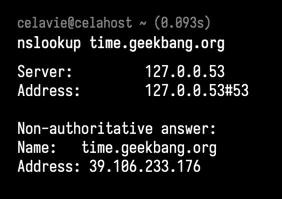
比如,还是以极客时间的网站 time.geekbang.org 为例,执行下面的 nslookup 命令,就可以查询到这个域名的 A 记录,可以看到,它的 IP 地址是 39.106.233.176。
DNS UDP TCP切换
DNS 协议在 TCP/IP 栈中属于应用层,不过实际传输还是基于 UDP 或者 TCP 协议(UDP 居多) ,并且域名服务器一般监听在端口 53 上。
IPv4 规范建议,报文长度应该控制在相对小的范围内,这个范围是 576 字节,相应的 UDP 载荷在 512 字节以内;像 DNS 解析,如果数据量超过 512 字节,也是会自动切换为 TCP 模式的,根本原因也是这个很早以前的规定。
查询域名dns信息
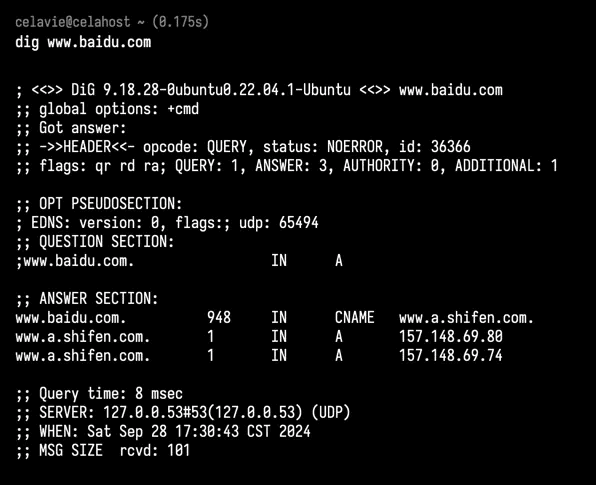
dig
dig www.baidu.com:
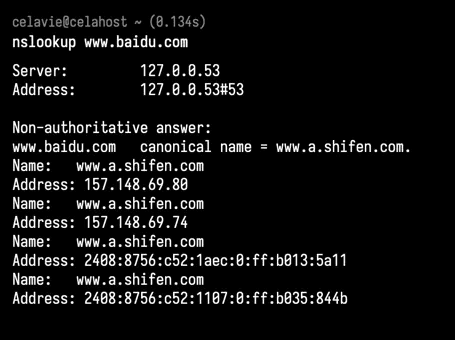
nslookup
nslookup www.baidu.com:
DNS缓存服务
我们使用的主流 Linux 发行版,除了最新版本的 Ubuntu (如 18.04 或者更新版本)外,其他版本并没有自动配置 DNS 缓存。 所以,想要为系统开启 DNS 缓存,就需要你做额外的配置。比如,最简单的方法,就是使用 dnsmasq。
dnsmasq 是最常用的 DNS 缓存服务之一,还经常作为 DHCP 服务来使用。它的安装和配置都比较简单,性能也可以满足绝大多数应用程序对 DNS 缓存的需求。
常见的 DNS 优化方法
- 对 DNS 解析的结果进行缓存。缓存是最有效的方法,但要注意,一旦缓存过期,还是要去 DNS 服务器重新获取新记录。不过,这对大部分应用程序来说都是可接受的。
- 对 DNS 解析的结果进行预取。这是浏览器等 Web 应用中最常用的方法,也就是说,不等用户点击页面上的超链接,浏览器就会在后台自动解析域名,并把结果缓存起来。
- 使用 HTTPDNS 取代常规的 DNS 解析。这是很多移动应用会选择的方法,特别是如今域名劫持普遍存在,使用 HTTP 协议绕过链路中的 DNS 服务器,就可以避免域名劫持的问题。
- 基于 DNS 的全局负载均衡(GSLB)。这不仅为服务提供了负载均衡和高可用的功能,还可以根据用户的位置,返回距离最近的 IP 地址。
网络资产搜索
搜索网络资产,确认资产漏洞影响范围
- fofa中国的,已被禁。https://fofa.info/
- shodan国外的。https://www.shodan.io/
- arl资产侦查灯塔。https://github.com/adysec/ARL
黑客工具收集
https://zhuanlan.zhihu.com/p/663289577
网络靶场收集
https://www.zhihu.com/question/276702290/answer/3263824905
Socket与IO多路复用



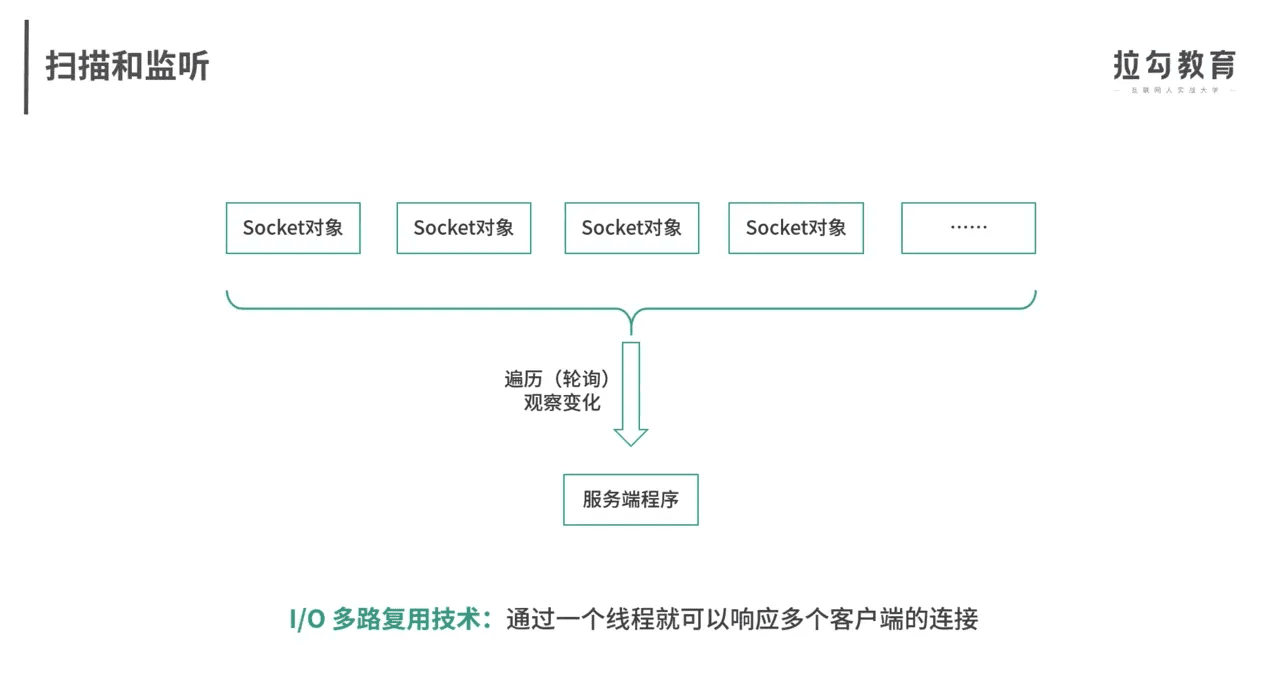
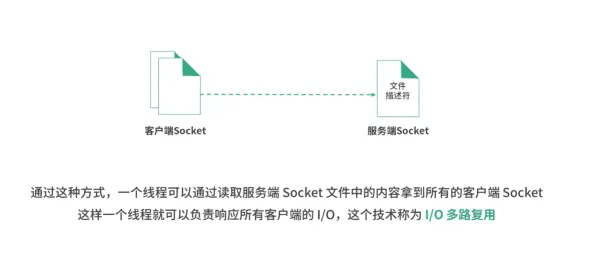


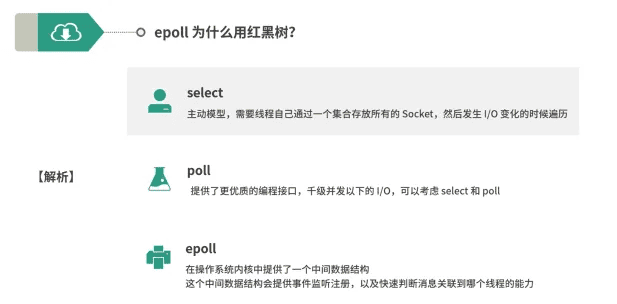
三层交互机的意义
三层交换机是有路由功能的交换机。一般来说交换机是工作在二层的,所以这里强 调“三层”交换机,就是突出了它带有三层(路由)功能。
MTU与MSS的关系



流和缓冲区


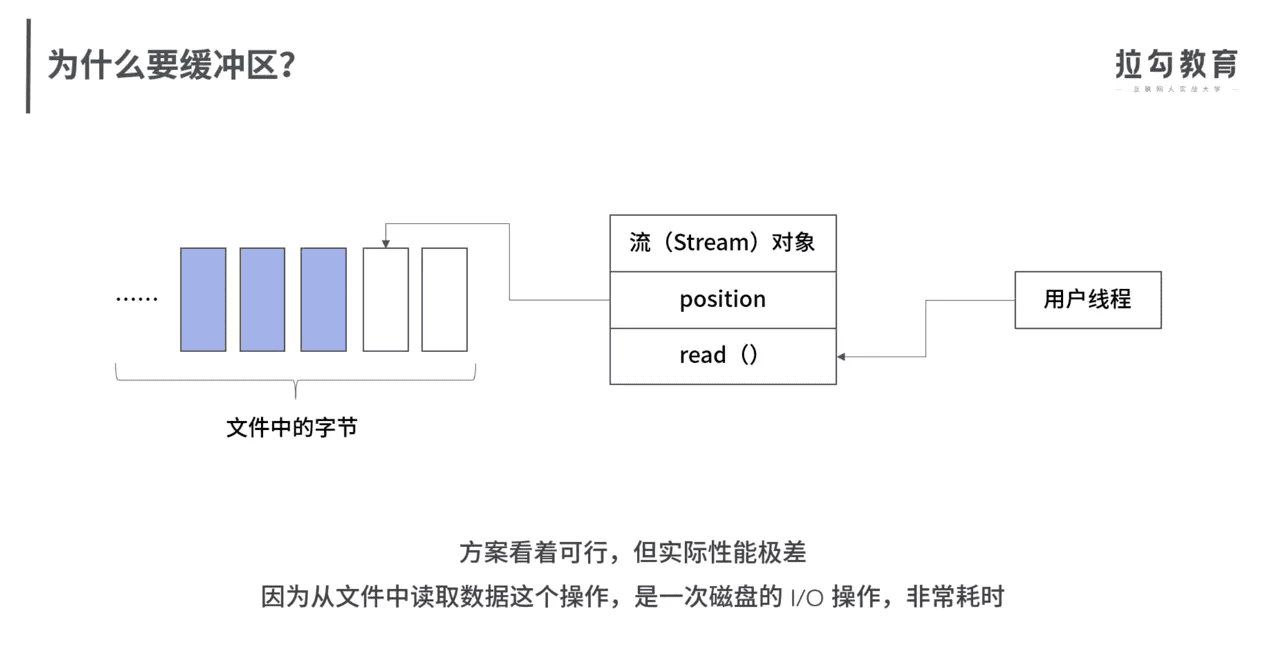
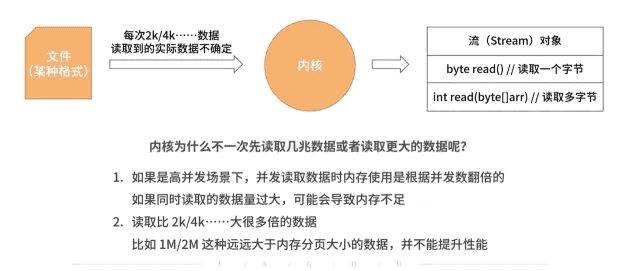
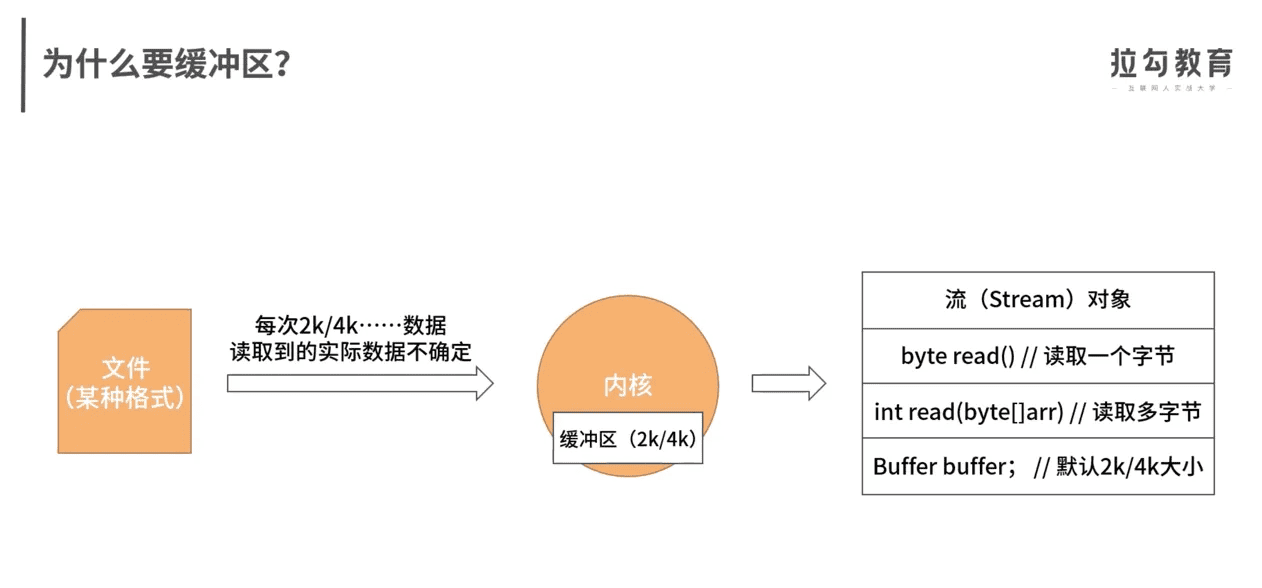

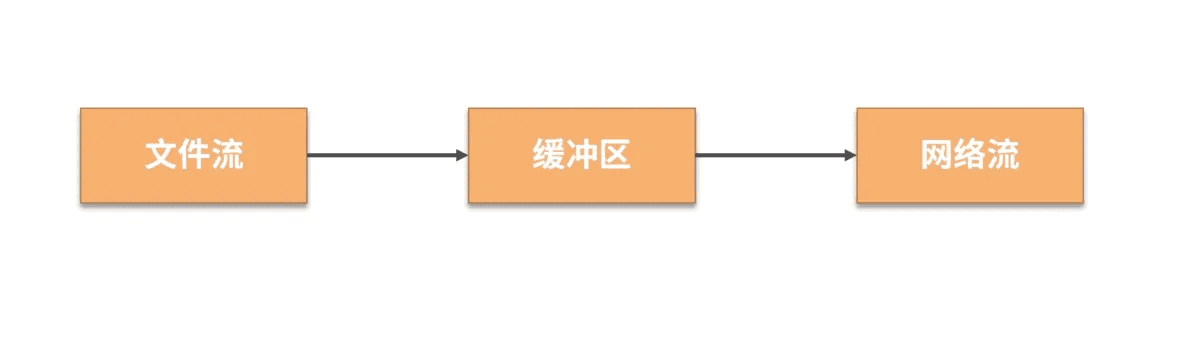



BIO、NIO、AIO
IO模型:BIO、NIO、AIO









数据拷贝是cpu密集操作。
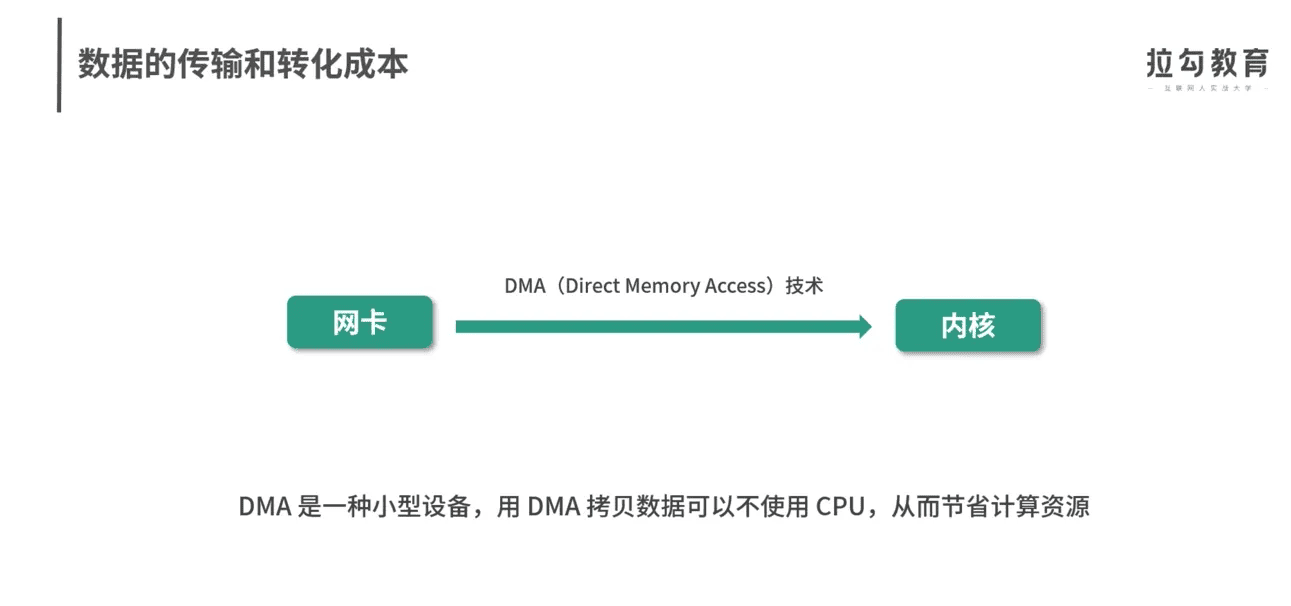

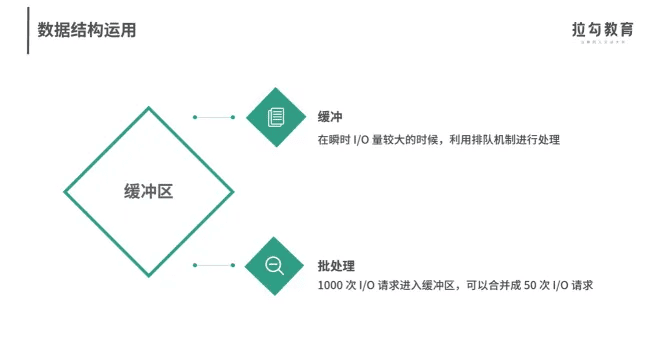
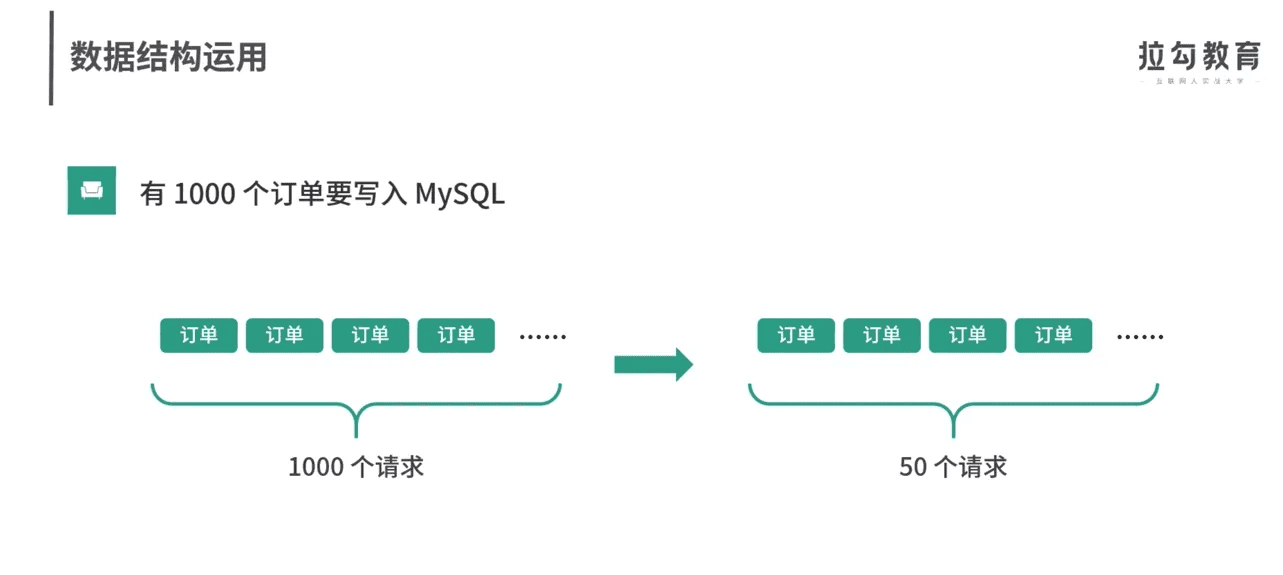
缓冲的意义,这几个图解释得很好。
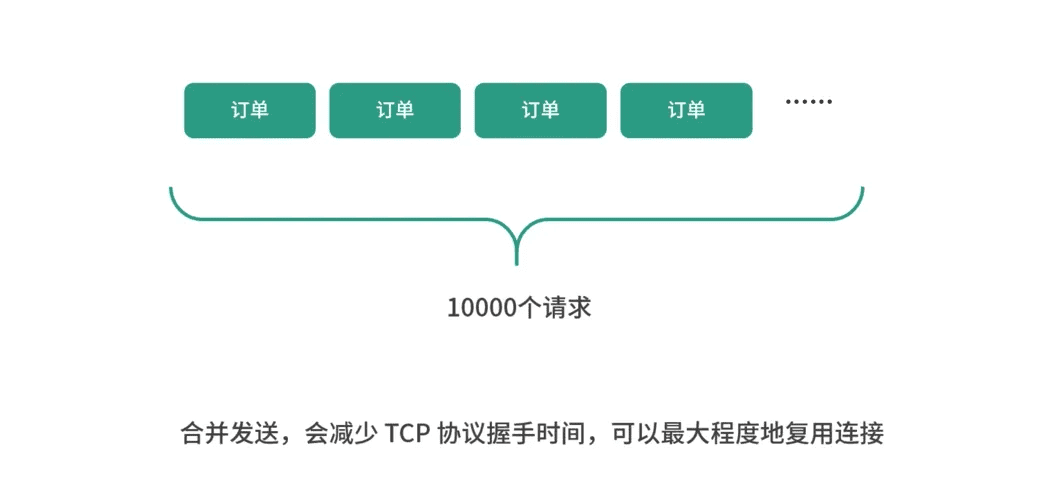

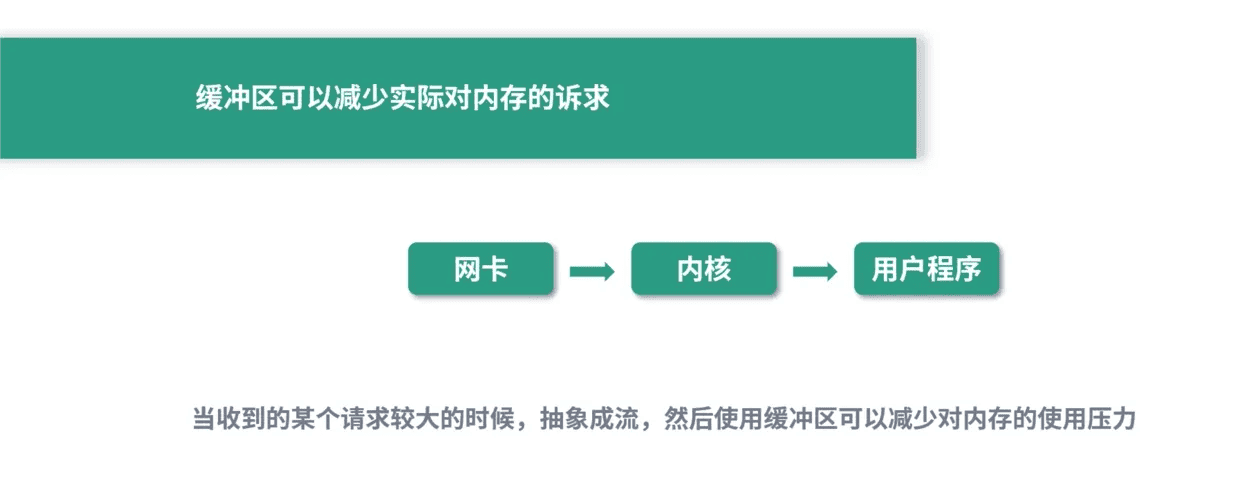





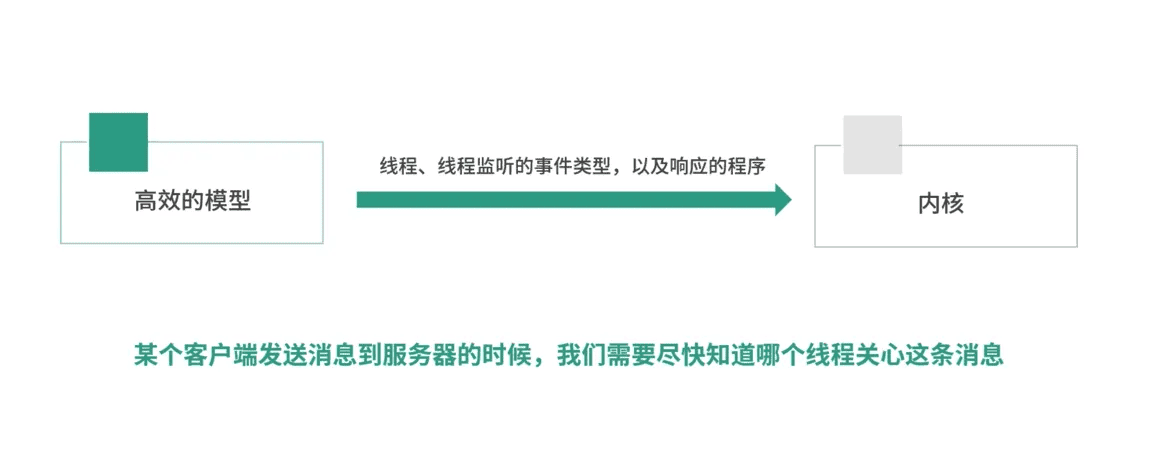
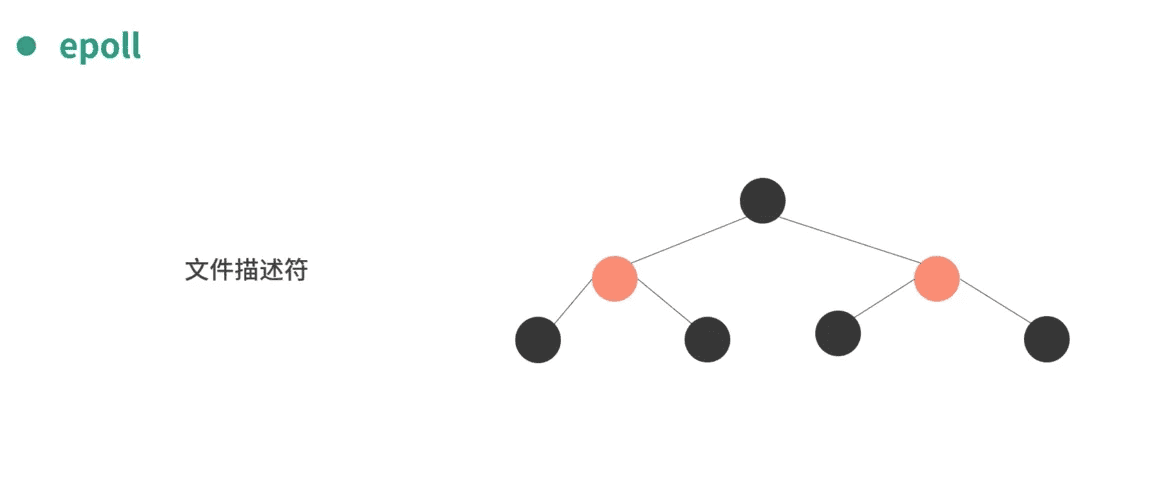




解耦,分而治之。



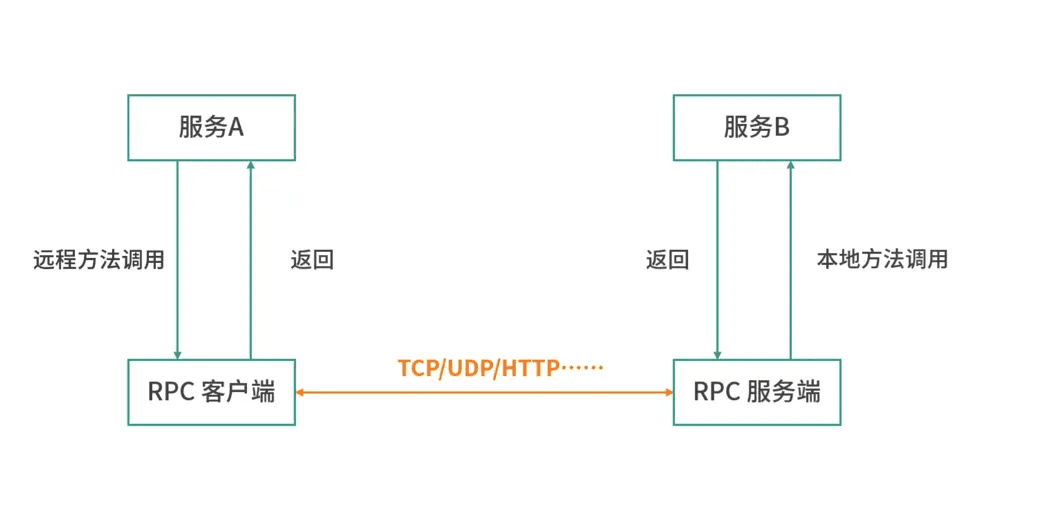
RPC







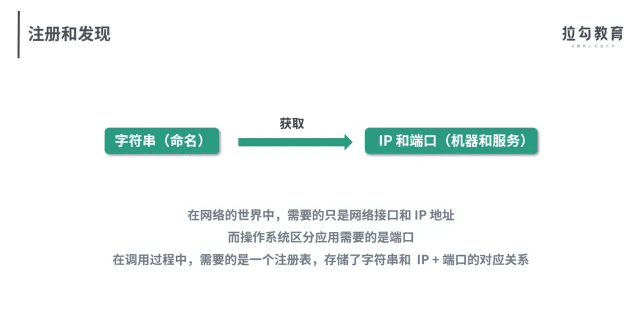


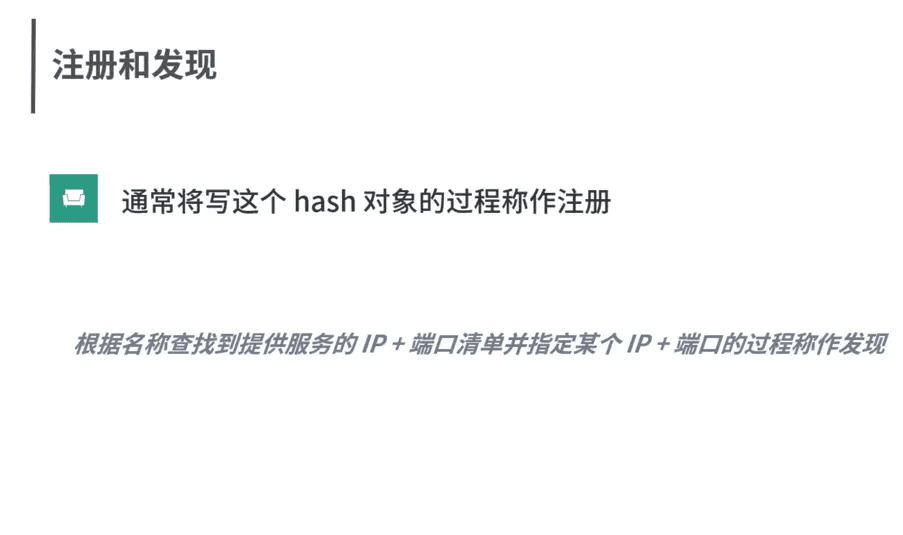





内外网NAT
外网连接:
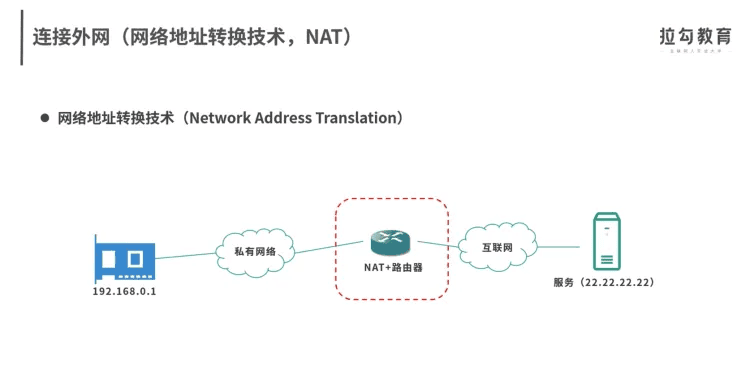
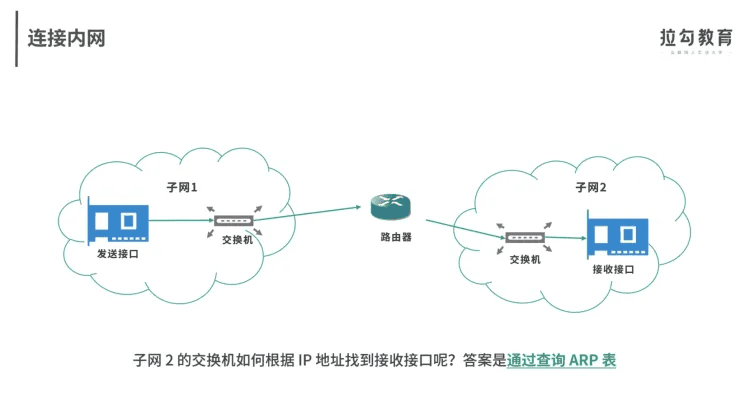
ne内网连接:
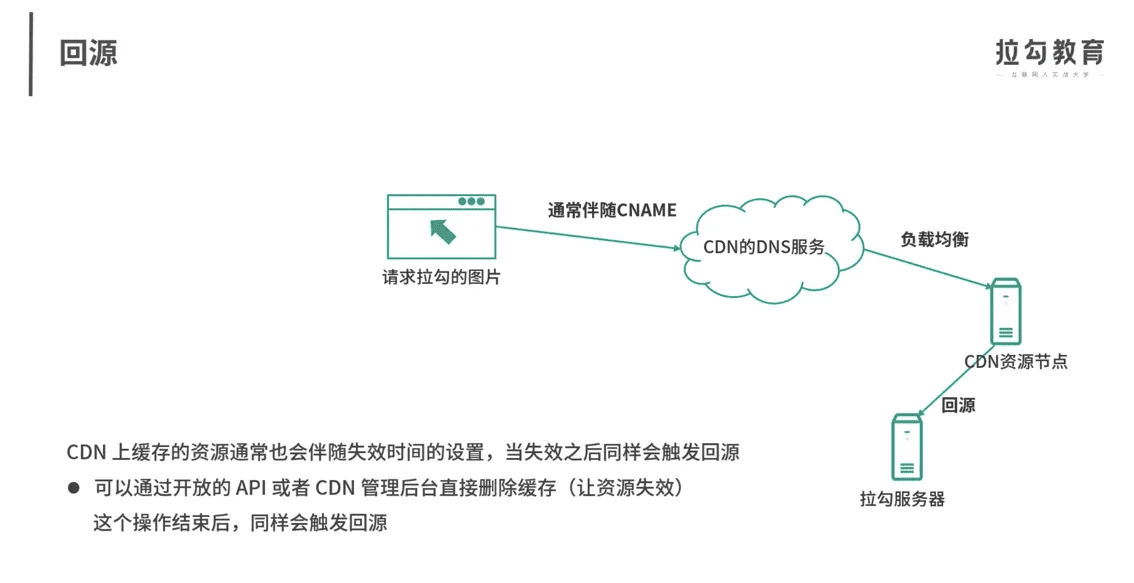
CDN

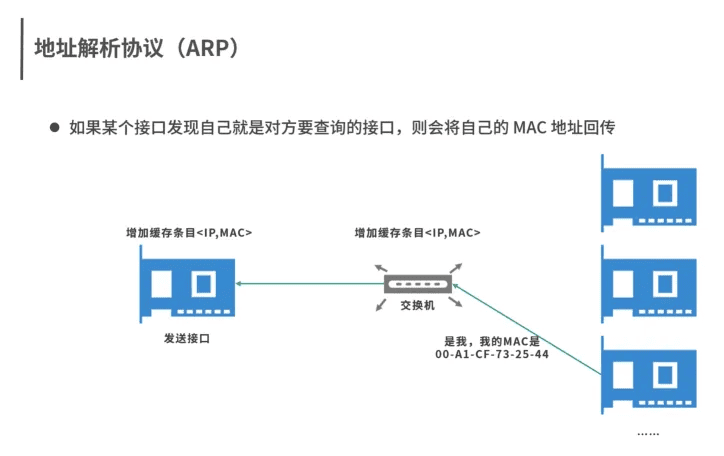
ARP
DNS