性能优化-CPU相关
极客时间《Linux性能优化实战》倪朋飞
平均负载
平均负载概念
简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。这里我先解释下,可运行状态和不可中断状态这俩词儿。
所谓可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。 不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。
所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
因此,可以简单理解为,平均负载其实就是平均活跃进程数。平均活跃进程数,直观上的理解就是单位时间内的活跃进程数,但它实际上是活跃进程数的指数衰减平均值。这个“指数衰减平均”的详细含义你不用计较,这只是系统的一种更快速的计算方式,你把它直接当成活跃进程数的平均值也没问题。
既然平均的是活跃进程数,那么最理想的,就是每个 CPU 上都刚好运行着一个进程,这样每个 CPU 都得到了充分利用。比如当平均负载为 2 时,意味着什么呢?
- 在只有 2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。
- 在 4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。
- 而在只有 1 个 CPU 的系统中,则意味着有一半的进程竞争不到 CPU。
平均负载为多少时合理
讲完了什么是平均负载,现在我们再回到最开始的例子,不知道你能否判断出,在 uptime 命令的结果里,那三个时间段的平均负载数,多大的时候能说明系统负载高?或是多小的时候就能说明系统负载很低呢?
我们知道,平均负载最理想的情况是等于 CPU 个数。所以在评判平均负载时,首先你要知道系统有几个 CPU,这可以通过 top 命令或者从文件 /proc/cpuinfo 中读取,比如:
bash
grep 'model name' /proc/cpuinfo | wc -l现在大多数CPU有超线程能力,在计算和评估平均负载的时候,CPU的核数是指物理核数,还是超线程功能的逻辑核数?
答:这里指的是逻辑核数。
有了 CPU 个数,我们就可以判断出,当平均负载比 CPU 个数还大的时候,系统已经出现了过载。
不过,且慢,新的问题又来了。我们在例子中可以看到,平均负载有三个数值,到底该参考哪一个呢?
实际上,都要看。三个不同时间间隔的平均值,其实给我们提供了,分析系统负载趋势的数据来源,让我们能更全面、更立体地理解目前的负载状况。
打个比方,就像初秋时北京的天气,如果只看中午的温度,你可能以为还在 7 月份的大夏天呢。但如果你结合了早上、中午、晚上三个时间点的温度来看,基本就可以全方位了解这一天的天气情况了。
同样的,前面说到的 CPU 的三个负载时间段也是这个道理。
- 如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
- 但如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。
- 反过来,如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化了。
这里我再举个例子,假设我们在一个单 CPU 系统上看到平均负载为 1.73,0.60,7.98,那么说明在过去 1 分钟内,系统有 73% 的超载,而在 15 分钟内,有 698% 的超载,从整体趋势来看,系统的负载在降低。
那么,在实际生产环境中,平均负载多高时,需要我们重点关注呢?
在我看来,当平均负载高于 CPU 数量 70% 的时候,你就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。
但 70% 这个数字并不是绝对的,最推荐的方法,还是把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势。当发现负载有明显升高趋势时,比如说负载翻倍了,你再去做分析和调查。
平均负载与 CPU 使用率
现实工作中,我们经常容易把平均负载和 CPU 使用率混淆,所以在这里,我也做一个区分。
可能你会疑惑,既然平均负载代表的是活跃进程数,那平均负载高了,不就意味着 CPU 使用率高吗?
我们还是要回到平均负载的含义上来,平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O的进程。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致- 的;
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很- 高;
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
下面案例中对以上三种场景进行模拟分析。
平均负载案例分析
下面,我们以三个示例分别来看这三种情况,并用 iostat、mpstat、pidstat 等工具,找出平均负载升高的根源。
预先安装 stress 和 sysstat 包:
bash
sudo apt install stress sysstatstress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
而 sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能。我们的案例会用到这个包的两个命令 mpstat 和 pidstat。
- mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
- pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
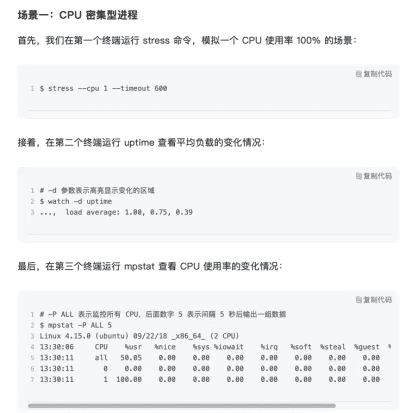
stress模拟cpu密集型进程
- stress --cpu 1 --timeout 6000
- watch -d uptime
- mpstat -P ALL 5 1
- pidstat -u 5 1
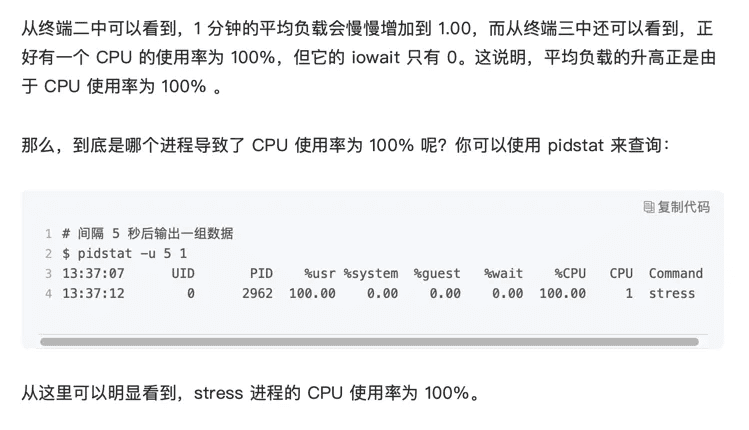
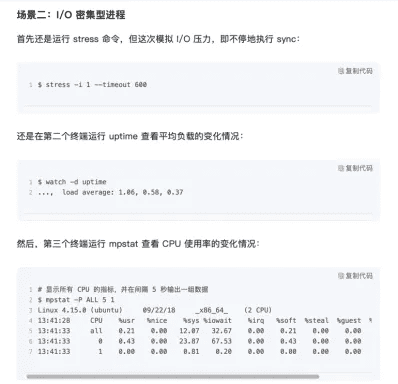
stress模拟I/O密集型进程
- stress -i 1 --timeout 6000
- watch -d uptime
- mpstat -P ALL 5 1
- pidstat -u 5 1
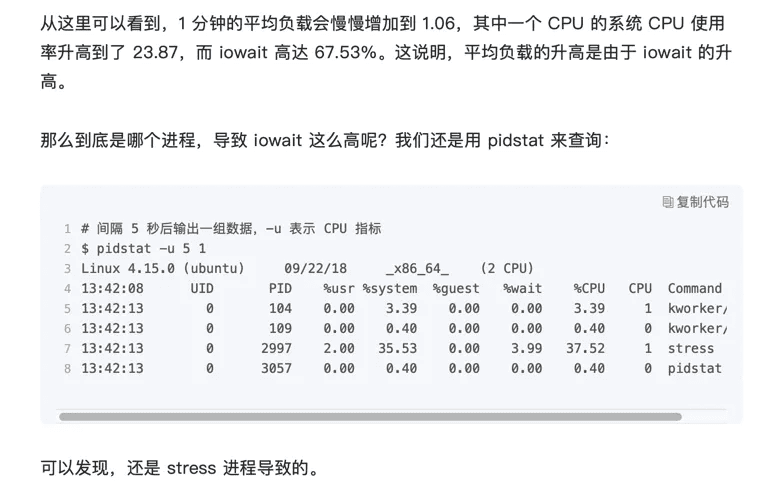
注意:在虚拟机中实验结果可能没那么明显,虚拟机中iowait无法升高的问题,是因为案例中stress使用的是 sync() 系统调用,它的作用是刷新缓冲区内存到磁盘中。对于新安装的虚拟机,缓冲区可能比较小,无法产生大的IO压力,这样大部分就都是系统调用的消耗了。虚拟机和物理机,还是有区别的,某些场景下,请勿忽视这点。
stress模拟等待被执行的大量进程
这种慎用,很可能把机器直接卡死。-c 设置得比cpu逻辑核数多就可以,大越多越卡,尽量是比核数稍微多一点。比如4核的话-c 设置为5。仍然会卡,但勉强能操作。
- stress -c 8 --timeout 6000
- watch -d uptime
- mpstat -P ALL 5 1
- pidstat -u 5 1

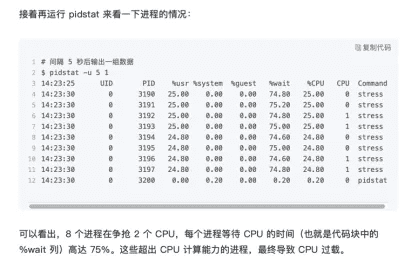
%wait表示进程等待cpu的时间。chatglm的理解是对的,kimi的结果是错的,ai工具的结果不一样可靠,需要自己综合分析判定。

平均负载知识小结
分析完这三个案例,我再来归纳一下平均负载的理解。
平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
- 平均负载高有可能是 CPU 密集型进程导致的;
- 平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
- 当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源。
最实用的工具pidstat。
bash
pidstat -u 5每隔5秒输出一次结果:
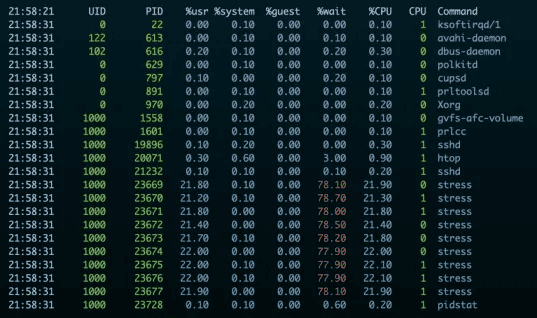
重要参数,进程名,所在cpu,cpu使用率,cpu等待(wait,等待io或者等待被cpu执行?暂按照上面解释理解,应该理解为等待cpu执行)。
此外,常用的还有-r 内存,-d 磁盘io 两个参数。
CPU使用率
查看cpu使用率,一般用top和ps工具。
- top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。
- ps 则只显示了每个进程的资源使用情况。
top分析:
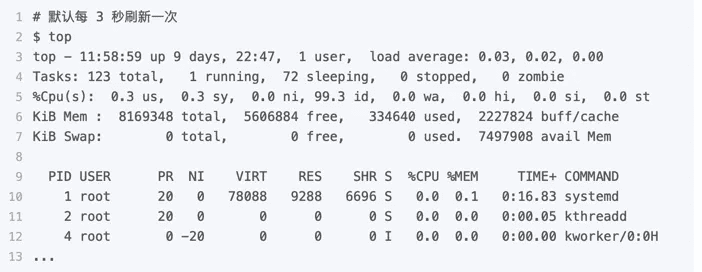
这个输出结果中,第三行 %Cpu 就是系统的 CPU 使用率,具体每一列的含义上一节都讲过,只是把 CPU 时间变换成了 CPU 使用率,我就不再重复讲了。
不过需要注意,top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。
继续往下看,空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的 CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境中,它还包括了运行虚拟机占用的 CPU。
所以,到这里我们可以发现, top 并没有细分进程的用户态 CPU 和内核态 CPU。那要怎么查看每个进程的详细情况呢?你应该还记得上一节用到的 pidstat 吧,它正是一个专门分析每个进程 CPU 使用情况的工具。

比如,下面的 pidstat 命令,就间隔 1 秒展示了进程的 5 组 CPU 使用率,包括:
- 用户态 CPU 使用率 (%usr);
- 内核态 CPU 使用率(%system);
- 运行虚拟机 CPU 使用率(%guest);
- 等待 CPU 使用率(%wait);
- 以及总的 CPU 使用率(%CPU)。
最后的 Average 部分,还计算了 5 组数据的平均值。
找出cpu占用最高的进程后,哪种工具适合在第一时间分析进程的 CPU 问题呢?我的推荐是 perf。perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
使用 perf 分析 CPU 性能问题,我来说两种最常见、也是我最喜欢的用法。
bash
sudo apt install linux-tools-common此时如果perf top提示使用不了,则按安装:
bash
sudo apt install linux-tools-genericperf 需要root才能使用,普通用户没有权限。
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:

输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了 833 个 CPU 时钟事件,而总事件数则为 97742399。
另外,采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
- 第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表- 示。
- 第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
- 第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
- 最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
还是以上面的输出为例,我们可以看到,占用 CPU 时钟最多的是 perf 工具自身,不过它的比例也只有 7.28%,说明系统并没有 CPU 性能问题。 perf top 的使用你应该很清楚了吧。
接着再来看第二种常见用法,也就是 perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。

在实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
案例分析,排查进程,进程哪个函数导致。
预先安装 docker、sysstat、perf、ab 等工具,如
bash
sudo apt install docker.io sysstat linux-tools-common apache2-utils我先简单介绍一下这次新使用的工具 ab。ab(apache bench)是一个常用的 HTTP 服务性能测试工具,这里用来模拟 Ngnix 的客户端。由于 Nginx 和 PHP 的配置比较麻烦,我把它们打包成了两个 Docker 镜像,这样只需要运行两个容器,就可以得到模拟环境。
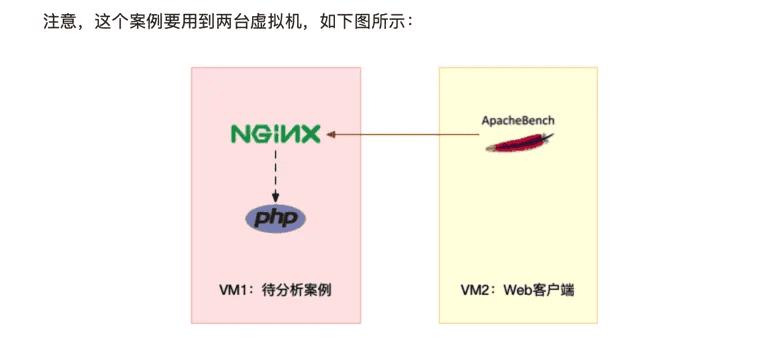
你可以看到,其中一台用作 Web 服务器,来模拟性能问题;另一台用作 Web 服务器的客户端,来给 Web 服务增加压力请求。使用两台虚拟机是为了相互隔离,避免“交叉感染”。
接下来,我们打开两个终端,分别 SSH 登录到两台机器上,并安装上面提到的工具。
还是同样的“配方”。下面的所有命令,都默认假设以 root 用户运行,如果你是普通用户身份登陆系统,一定要先运行 sudo su root 命令切换到 root 用户。到这里,准备工作就完成了。
不过,操作之前,我还想再说一点。这次案例中 PHP 应用的核心逻辑比较简单,大部分人一眼就可以看出问题,但你要知道,实际生产环境中的源码就复杂多了。
所以,我希望你在按照步骤操作之前,先不要查看源码(避免先入为主),而是把它当成一个黑盒来分析。这样,你可以更好地理解整个解决思路,怎么从系统的资源使用问题出发,分析出瓶颈所在的应用、以及瓶颈在应用中的大概位置。
操作和分析
接下来,我们正式进入操作环节。
首先,在第一个终端执行下面的命令来运行 Nginx 和 PHP 应用:
bash
docker run --name nginx -p 10000:80 -itd feisky/nginx
docker run --name phpfpm -itd --network container:nginx feisky/php-fpm然后,在第二个终端使用 curl 访问 http://[VM1 的 IP]:10000,确认 Nginx 已正常启动。你应该可以看到 It works! 的响应。
bash
# 192.168.0.10 是第一台虚拟机的 IP 地址
$ curl http://192.168.0.10:10000/
It works!接着,我们来测试一下这个 Nginx 服务的性能。在第二个终端运行下面的 ab 命令:
bash
# 并发 10 个请求测试 Nginx 性能,总共测试 100 个请求
$ ab -c 10 -n 100 http://192.168.0.10:10000/
This is ApacheBench, Version 2.3 <$Revision: 1706008 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd,
...
Requests per second: 11.63 [#/sec] (mean)
Time per request: 859.942 [ms] (mean)
...从 ab 的输出结果我们可以看到,Nginx 能承受的每秒平均请求数只有 11.63。你一定在吐槽,这也太差了吧。那到底是哪里出了问题呢?我们用 top 和 pidstat 再来观察下。
这次,我们在第二个终端,将测试的请求总数增加到 10000。这样当你在第一个终端使用性能分析工具时, Nginx 的压力还是继续。
继续在第二个终端,运行 ab 命令:
bash
ab -c 10 -n 10000 http://10.240.0.5:10000/接着,回到第一个终端运行 top 命令,并按下数字 1 ,切换到每个 CPU 的使用率:
$ top
...
%Cpu0 : 98.7 us, 1.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 99.3 us, 0.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21514 daemon 20 0 336696 16384 8712 R 41.9 0.2 0:06.00 php-fpm
21513 daemon 20 0 336696 13244 5572 R 40.2 0.2 0:06.08 php-fpm
21515 daemon 20 0 336696 16384 8712 R 40.2 0.2 0:05.67 php-fpm
21512 daemon 20 0 336696 13244 5572 R 39.9 0.2 0:05.87 php-fpm
21516 daemon 20 0 336696 16384 8712 R 35.9 0.2 0:05.61 php-fpm这里可以看到,系统中有几个 php-fpm 进程的 CPU 使用率加起来接近 200%;而每个 CPU 的用户使用率(us)也已经超过了 98%,接近饱和。这样,我们就可以确认,正是用户空间的 php-fpm 进程,导致 CPU 使用率骤升。
那再往下走,怎么知道是 php-fpm 的哪个函数导致了 CPU 使用率升高呢?我们来用 perf 分析一下。在第一个终端运行下面的 perf 命令:
bash
# -g 开启调用关系分析,-p 指定 php-fpm 的进程号 21515
$ perf top -g -p 21515按方向键切换到 php-fpm,再按下回车键展开 php-fpm 的调用关系,你会发现,调用关系最终到了 sqrt 和 add_function。看来,我们需要从这两个函数入手了。
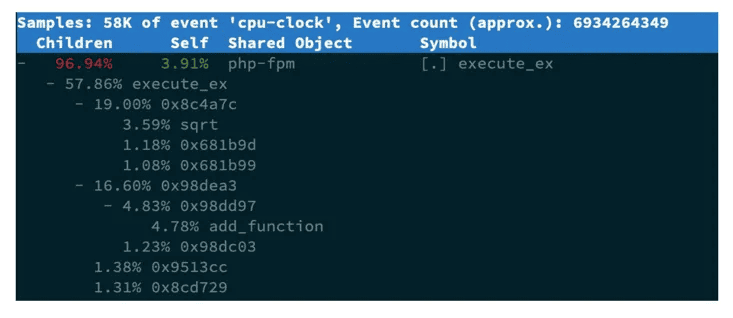
我们拷贝出 Nginx 应用的源码,看看是不是调用了这两个函数:
# 从容器 phpfpm 中将 PHP 源码拷贝出来
$ docker cp phpfpm:/app .
# 使用 grep 查找函数调用
$ grep sqrt -r app/ # 找到了 sqrt 调用
app/index.php: $x += sqrt($x);
$ grep add_function -r app/ # 没找到 add_function 调用,这其实是 PHP 内置函数OK,原来只有 sqrt 函数在 app/index.php 文件中调用了。那最后一步,我们就该看看这个文件的源码了:
$ cat app/index.php
<?php
// test only.
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "It works!"呀,有没有发现问题在哪里呢?我想你要笑话我了,居然犯了一个这么傻的错误,测试代码没删就直接发布应用了。为了方便你验证优化后的效果,我把修复后的应用也打包成了一个 Docker 镜像,你可以在第一个终端中执行下面的命令来运行它:
# 停止原来的应用
$ docker rm -f nginx phpfpm
# 运行优化后的应用
$ docker run --name nginx -p 10000:80 -itd feisky/nginx:cpu-fix
$ docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:cpu-fix接着,到第二个终端来验证一下修复后的效果。首先 Ctrl+C 停止之前的 ab 命令后,再运行下面的命令:
$ ab -c 10 -n 10000 http://10.240.0.5:10000/
...
Complete requests: 10000
Failed requests: 0
Total transferred: 1720000 bytes
HTML transferred: 90000 bytes
Requests per second: 2237.04 [#/sec] (mean)
Time per request: 4.470 [ms] (mean)
Time per request: 0.447 [ms] (mean, across all concurrent requests)
Transfer rate: 375.75 [Kbytes/sec] received
...从这里你可以发现,现在每秒的平均请求数,已经从原来的 11 变成了 2237。
你看,就是这么很傻的一个小问题,却会极大的影响性能,并且查找起来也并不容易吧。当然,找到问题后,解决方法就简单多了,删除测试代码就可以了。
注意:容器中,执行perf top -g -p (php-fpm进程号),发现不了sqrt函数 只看到地址而不是函数名是由于应用程序运行在容器中,它的依赖也都在容器内部,故而perf无法找到PHP符号表。一个简单的解决方法是使用perf record生成perf.data拷贝到容器内部 perf report。
cpu使用率小结:
CPU 使用率是最直观和最常用的系统性能指标,更是我们在排查性能问题时,通常会关注的第一个指标。所以我们更要熟悉它的含义,尤其要弄清楚用户(%user)、Nice(%nice)、系统(%system) 、等待 I/O(%iowait) 、中断(%irq)以及软中断(%softirq)这几种不同 CPU 的使用率。比如说:
- 用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
- 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
- I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
没有明显的高cpu占用的情形:
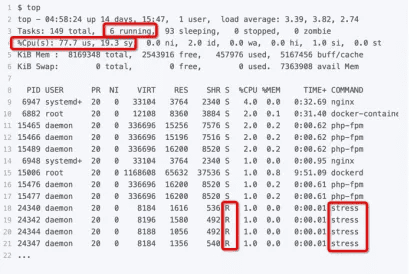
这次从头开始看 top 的每行输出,咦?Tasks 这一行看起来有点奇怪,就绪队列中居然有 6 个 Running 状态的进程(6 running),是不是有点多呢? 回想一下 ab 测试的参数,并发请求数是 5。再看进程列表里, php-fpm 的数量也是 5,再加上 Nginx,好像同时有 6 个进程也并不奇怪。但真的是这样吗?
再仔细看进程列表,这次主要看 Running(R) 状态的进程。你有没有发现, Nginx 和所有的 php-fpm 都处于 Sleep(S)状态,而真正处于 Running(R)状态的,却是几个 stress 进程。这几个 stress 进程就比较奇怪了,需要我们做进一步的分析。
至于 stress,我们前面提到过,它是一个常用的压力测试工具。它的 PID 在不断变化中,看起来像是被其他进程调用的短时进程。要想继续分析下去,还得找到它们的父进程。
要怎么查找一个进程的父进程呢?没错,用 pstree 就可以用树状形式显示所有进程之间的关系:

碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况。
- 第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。
- 第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU。
对于这类进程,我们可以用 pstree 或者 execsnoop 找到它们的父进程,再从父进程所在的应用入手,排查问题的根源。
CPU性能指标综述
首先,最容易想到的应该是 CPU 使用率,这也是实际环境中最常见的一个性能指标。 CPU 使用率描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户 CPU、系统 CPU、等待 I/O CPU、软中断和硬中断等。
- 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
- 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长(I/O比较繁忙)。
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
- 除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
第二个比较容易想到的,应该是平均负载(Load Average),也就是系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。
理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,就表示负载比较重了。
第三个,也是在专栏学习前你估计不太会注意到的,进程上下文切换,包括:
- 无法获取资源而导致的自愿上下文切换;
- 被系统强制调度导致的非自愿上下文切换。
上下文切换,本身是保证 Linux 正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的 CPU 时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
除了上面几种,还有一个指标,CPU 缓存的命中率。由于 CPU 发展的速度远快于内存的发展,CPU 的处理速度就比内存的访问速度快得多。这样,CPU 在访问内存的时候,免不了要等待内存的响应。为了协调这两者巨大的性能差距,CPU 缓存(通常是多级缓存)就出现了。
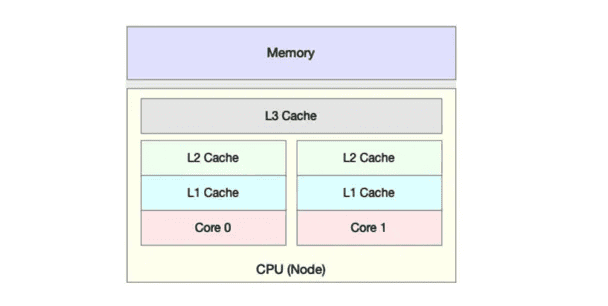
就像上面这张图显示的,CPU 缓存的速度介于 CPU 和内存之间,缓存的是热点的内存数据。根据不断增长的热点数据,这些缓存按照大小不同分为 L1、L2、L3 等三级缓存,其中 L1 和 L2 常用在单核中, L3 则用在多核中。
从 L1 到 L3,三级缓存的大小依次增大,相应的,性能依次降低(当然比内存还是好得多)。而它们的命中率,衡量的是 CPU 缓存的复用情况,命中率越高,则表示性能越好。
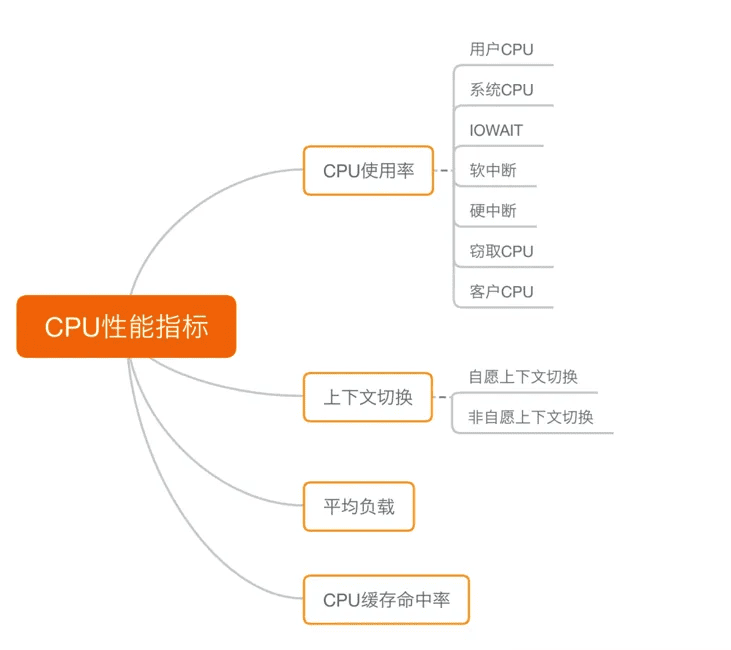
这些指标都很有用,需要我们熟练掌握,所以我总结成了一张图,帮你分类和记忆。你可以保存打印下来,随时查看复习,也可以当成 CPU 性能分析的“指标筛选”清单。
CPU性能指标分类
性能指标模拟与查看工具
掌握了 CPU 的性能指标,我们还需要知道,怎样去获取这些指标,也就是工具的使用。 你还记得前面案例都用了哪些工具吗?这里我们也一起回顾一下 CPU 性能工具。
首先,平均负载的案例。我们先用 uptime, 查看了系统的平均负载;而在平均负载升高后,又用 mpstat 和 pidstat ,分别观察了每个 CPU 和每个进程 CPU 的使用情况,进而找出了导致平均负载升高的进程,也就是我们的压测工具 stress和stress-ng。

第二个,上下文切换的案例。我们先用 vmstat ,查看了系统的上下文切换次数和中断次数;然后通过 pidstat ,观察了进程的自愿上下文切换和非自愿上下文切换情况;最后通过 pidstat ,观察了线程的上下文切换情况,找出了上下文切换次数增多的根源,也就是我们的基准测试工具 sysbench。
第三个,进程 CPU 使用率升高的案例。我们先用 top ,查看了系统和进程的 CPU 使用情况,发现 CPU 使用率升高的进程是 php-fpm;再用 perf top ,观察 php-fpm 的调用链,最终找出 CPU 升高的根源,也就是库函数 sqrt() 。
第四个,系统的 CPU 使用率升高的案例。我们先用 top 观察到了系统 CPU 升高,但通过 top 和 pidstat ,却找不出高 CPU 使用率的进程。于是,我们重新审视 top 的输出,又从 CPU 使用率不高但处于 Running 状态的进程入手,找出了可疑之处,最终通过 perf record 和 perf report ,发现原来是短时进程在捣鬼。
另外,对于短时进程,我还介绍了一个专门的工具 execsnoop,它可以实时监控进程调用的外部命令。
第五个,不可中断进程和僵尸进程的案例。我们先用 top 观察到了 iowait 升高的问题,并发现了大量的不可中断进程和僵尸进程;接着我们用 dstat 发现是这是由磁盘读导致的,于是又通过 pidstat 找出了相关的进程。但我们用 strace 查看进程系统调用却失败了,最终还是用 perf 分析进程调用链,才发现根源在于磁盘直接 I/O 。
最后一个,软中断的案例。我们通过 top 观察到,系统的软中断 CPU 使用率升高;接着查看 /proc/softirqs, 找到了几种变化速率较快的软中断;然后通过 sar 命令,发现是网络小包的问题,最后再用 tcpdump ,找出网络帧的类型和来源,确定是一个 SYN FLOOD 攻击导致的。
到这里,估计你已经晕了吧,原来短短几个案例,我们已经用过十几种 CPU 性能工具了,而且每种工具的适用场景还不同呢!这么多的工具要怎么区分呢?在实际的性能分析中,又该怎么选择呢?
我的经验是,从两个不同的维度来理解它们,做到活学活用。
活学活用,把性能指标和性能工具联系起来:
第一个维度,从 CPU 的性能指标出发。也就是说,当你要查看某个性能指标时,要清楚知道哪些工具可以做到。
根据不同的性能指标,对提供指标的性能工具进行分类和理解。这样,在实际排查性能问题时,你就可以清楚知道,什么工具可以提供你想要的指标,而不是毫无根据地挨个尝试,撞运气。
其实,我在前面的案例中已经多次用到了这个思路。比如用 top 发现了软中断 CPU 使用率高后,下一步自然就想知道具体的软中断类型。那在哪里可以观察各类软中断的运行情况呢?当然是 proc 文件系统中的 /proc/softirqs 这个文件。
紧接着,比如说,我们找到的软中断类型是网络接收,那就要继续往网络接收方向思考。系统的网络接收情况是什么样的?什么工具可以查到网络接收情况呢?在我们案例中,用的正是 dstat。
虽然你不需要把所有工具背下来,但如果能理解每个指标对应的工具的特性,一定更高效、更灵活地使用。这里,我把提供 CPU 性能指标的工具做成了一个表格,方便你梳理关系和理解记忆,当然,你也可以当成一个“指标工具”指南来使用。
根据CPU性能指标查找工具
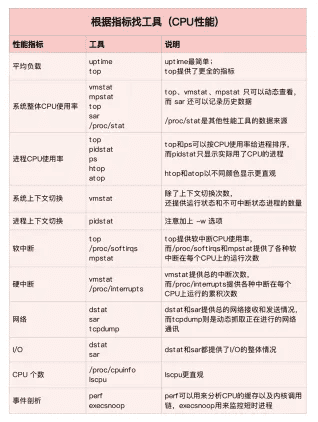
第二个维度,从工具出发。也就是当你已经安装了某个工具后,要知道这个工具能提供哪些指标。
这在实际环境特别是生产环境中也是非常重要的,因为很多情况下,你并没有权限安装新的工具包,只能最大化地利用好系统中已经安装好的工具,这就需要你对它们有足够的了解。
具体到每个工具的使用方法,一般都支持丰富的配置选项。不过不用担心,这些配置选项并不用背下来。你只要知道有哪些工具、以及这些工具的基本功能是什么就够了。真正要用到的时候, 通过 man 命令,查它们的使用手册就可以了。
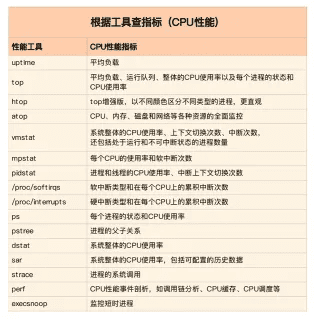
同样的,我也将这些常用工具汇总成了一个表格,方便你区分和理解,自然,你也可以当成一个“工具指标”指南使用,需要时查表即可。
根据工具查找CPU性能指标
指标关联与快速排查
虽然 CPU 的性能指标比较多,但要知道,既然都是描述系统的 CPU 性能,它们就不会是完全孤立的,很多指标间都有一定的关联。想弄清楚性能指标的关联性,就要通晓每种性能指标的工作原理。这也是为什么我在介绍每个性能指标时,都要穿插讲解相关的系统原理,希望你能记住这一点。
举个例子,用户 CPU 使用率高,我们应该去排查进程的用户态而不是内核态。因为用户 CPU 使用率反映的就是用户态的 CPU 使用情况,而内核态的 CPU 使用情况只会反映到系统 CPU 使用率上。
你看,有这样的基本认识,我们就可以缩小排查的范围,省时省力。
所以,为了缩小排查范围,我通常会先运行几个支持指标较多的工具,如 top、vmstat 和 pidstat 。为什么是这三个工具呢?仔细看看下面这张图,你就清楚了。
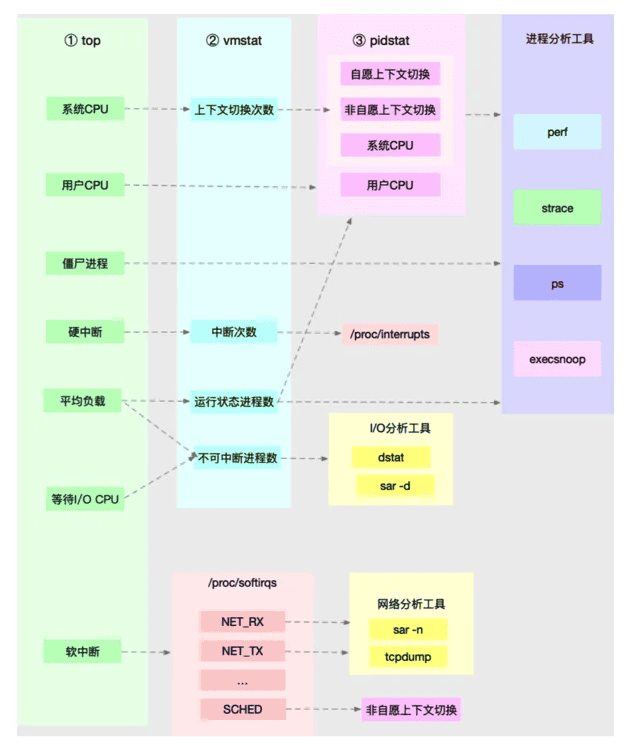
这张图里,我列出了 top、vmstat 和 pidstat 分别提供的重要的 CPU 指标,并用虚线表示关联关系,对应出了性能分析下一步的方向。 通过这张图你可以发现,这三个命令,几乎包含了所有重要的 CPU 性能指标,比如:
- 从 top 的输出可以得到各种 CPU 使用率以及僵尸进程和平均负载等信息。
- 从 vmstat 的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进程数。
- 从 pidstat 的输出可以得到进程的用户 CPU 使用率、系统 CPU 使用率、以及自愿上下文切换和非自愿上下文切换情况。
另外,这三个工具输出的很多指标是相互关联的,所以,我也用虚线表示了它们的关联关系,举几个例子你可能会更容易理解。
第一个例子,pidstat 输出的进程用户 CPU 使用率升高,会导致 top 输出的用户 CPU 使用率升高。所以,当发现 top 输出的用户 CPU 使用率有问题时,可以跟 pidstat 的输出做对比,观察是否是某个进程导致的问题。
而找出导致性能问题的进程后,就要用进程分析工具来分析进程的行为,比如使用strace 分析系统调用情况,以及使用 perf 分析调用链中各级函数的执行情况。
第二个例子,top 输出的平均负载升高,可以跟 vmstat 输出的运行状态和不可中断状态的进程数做对比,观察是哪种进程导致的负载升高。
- I/O 的分析,也就是用 dstat 或 sar 等工具,进一步分析 I/O 的情况。
- 如果是运行状态进程数增多了,那就需要回到 top 和 pidstat,找出这些处于运行状态的到底是什么进程,然后再用进程分析工具,做进一步分析。
最后一个例子,当发现 top 输出的软中断 CPU 使用率升高时,可以查看 /proc/softirqs 文件中各种类型软中断的变化情况,确定到底是哪种软中断出的问题。比如,发现是网络接收中断导致的问题,那就可以继续用网络分析工具 sar 和 tcpdump 来分析。
注意,我在这个图中只列出了最核心的几个性能工具,并没有列出所有。这么做,一方面是不想用大量的工具列表吓到你。在学习之初就接触所有或核心或小众的工具,不见得是好事。另一方面,是希望你能先把重心放在核心工具上,毕竟熟练掌握它们,就可以解决大多数问题。
所以,你可以保存下这张图,作为 CPU 性能分析的思路图谱。从最核心的这几个工具开始,通过我提供的那些案例,自己在真实环境里实践,拿下它们。
cpu性能优化要点注意
不要局限在单一维度的指标上,你至少要从应用程序和系统资源这两个维度,分别选择不同的指标。比如,以 Web 应用为例:
- 应用程序的维度,我们可以用吞吐量和请求延迟来评估应用程序的性能。
- 系统资源的维度,我们可以用 CPU 使用率来评估系统的 CPU 使用情况。
之所以从这两个不同维度选择指标,主要是因为应用程序和系统资源这两者间相辅相成的关系。
- 好的应用程序是性能优化的最终目的和结果,系统优化总是为应用程序服务的。所以,必须要使用应用程序的指标,来评估性能优化的整体效果。
- 系统资源的使用情况是影响应用程序性能的根源。所以,需要用系统资源的指标,来观察和分析瓶颈的来源。
至于接下来的两个步骤,主要是为了对比优化前后的性能,更直观地呈现效果。如果你的第一步,是从两个不同维度选择了多个指标,那么在性能测试时,你就需要获得这些指标的具体数值。
还是以刚刚的 Web 应用为例,对应上面提到的几个指标,我们可以选择 ab 等工具,测试 Web 应用的并发请求数和响应延迟。而测试的同时,还可以用 vmstat、pidstat 等性能工具,观察系统和进程的 CPU 使用率。这样,我们就同时获得了应用程序和系统资源这两个维度的指标数值。
不过,在进行性能测试时,有两个特别重要的地方你需要注意下。
第一,要避免性能测试工具干扰应用程序的性能。通常,对 Web 应用来说,性能测试工具跟目标应用程序要在不同的机器上运行。
比如,在之前的 Nginx 案例中,我每次都会强调要用两台虚拟机,其中一台运行 Nginx 服务,而另一台运行模拟客户端的工具,就是为了避免这个影响。
第二,避免外部环境的变化影响性能指标的评估。这要求优化前、后的应用程序,都运行在相同配置的机器上,并且它们的外部依赖也要完全一致。
比如还是拿 Nginx 来说,就可以运行在同一台机器上,并用相同参数的客户端工具来进行性能测试。
多个性能问题同时存在,要怎么选择?
再来看第二个问题,开篇词里我们就说过,系统性能总是牵一发而动全身,所以性能问题通常也不是独立存在的。那当多个性能问题同时发生的时候,应该先去优化哪一个呢?
在性能测试的领域,流传很广的一个说法是“二八原则”,也就是说 80% 的问题都是由 20% 的代码导致的。只要找出这 20% 的位置,你就可以优化 80% 的性能。所以,我想表达的是,并不是所有的性能问题都值得优化。
我的建议是,动手优化之前先动脑,先把所有这些性能问题给分析一遍,找出最重要的、可以最大程度提升性能的问题,从它开始优化。这样的好处是,不仅性能提升的收益最大,而且很可能其他问题都不用优化,就已经满足了性能要求。
那关键就在于,怎么判断出哪个性能问题最重要。这其实还是我们性能分析要解决的核心问题,只不过这里要分析的对象,从原来的一个问题,变成了多个问题,思路其实还是一样的。
所以,你依然可以用我前面讲过的方法挨个分析,分别找出它们的瓶颈。分析完所有问题后,再按照因果等关系,排除掉有因果关联的性能问题。最后,再对剩下的性能问题进行优化。
如果剩下的问题还是好几个,你就得分别进行性能测试了。比较不同的优化效果后,选择能明显提升性能的那个问题进行修复。这个过程通常会花费较多的时间,这里,我推荐两个可以简化这个过程的方法。
第一,如果发现是系统资源达到了瓶颈,比如 CPU 使用率达到了 100%,那么首先优化的一定是系统资源使用问题。完成系统资源瓶颈的优化后,我们才要考虑其他问题。
第二,针对不同类型的指标,首先去优化那些由瓶颈导致的,性能指标变化幅度最大的问题。比如产生瓶颈后,用户 CPU 使用率升高了 10%,而系统 CPU 使用率却升高了 50%,这个时候就应该首先优化系统 CPU 的使用。
有多种优化方法要如何选择
接着来看第三个问题,当多种方法都可用时,应该选择哪一种呢?是不是最大提升性能的方法,一定最好呢?
一般情况下,我们当然想选能最大提升性能的方法,这其实也是性能优化的目标。
但要注意,现实情况要考虑的因素却没那么简单。最直观来说,性能优化并非没有成本。
性能优化通常会带来复杂度的提升,降低程序的可维护性,还可能在优化一个指标时,引发其他指标的异常。也就是说,很可能你优化了一个指标,另一个指标的性能却变差了。
一个很典型的例子是我将在网络部分讲到的 DPDK(Data Plane Development Kit)。
DPDK 是一种优化网络处理速度的方法,它通过绕开内核网络协议栈的方法,提升网络的处理能力。
不过它有一个很典型的要求,就是要独占一个 CPU 以及一定数量的内存大页,并且总是以 100% 的 CPU 使用率运行。所以,如果你的 CPU 核数很少,就有点得不偿失了。
所以,在考虑选哪个性能优化方法时,你要综合多方面的因素。切记,不要想着“一步登天”,试图一次性解决所有问题;也不要只会“拿来主义”,把其他应用的优化方法原封不动拿来用,却不经过任何思考和分析。
清楚了性能优化最基本的三个问题后,我们接下来从应用程序和系统的角度,分别来看看如何才能降低 CPU 使用率,提高 CPU 的并行处理能力。
应用程序优化
首先,从应用程序的角度来说,降低 CPU 使用率的最好方法当然是,排除所有不必要的工作,只保留最核心的逻辑。比如减少循环的层次、减少递归、减少动态内存分配等等。
除此之外,应用程序的性能优化也包括很多种方法,我在这里列出了最常见的几种,你可以记下来。
- 编译器优化:很多编译器都会提供优化选项,适当开启它们,在编译阶段你就可以获得编译器的帮助,来提升性能。比如, gcc 就提供了优化选项 -O2,开启后会自动对应用程序的代码进行优化。
- 算法优化:使用复杂度更低的算法,可以显著加快处理速度。比如,在数据比较大的情况下,可以用 O(nlogn) 的排序算法(如快排、归并排序等),代替 O(n^2) 的排序算法(如冒泡、插入排序等)。
- 异步处理:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。比如,把轮询替换为事件通知,就可以避免轮询耗费 CPU 的问题。
- 多线程代替多进程:前面讲过,相对于进程的上下文切换,线程的上下文切换并不切换进程地址空间,因此可以降低上下文切换的成本。
- 善用缓存:经常访问的数据或者计算过程中的步骤,可以放到内存中缓存起来,这样在下次用时就能直接从内存中获取,加快程序的处理速度。
系统优化
从系统的角度来说,优化 CPU 的运行,一方面要充分利用 CPU 缓存的本地性,加速缓存访问;另一方面,就是要控制进程的 CPU 使用情况,减少进程间的相互影响。
具体来说,系统层面的 CPU 优化方法也有不少,这里我同样列举了最常见的一些方法,方便你记忆和使用。
- CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨 CPU 调度带来的上下文切换问题。
- CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些 CPU。
- 优先级调整:使用 nice 调整进程的优先级,正值调低优先级,负值调高优先级。优先级的数值含义前面我们提到过,忘了的话及时复习一下。在这里,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
- 为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
- NUMA(Non-Uniform Memory Access)优化:支持 NUMA 的处理器会被划分为多个 node,每个 node 都有自己的本地内存空间。NUMA 优化,其实就是让 CPU 尽可能只访问本地内存。
- 中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
千万避免过早优化
掌握上面这些优化方法后,我估计,很多人即使没发现性能瓶颈,也会忍不住把各种各样的优化方法带到实际的开发中。
不过,我想你一定听说过高德纳的这句名言, “过早优化是万恶之源”,我也非常赞同这一点,过早优化不可取。
因为,一方面,优化会带来复杂性的提升,降低可维护性;另一方面,需求不是一成不变的。针对当前情况进行的优化,很可能并不适应快速变化的新需求。这样,在新需求出现时,这些复杂的优化,反而可能阻碍新功能的开发。
所以,性能优化最好是逐步完善,动态进行,不追求一步到位,而要首先保证能满足当前的性能要求。当发现性能不满足要求或者出现性能瓶颈时,再根据性能评估的结果,选择最重要的性能问题进行优化。
总结
今天,我带你梳理了常见的 CPU 性能优化思路和优化方法。发现性能问题后,不要急于动手优化,而要先找出最重要的、可以获得最大性能提升的问题,然后再从应用程序和系统两个方面入手优化。
这样不仅可以获得最大的性能提升,而且很可能不需要优化其他问题,就已经满足了性能要求。
但是记住,一定要忍住“把 CPU 性能优化到极致”的冲动,因为 CPU 并不是唯一的性能因素。在后续的文章中,我还会介绍更多的性能问题,比如内存、网络、I/O 甚至是架构设计的问题。
如果不做全方位的分析和测试,只是单纯地把某个指标提升到极致,并不一定能带来整体的收益。