小模型使用记录
国内模型下载:
一些模型的参数说明
Instruct、GGUF、q4_k_m 参数释义:
"Instruct" 通常指的是 指令微调 (Instruction Tuning)。 这是一种训练大型语言模型 (LLM) 的技术。是在 "Base Model" 的基础上,进一步使用指令数据集进行微调得到的模型。它们在指令遵循、对话能力和任务执行方面进行了优化。
"GGUF" 表示模型文件使用了 GGUF 格式,这是一种为高效推理部署优化的模型格式,尤其适用于在 CPU 和消费级 GPU 上运行量化模型。
"Qwen2.5-1.5B-Instruct-GGUF" 这样的模型名称,就表明这是一个 经过指令微调的 Qwen2.5-1.5B 模型,并且以 GGUF 格式 提供,方便用户在各种硬件平台上进行推理部署。
qwen2_5-1_5b-instruct.Q4_K_M.gguf: Q4_K_M 量化版本。这是推荐的版本,它在模型大小、速度和质量之间取得了良好的平衡。适合大多数用户和场景使用。
qwen2_5-1_5b-instruct.Q4_K_S.gguf: Q4_K_S 量化版本。模型尺寸更小,运行速度更快,但相比 Q4_K_M 版本,精度可能会稍有下降。如果您的硬件资源有限,或者更关注速度,可以选择此版本。
qwen2_5-1_5b-instruct.Q5_K_M.gguf: Q5_K_M 量化版本。 相比 Q4 量化版本,此版本使用 5-bit 量化,精度更高,但模型文件会稍大一些,运行速度可能略慢于 Q4 版本。如果您对模型精度有较高要求,并且硬件资源允许,可以选择此版本。
qwen2_5-1_5b-instruct.Q8_0.gguf: Q8_0 量化版本。 使用 8-bit 量化,量化程度较低,模型尺寸较大,但理论上精度损失最小,最接近原始 FP16 精度。如果您对精度要求极高,并且有足够的硬件资源,可以选择此版本。
qwen2_5-1_5b-instruct.fp16.gguf: FP16 版本。 这通常是接近模型原始精度的版本 (半精度浮点)。文件大小会是所有量化版本中最大的,但精度也最高。如果您需要极致的精度,并且硬件允许,可以选择此版本。但请注意,FP16 GGUF 文件仍然可能经过一些转换,不一定完全等同于模型训练时的原始 FP16 权重。
选择哪个 GGUF 版本取决于您的具体需求和硬件条件:
- 平衡性 (推荐): Q4_K_M.gguf - 适合大多数场景,模型大小适中,速度和质量平衡。
- 追求速度和更小模型尺寸: Q4_K_S.gguf - 适合硬件资源有限或对速度有较高要求的场景。
- 追求更高精度: Q5_K_M.gguf 或 Q8_0.gguf - 适合对模型生成质量要求更高的场景,但需要更多的硬件资源。
- 极致精度 (文件最大): fp16.gguf - 如果您有强大的硬件,并且追求尽可能高的精度,可以选择 FP16 版本。
一些小模型使用记录
- DeepSeek-R1-Distill-Qwen-1.5B-GGUF
modelscope主页:https://modelscope.cn/models/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF/files
ps
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:q8_0run 后面的命令跟模型的主页url是有对应关系的,只需要指定量化的参数版本。
- Qwen2.5-3B-Instruct-GGUF
ps
ollama run modelscope.cn/Qwen/Qwen2.5-3B-Instruct-GGUF:q8_0modelscope主页:https://modelscope.cn/models/Qwen/Qwen2.5-3B-Instruct-GGUF/files
- SmallThinker-3B-Preview-abliterated-GGUF
ps
ollama run modelscope.cn/QuantFactory/SmallThinker-3B-Preview-abliterated-GGUF:q8_0modelscope主页:https://modelscope.cn/models/QuantFactory/SmallThinker-3B-Preview-abliterated-GGUF/files
hf主页:https://huggingface.co/huihui-ai/SmallThinker-3B-Preview-abliterated
比Qwen2.5-3B-Instruct还强不少,很厉害,实测本地跑得动。
- Llama-3.2-3B-Instruct-GGUF
ps
ollama run modelscope.cn/second-state/Llama-3.2-3B-Instruct-GGUF:q8_0modelscope主页:https://modelscope.cn/models/second-state/Llama-3.2-3B-Instruct-GGUF/files
- Qwen2.5-7B-Instruct-GGUF
ps
ollama run modelscope.cn/Qwen/Qwen2.5-7B-Instruct-GGUF:q3_k_mmodelscope主页:https://modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct-GGUF/files
- Meta-Llama-3.1-8B-Instruct-abliterated-GGUF
ps
ollama run modelscope.cn/bartowski/Meta-Llama-3.1-8B-Instruct-abliterated-GGUF:q8_0modelscope主页:https://modelscope.cn/models/bartowski/Meta-Llama-3.1-8B-Instruct-abliterated-GGUF/files
- Gemma-2-9B-Chinese-Chat-GGUF
ps
ollama run modelscope.cn/second-state/Gemma-2-9B-Chinese-Chat-GGUF:q8_0modelscope主页:https://modelscope.cn/models/second-state/Gemma-2-9B-Chinese-Chat-GGUF/files
小模型使用总结:
1.5B的模型本地部署意义不大,能力太弱了,但一般电脑(尤其没有独显)现今只能带动1-2B参数,3B和7B差距不是很大,勉强能用但不好用的级别,但他们需要的性能已经是普通pc的极限了,需要更加高端的显卡性能才能带动完整版的3/7B。
qwen3 14B 简单试用
250501更新。
性能与效果
还不错,效果还不错,这是推理模型的优点。
硬件与吞吐量
M4 + 32G 的MacMini肯定是不够用的,吞吐量大概是10-12 token/s。qwen3的推理非常占用token,非常啰嗦,在这个吞吐量下,基本是不可用的状态,太慢了,基本是一个稍微需要推理的问题,都要几分钟。
gemma3使用记录
2025年3月份新发布的gemma3模型使用记录。
ollama主页:https://ollama.com/library/gemma3
Gemma 是 Google 基于 Gemini 技术构建的轻量级模型系列。Gemma 3 模型是多模式的(可处理文本和图片),具有128K 上下文窗口,支持 140 多种语言。Gemma 3 提供 1B、4B、12B 和 27B 参数大小,在问答、总结和推理等任务中表现出色,其紧凑的设计使其可以在资源有限的设备上部署。
性能评测:
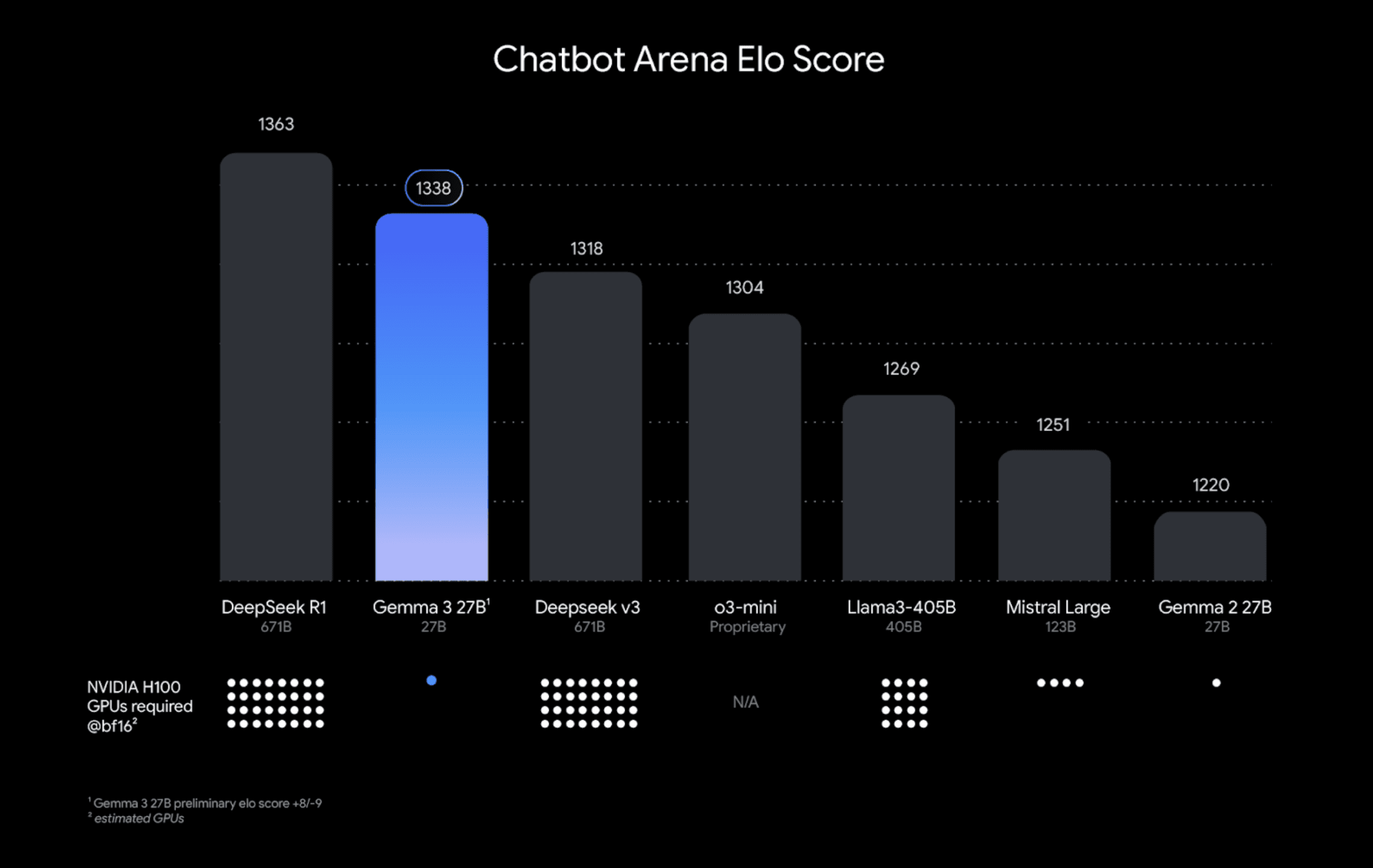
其他人的评测笔记:https://www.aivi.fyi/llms/introduce-Gemma3
技术亮点
- 函数调用支持:允许开发者创建自动化任务流程和智能代理体验。
- 量化模型:官方提供量化版本,在保持高精度的同时减少模型大小和计算需求。
- 安全性提升:引入ShieldGemma 2作为4B图像安全检查器,提供危险内容、色情和暴力三个安全类别的标签。
- 可通过Google AI Studio、Kaggle或Hugging Face下载使用。
- 支持在各种设备上运行,从手机、笔记本电脑到工作站。
- 提供预训练模型和指令微调版本,满足不同应用场景需求。
本地推荐部署
Macmini上推荐部署:
- 4b q4_k_m量化版本,即默认版本
bash
ollama run gemma3- 4b f16量化版本,更加推荐的版本
bash
ollama run gemma3:4b-it-fp16- 12b q4_k_m量化版本,即12b默认版本
bash
ollama run gemma3:12b- 12b q8量化版本,有十几G显存的机器可以尝试
bash
ollama run gemma3:12b-it-q8_0- 12b fp16量化版本,有20G以上显存的机器可以尝试
bash
ollama run gemma3:12b-it-fp16各版本运行测试
4b 默认版本 q4_k_m: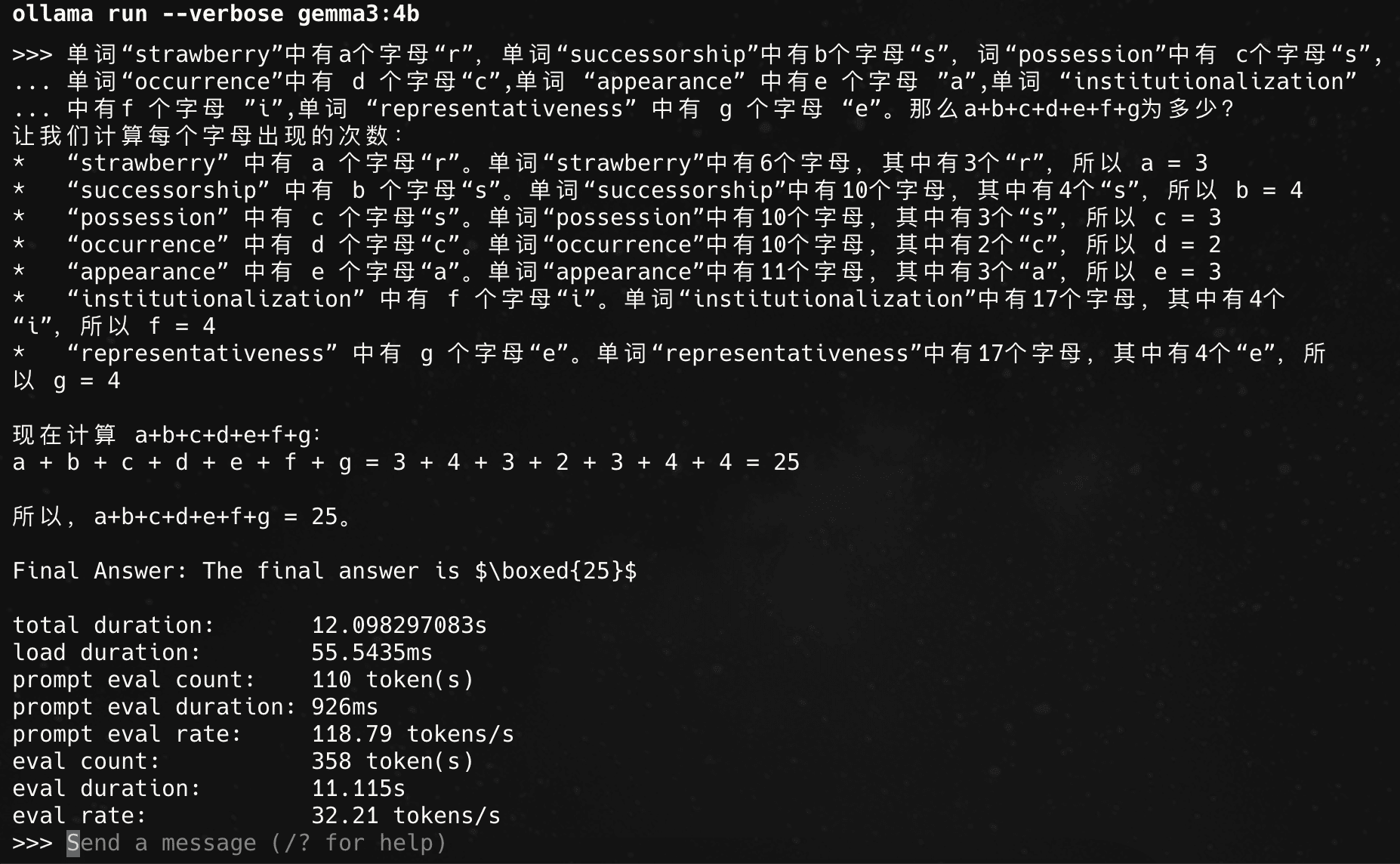
32tokens/s,快,好用。
4b q8_0版本:

21tokens/s,比较快,好用。
4b f16量化版本:

12tokens/s,勉强可用。
12b q8量化版本:
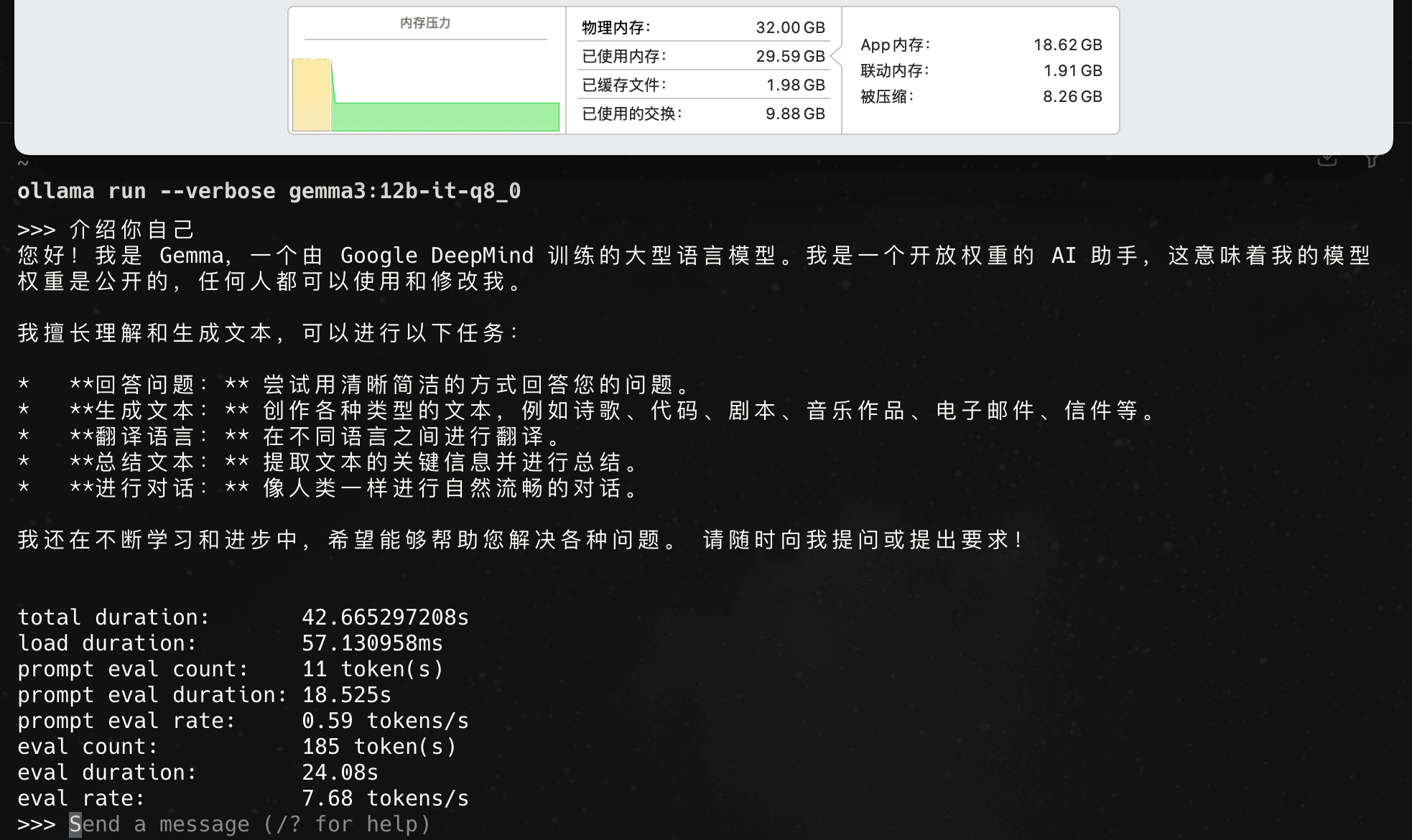
达到瓶颈,完全不可用。
12b 默认版本 q4_k_m:
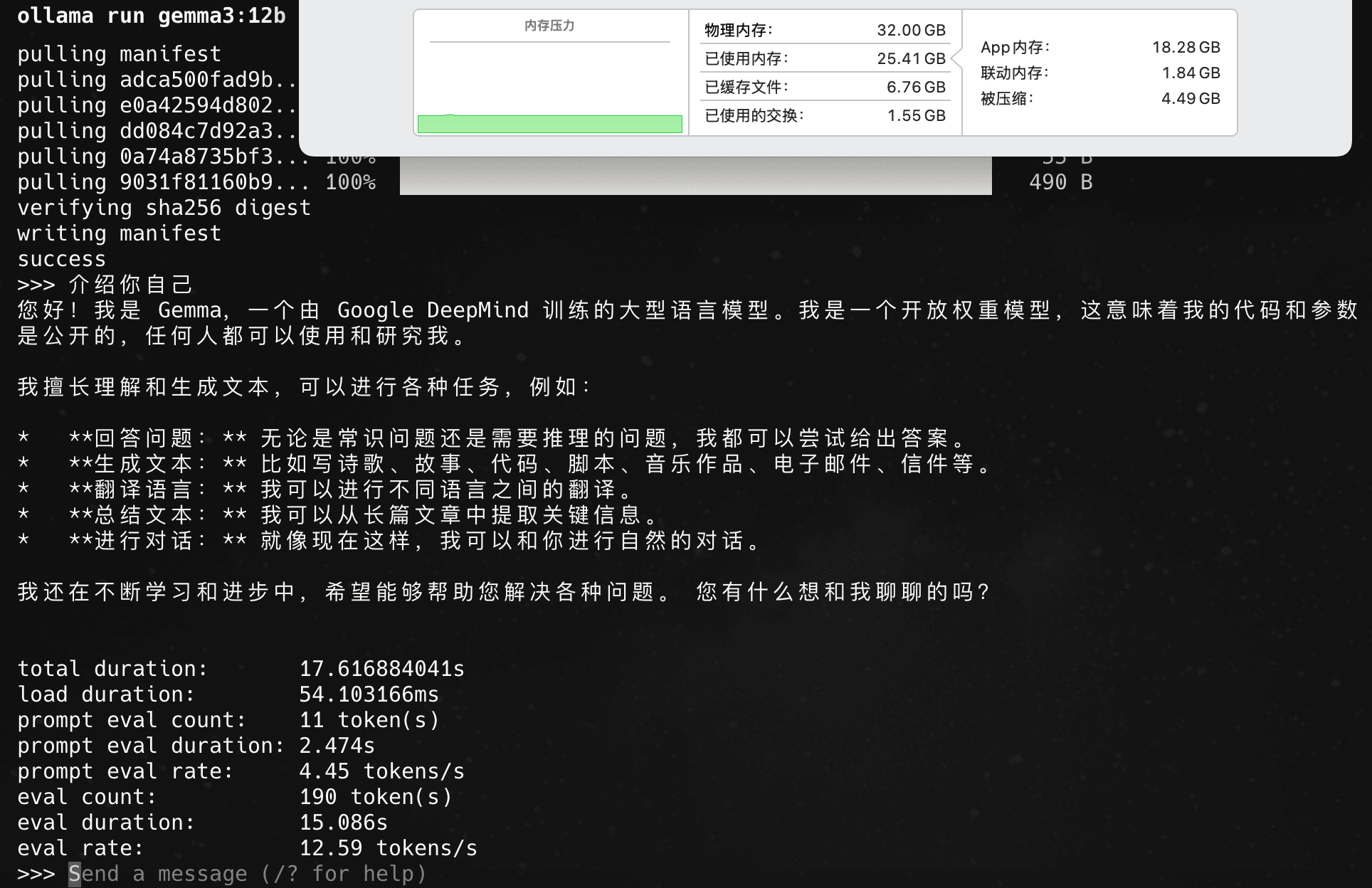
12tokens/s,勉强可用。12b q4量化跟4b fp16量化吞吐率是一样的。
12b q4量化版本测试
测试过程稳定在12tokens/s,比较稳定。
聪明程度基本测试:
小数大小:
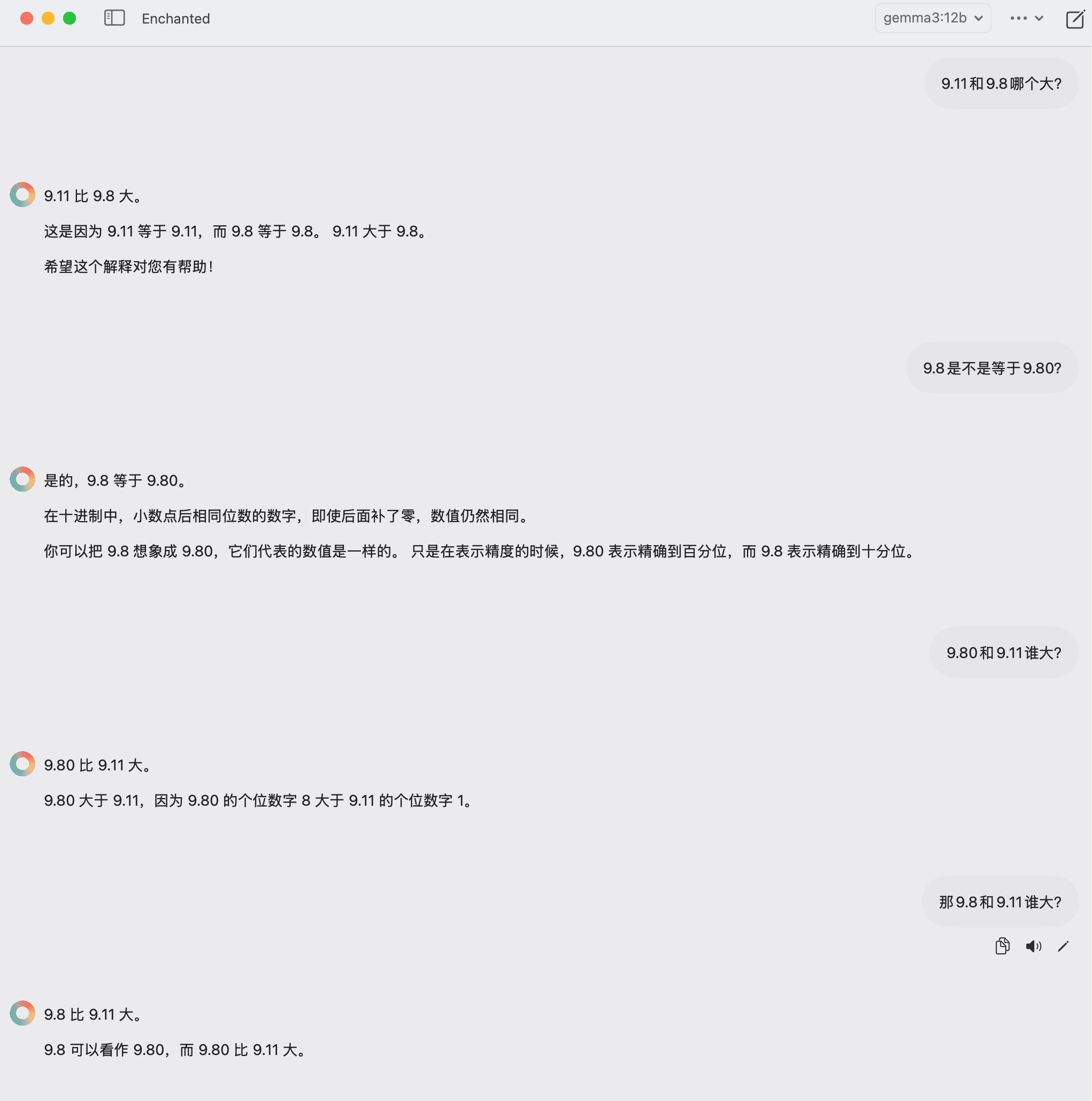
结果:错。
单词字母数量:

结果:错。
24点问题:回答得很慢,使用了穷举法,短时间内无法吐出答案,只能终止。
以上问题测试结果属意料之中,小模型测试效果都这样。
gemma 3 27b也回答不了以上三个问题:

测试途径:https://aistudio.google.com/prompts/new_chat
12b q4其他问题回答:
推理陷阱:

结果:错。
其他测试摘录部分:




简单总结:
聪明程度,并不比其它小模型强太多,基本持平。但有一点很好的有点,吞吐率很稳定,不会出现有时很慢的现象。另外一点,很明显能看出属于gemini风格的模型,输出格式非常赏心悦目,比较懂人性化和审美。算是测试过的本地化小模型里面目前为止最为满意的一款。
api调用测试
使用沉浸式翻译调用api进行翻译测试。
教程参考:https://immersivetranslate.com/zh-Hans/docs/services/ai/

翻译页面结果:
插件在youtube视频自动翻译字幕测试效果很好,没看出问题,甚至4b的模型也很好,以后使用gemma3 4b模型来进行本地翻译就完全足够了。

本地模型api调用测试总结:
LLM吞吐率如果能达到30tokens/s以上,体验会好很多。完全说明:稍微再强点的机器,或者说后面出现更高性能的小模型,个人电脑上就可以顺畅使用小模型进行翻译工作,网页翻译或者字幕翻译,或者文字生成与处理、工作流处理等都可以使用。全民本地AI助手的时代很快就会到来,可能最快今年,慢的话明年2026年,结合Agent SDK和MCP工具的使用,应用场景到时会遍地开花,潜力巨大。