DDoS相关
关于DDoS相关知识的学习与摘抄笔记
DDoS简介
DDoS 的前身是 DoS(Denial of Service),即拒绝服务攻击,指利用大量的合理请求,来占用过多的目标资源,从而使目标服务无法响应正常请求。
DDoS(Distributed Denial of Service) 则是在 DoS 的基础上,采用了分布式架构,利用多台主机同时攻击目标主机。这样,即使目标服务部署了网络防御设备,面对大量网络请求时,还是无力应对。
比如,目前已知的最大流量攻击,正是Github 遭受的 DDoS 攻击,其峰值流量已经达到了 1.35Tbps,PPS 更是超过了 1.2 亿(126.9 million)。
从攻击的原理上来看,DDoS 可以分为下面几种类型。
- 第一种,耗尽带宽。无论是服务器还是路由器、交换机等网络设备,带宽都有固定的上限。带宽耗尽后,就会发生网络拥堵,从而无法传输其他正常的网络报文。
- 第二种,耗尽操作系统的资源。网络服务的正常运行,都需要一定的系统资源,像是 CPU、内存等物理资源,以及连接表等软件资源。一旦资源耗尽,系统就不能处理其他正常的网络连接。
- 第三种,消耗应用程序的运行资源。应用程序的运行,通常还需要跟其他的资源或系统交互。如果应用程序一直忙于处理无效请求,也会导致正常请求的处理变慢,甚至得不到响应。比如,构造大量不同的域名来攻击 DNS 服务器,就会导致 DNS 服务器不停执行迭代查询,并更新缓存。这会极大地消耗 DNS 服务器的资源,使 DNS 的响应变慢。
无论是哪一种类型的 DDoS,危害都是巨大的。
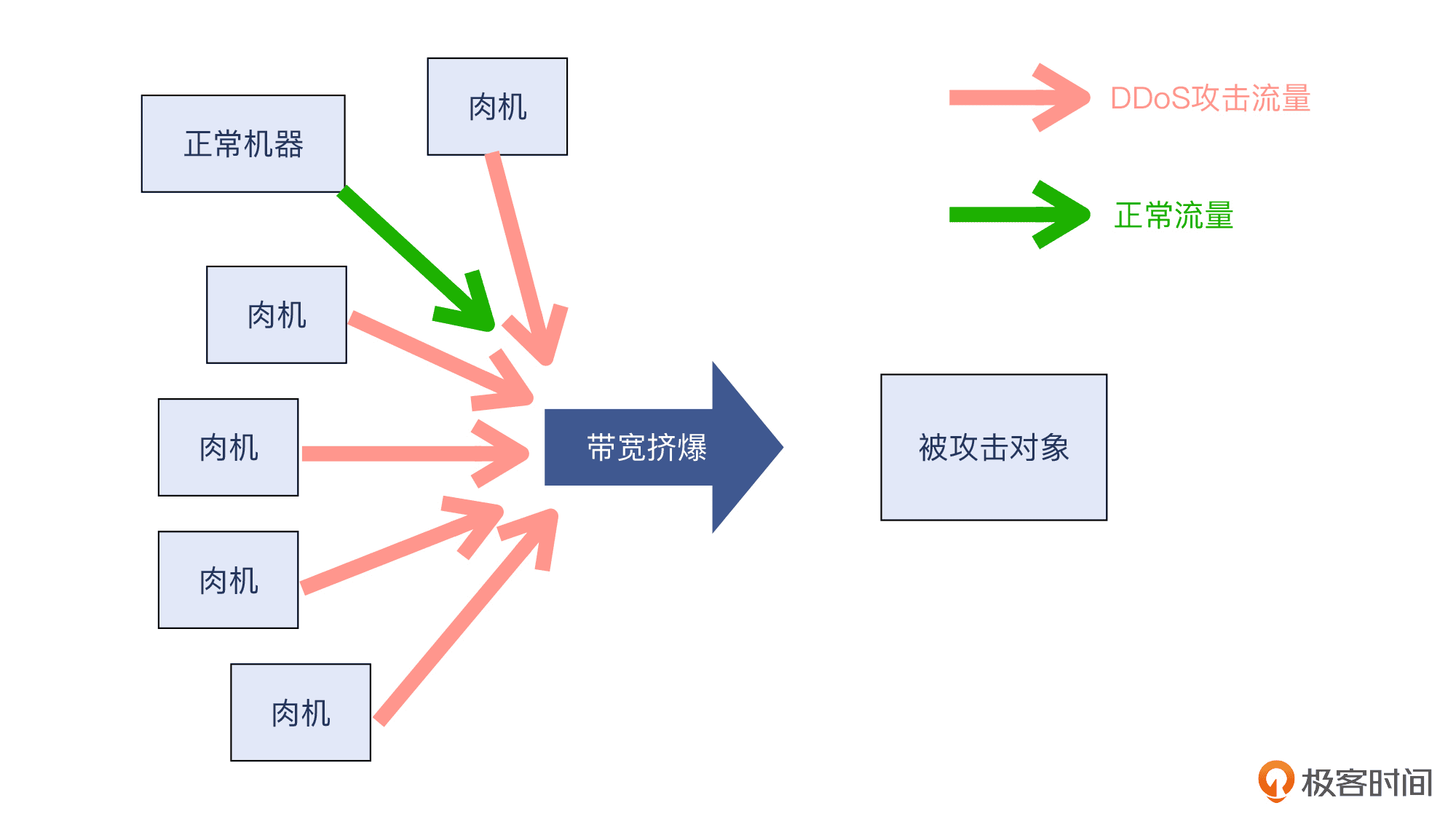
DDoS 的核心目标:耗尽网络带宽。
假设被攻击的站点的带宽为 1Gbps,那么攻击者只要让到达这个站点的流量超过 1Gbps,就可以让这个站点失去正常服务的能力。至于这些报文是否属于被攻击站点正在监听的有效流量,是没有关系的。它的目的很直接:把你家门口的路给堵死,让正常的流量没有机会进来。
我们看一下示意图:
理解了原理,那么技术性问题就来了:如何产生巨大的流量呢?
一种常见的实现方式就是反射型攻击。它的核心方法论是:利用一些协议的“响应是请求的很多倍”这样的特点,同时也利用“IP 协议不验证源 IP”的不足,达到把流量引到被攻击站点上去的目的。
NTP 反射攻击和 SSDP 都是如此。除此以外,你有没有发现别的这种“响应报文是请求报文的很多倍”的情况呢?如果有,那么恭喜你,你也能找到反射攻击的方式了!
这可真的是“举一反三”。明白了反射型攻击的原理,你是不是好像也有机会自己创造出新的 DDoS 攻击手段了。当然,还有很多别的事情要搞定,但是核心思路你已经清楚了。现在的你,是不是对 DDoS 有了更加深刻的认识了呢?
这里还有个细节。你有没有发现,NTP 反射攻击是依托于 UDP 协议的,其他很多 DDoS 类型也是利用了 UDP。为什么都是 UDP 呢?
思考这个问题。先看下经典的SYN Flood。
最经典的 DDoS 攻击方式
SYN Flood 正是互联网中最经典的 DDoS 攻击方式。从上面这个图,你也可以看到它的原理:
- 即客户端构造大量的 SYN 包,请求建立 TCP 连接;
- 而服务器收到包后,会向源 IP 发送 SYN+ACK 报文,并等待三次握手的最后一次 ACK 报文,直到超时。
这种等待状态的 TCP 连接,通常也称为半开连接。由于连接表的大小有限,大量的半开连接就会导致连接表迅速占满,从而无法建立新的 TCP 连接。
如何排查,可以先使用sar:
bash
sar -n DEV 1从这次 sar 的输出中,你可以看到,网络接收的 PPS 已经达到了 20000 多,但是 BPS 却只有 1174 kB,这样每个包的大小就只有 54B(1174*1024/22274=54)。
这明显就是个小包了,不过具体是个什么样的包呢?那我们就用 tcpdump 抓包看看吧。
在终端一中,执行下面的 tcpdump 命令:
bash
tcpdump -i eth0 -n tcp port 80输出中,Flags [S] 表示这是一个 SYN 包。大量的 SYN 包表明,这是一个 SYN Flood 攻击。
参考下面这张 TCP 状态图,你能看到,此时,服务器端的 TCP 连接,会处于 SYN_RECEIVED 状态:
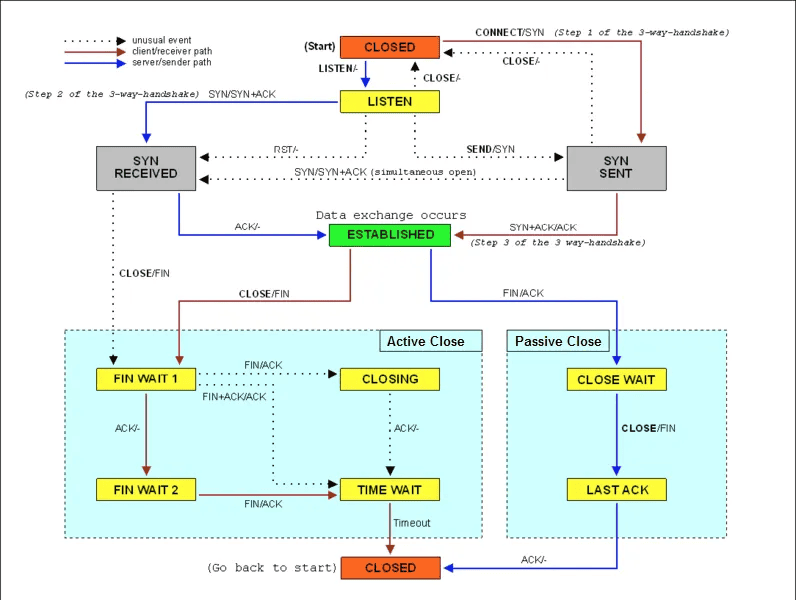
(图片来自 Wikipedia)
这其实提示了我们,查看 TCP 半开连接的方法,关键在于 SYN_RECEIVED 状态的连接。
我们可以使用 netstat ,来查看所有连接的状态,不过要注意,SYN_REVEIVED 的状态,通常被缩写为 SYN_RECV。
我们继续在终端一中,执行下面的 netstat 命令:
bash
netstat -n -p | grep SYN_REC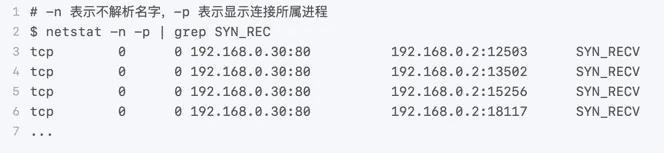
从结果中,你可以发现大量 SYN_RECV 状态的连接,并且源 IP 地址为 192.168.0.2。
进一步,我们还可以通过 wc 工具,来统计所有 SYN_RECV 状态的连接数:

找出源 IP 后,要解决 SYN 攻击的问题,只要丢掉相关的包就可以。这时,iptables 可以帮你完成这个任务。
你可以在终端一中,执行 iptables 命令开启,然后发现,正常用户也可以访问 Nginx 了,只是响应比较慢,从原来的 2ms 变成了现在的 1.5s。
不过,一般来说,SYN Flood 攻击中的源 IP 并不是固定的。比如,你可以在 hping3 命令中,加入 --rand-source 选项,来随机化源 IP。不过,这时,刚才的方法就不适用了。
幸好,我们还有很多其他方法,实现类似的目标。比如,你可以用以下两种方法,来限制 syn 包的速率:

到这里,我们已经初步限制了 SYN Flood 攻击。不过这还不够,因为我们的案例还只是单个的攻击源。
如果是多台机器同时发送 SYN Flood,这种方法可能就直接无效了。因为你很可能无法 SSH 登录(SSH 也是基于 TCP 的)到机器上去,更别提执行上述所有的排查命令。
所以,这还需要你事先对系统做一些 TCP 优化。
比如,SYN Flood 会导致 SYN_RECV 状态的连接急剧增大。
在上面的 netstat 命令中,你也可以看到 190 多个处于半开状态的连接。
不过,半开状态的连接数是有限制的,执行下面的命令,你就可以看到,默认的半连接容量只有 256:

换句话说, SYN 包数再稍微增大一些,就不能 SSH 登录机器了。 所以,你还应该增大半连接的容量,比如,你可以用下面的命令,将其增大为 1024:

另外,连接每个 SYN_RECV 时,如果失败的话,内核还会自动重试,并且默认的重试次数是 5 次。你可以执行下面的命令,将其减小为 1 次:

除此之外,TCP SYN Cookies 也是一种专门防御 SYN Flood 攻击的方法。
SYN Cookies 基于连接信息(包括源地址、源端口、目的地址、目的端口等)以及一个加密种子(如系统启动时间),计算出一个哈希值(SHA1),这个哈希值称为 cookie。
然后,这个 cookie 就被用作序列号,来应答 SYN+ACK 包,并释放连接状态。当客户端发送完三次握手的最后一次 ACK 后,服务器就会再次计算这个哈希值,确认是上次返回的 SYN+ACK 的返回包,才会进入 TCP 的连接状态。
因而,开启 SYN Cookies 后,就不需要维护半开连接状态了,进而也就没有了半连接数的限制。
注意,开启 TCP syncookies 后,内核选项 net.ipv4.tcp_max_syn_backlog 也就无效了。

注意,上述 sysctl 命令修改的配置都是临时的,重启后这些配置就会丢失。所以,为了保证配置持久化,你还应该把这些配置,写入 /etc/sysctl.conf 文件中。比如:

不过要记得,写入 /etc/sysctl.conf 的配置,需要执行 sysctl -p 命令后,才会动态生效。
以上方式只能缓解,不能解决。为什么不是解决 DDoS ,而只是缓解呢?而且今天案例中的方法,也只是让 Nginx 服务访问不再超时,但访问延迟还是比一开始时的 2ms 大得多。
实际上,当 DDoS 报文到达服务器后,Linux 提供的机制只能缓解,而无法彻底解决。即使像是 SYN Flood 这样的小包攻击,其巨大的 PPS ,也会导致 Linux 内核消耗大量资源,进而导致其他网络报文的处理缓慢。
虽然你可以调整内核参数,缓解 DDoS 带来的性能问题,却也会像案例这样,无法彻底解决它。
本质原因是:Linux 内核中冗长的协议栈,在 PPS 很大时,就是一个巨大的负担。对 DDoS 攻击来说,也是一样的道理。
所以,当时提到的 C10M 的方法,用到这里同样适合。比如,你可以基于 XDP 或者 DPDK,构建 DDoS 方案,在内核网络协议栈前,或者跳过内核协议栈,来识别并丢弃 DDoS 报文,避免 DDoS 对系统其他资源的消耗。
不过,对于流量型的 DDoS 来说,当服务器的带宽被耗尽后,在服务器内部处理就无能为力了。这时,只能在服务器外部的网络设备中,设法识别并阻断流量(当然前提是网络设备要能扛住流量攻击)。比如,购置专业的入侵检测和防御设备,配置流量清洗设备阻断恶意流量等。
既然 DDoS 这么难防御,这是不是说明, Linux 服务器内部压根儿就不关注这一点,而是全部交给专业的网络设备来处理呢?
当然不是,因为 DDoS 并不一定是因为大流量或者大 PPS,有时候,慢速的请求也会带来巨大的性能下降(这种情况称为慢速 DDoS)。
比如,很多针对应用程序的攻击,都会伪装成正常用户来请求资源。这种情况下,请求流量可能本身并不大,但响应流量却可能很大,并且应用程序内部也很可能要耗费大量资源处理。
这时,就需要应用程序考虑识别,并尽早拒绝掉这些恶意流量,比如合理利用缓存、增加 WAF(Web Application Firewall)、使用 CDN 等等。
本节总结:
由于 DDoS 的分布式、大流量、难追踪等特点,目前还没有方法可以完全防御 DDoS 带来的问题,只能设法缓解这个影响。
比如,你可以购买专业的流量清洗设备和网络防火墙,在网络入口处阻断恶意流量,只保留正常流量进入数据中心的服务器中。真正的ddos要靠运营商的流量清洗之类的硬件了。可以购买专业的流量清洗设备和网络防火墙,在网络入口处阻断恶意流量,只保留正常流量进入数据中心的服务器。
在 Linux 服务器中,你可以通过内核调优、DPDK、XDP 等多种方法,来增大服务器的抗攻击能力,降低 DDoS 对正常服务的影响。而在应用程序中,你可以利用各级缓存、 WAF、CDN 等方式,缓解 DDoS 对应用程序的影响。
UDP更容易被用来做DDoS
上面所述,TCP 当然也可能被 DDoS 所用,但是相对来说,如果用同样的成本,选择反射型攻击更加高效。而反射型攻击,主要基于 UDP,这是为什么呢?主要有两个原因。
(很多机场禁止了udp,梯子就不能打语音, 打语音走的是UDP,需要机场开了 UDP 才行。机场可能避免被 DDoS 会关闭 udp。 )
UDP 报文简单易于构造
这是协议本身决定的,UDP比TCP报文简单很多,易于构造。
UDP 是无状态的
这可能是一个更加关键的原因。UDP 是无状态的,不需要握手。像 NTP 反射攻击、SSDP 反射攻击,都是只要“一问一答”即可,所以攻击者只需要伪造一个请求报文,那么后续的响应报文,自然就发送给了被攻击站点了。
但是 TCP 就非常不同了。首先 TCP 需要三次握手,如果攻击者的 SYN 报文的源地址是伪造成被攻击站点的 IP,那么 SYN+ACK 报文就直接回复到那个站点的 IP 了,而不是攻击者。然后会发生什么呢?
被攻击站点收到一个莫名其妙的 SYN+ACK,就会被 RST 掉。这次 TCP 握手就这么结束了,攻击就没法继续了。
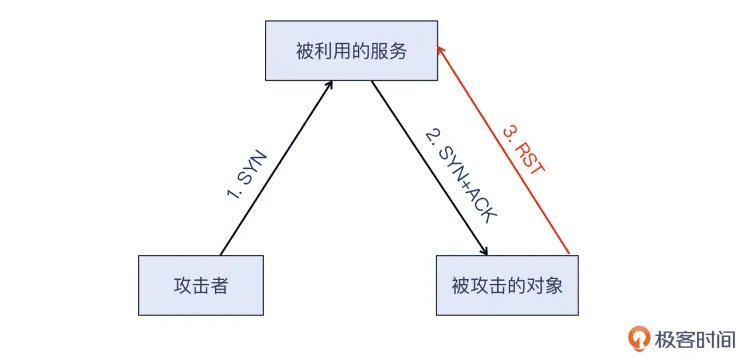
那跳过 TCP 握手,直接发送应用层请求(源地址还是伪造成被攻击站点的 IP)给反射服务呢?当然是直接被 RST,因为连握手都没做过呢。
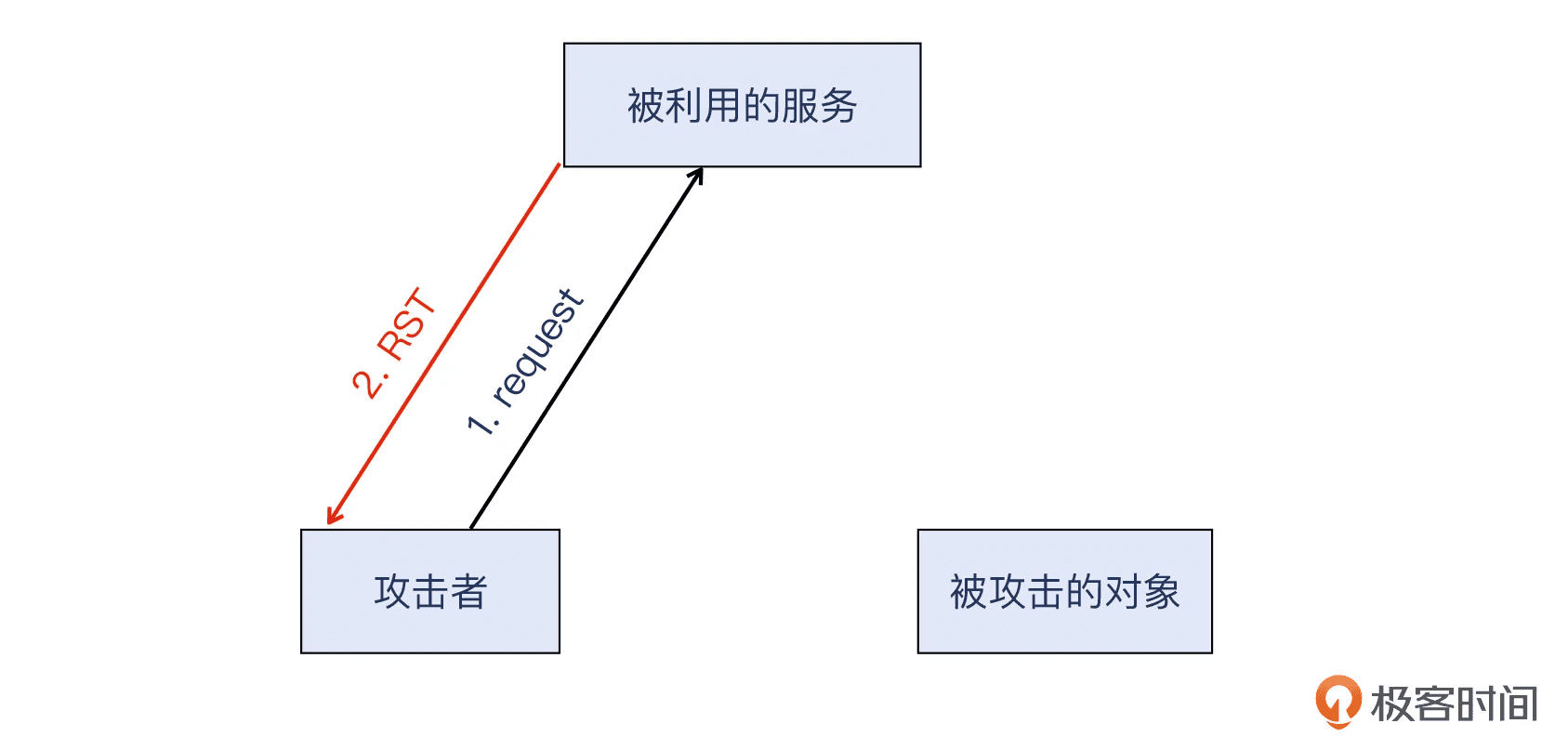
而且,即使通过了握手,后续通信双方还有对序列号和确认号进行校验等机制。虽然这些在技术上都可以实现,但难度大了很多,而选择 UDP,就不需要考虑这么多问题。
所以,用 TCP 的话就是直接攻击,而不是反射攻击了。比如 SYN 攻击、半连接攻击、全连接攻击、CC 攻击等等。从“性价比”上看,反射攻击的优势更大些。
如何应对 DDoS?
前面我们分析了 DDoS 中最为典型的反射放大攻击。以后如果我们发现服务异常,比如客户端的请求十分卡顿的话,就可以在服务端抓包,然后进行分析,就能快速定位是否是 DDoS 攻击了。
当然,还有一个更为简单直接的证据,就是你的公网接口带宽使用图,如果图上有明显的突增,甚至达到了接口带宽的上限,那也基本可以判定是遭遇 DDoS 了。
上面都是排查的手段,那接下来如何处理呢?一般来说,你自己单干是不行的,这里给你介绍几种应对策略,这样你以后就心里有数了。
高防清洗
一般来说,如果你的服务架设在公有云上,那么可以考虑使用云商或者其他专业安全服务商的高防产品。
高防是需要放置在源站前面的一类安全防护和清洗系统。它利用了自身的足够大的带宽,以及强大的防护清洗集群,实现对流量清洗,最终把攻击流量拦截在外面,清洗过后的正常流量进入源站,得以被正常处理。示意图如下:
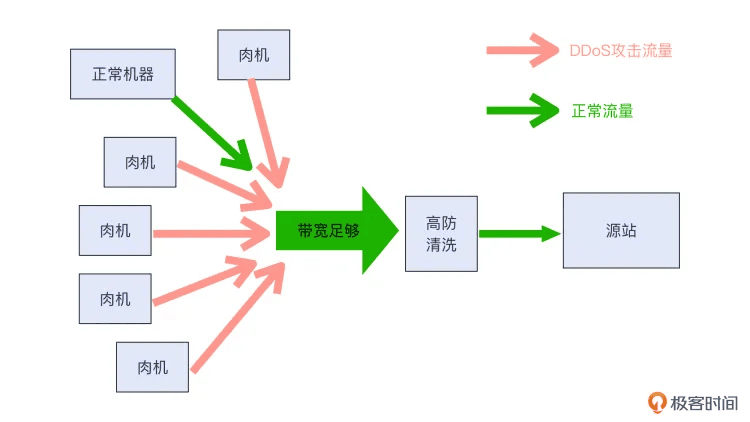
补充:这里的源站,就是被攻击的站点。
由于高防按时计费而且费用高昂,一般平时是不接入高防的。只有探测到被攻击时,才自动或者手动转入高防。这里的“接入高防”是什么意思呢?其实就是把站点域名指向高防的域名,这样就把流量先流向高防,再经清洗后回到源站。
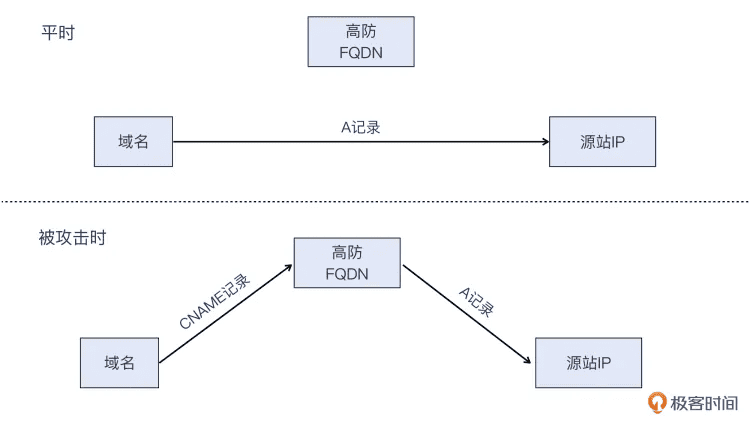
那如果攻击者不是通过域名解析,而是直接盯着 IP 做攻击的呢?也不难,你就把老的 IP 解绑,让攻击流量进入路由黑洞,然后绑定新的 IP。这时候,不要暴露新的 IP 的信息,它只能给高防回源用,不能让更多的人知道。
你有没有发现,从防护的生效点来说,高防这种方式是作用在服务端这一侧。那你可能会想到:如果我们能在攻击的源头就做防护,那是不是效果会更好呢?这就是另一类 DDoS 防护产品的设计思想,其中比较典型的产品是电信云堤。
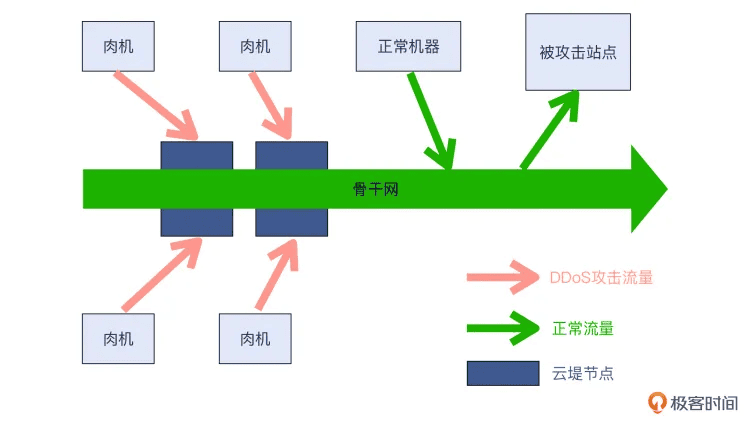
运行商的云堤
云堤本身属于运营商自己的系统,而无论被攻击站点还是肉机,都依托于运营商的公网线路才能进入因特网,所以云堤具有“地理”上的天然优势。
它可以作用在肉机的攻击流量进入骨干网之前,所以很可能这些攻击都没有机会走到被攻击站点的跟前了,相当于“扼杀在摇篮里”。我们看一下示意图:
anycast 和多 POP
我们知道了 DDoS 的本质是挤占网络带宽,那么对付它的核心策略就是:
用更大的带宽来接纳,先解决正常流量被挤出网络的问题。
在接纳后进行清洗,把正常流量识别出来,发回给源站,让业务继续进行。
前面介绍了高防和云堤,两者分别在被攻击站点的近端和远端起到了作用,也都是商业服务。那么,另外一种方式是自己搞定,这也是一些自身规模比较大的网站会部署的架构,它就是 anycast 和多 POP。
anycast 是网络术语,是指多个地点宣告同一个网段或者同一个 IP 地址的行为。比如,最典型的电信的 DNS 服务地址 114.114.114.114,还有谷歌的 DNS 服务 8.8.8.8,就是在全国乃至全球各处做了 anycast 的 IP 地址。与这个词类似的,还有 unicast 和 multicast,分别是指单播和多播。
比较大型的网站都会在各地部署 POP 点(也就是多 POP),然后这些 POP 点会宣告相同的 IP 段。一旦有 DDoS 攻击,因为它的目标 IP 是属于 anycast 网段的,所以会被因特网的路由策略,相对均匀地分布到这些 POP。
假如你有 20 个 POP 点宣告同一个网段,那么你就有机会把 DDoS 攻击化整为零,平均每个 POP 点承受 1/20 的攻击流量,大大降低了危害性。在攻击流量不高的时候,仅依靠自己的多个 POP 就可以吸收掉这些攻击流量,然后用自己的设备进行清洗就可以了。
这一点上看,anycast+ 多个 POP+ 自有的清洗设备,这一整套做好以后,相当于自己建设了一个中小型的高防系统。我画了个示意图供你参考:
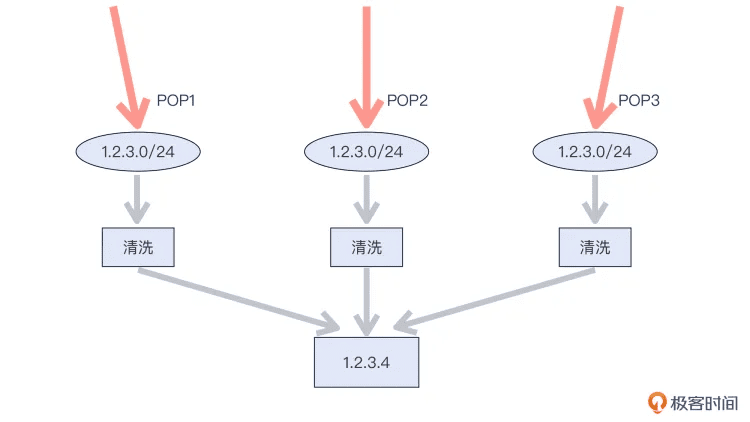
补充:这里的 anycast 一般是作用在网段级别。而在单个 IP 级别的 anycast 应用还较局限,目前主要还是主要应用在基于 UDP 的服务,比如 DNS 服务上。
基于 anycast 的 HTTP 是比较前沿的领域,目前有少数公司已经开始实践,相信在不久的将来,应该会看到越来越多的公司应用 HTTP over anycast。
CDN缓解攻击
与前一点类似,CDN 也是通过“多点分布”来达到防护或者缓解 DDoS 攻击的目的。而且 CDN 服务商一般也会采用 anycast 等策略混合使用,使得其防护 DDoS 的能力更加出色。