性能调优大纲
关于系统调优方向性、大纲性的笔记。
参考资料
系统性能定义
- Throughput ,吞吐量。也就是每秒钟可以处理的请求数,任务数。
- Latency, 系统延迟。也就是系统在处理一个请求或一个任务时的延迟。
一般来说,一个系统的性能受到这两个条件的约束,缺一不可。比如,我的系统可以顶得住一百万的并发,但是系统的延迟是2分钟以上,那么,这个一百万的负载毫无意义。系统延迟很短,但是吞吐量很低,同样没有意义。所以,一个好的系统的性能测试必然受到这两个条件的同时作用。 有经验的朋友一定知道,这两个东西的一些关系:
- Throughput越大,Latency会越差。因为请求量过大,系统太繁忙,所以响应速度自然会低。
- Latency越好,能支持的Throughput就会越高。因为Latency短说明处理速度快,于是就可以处理更多的请求。
QPS和服务端并发数
QPS是每秒钟处理的请求数。对于一个系统来说,这个值有一个上限,压测的一个目的是测出这个最大值,来评估我们系统的能力。
系统并发数(服务端)是一个时刻能系统中有多少在处理中的请求。对于一个系统来说,当然这个值也有一个上限,压测也可以测出最大并发数。
特指服务端的并发数,不是客户端的并发数(并发用户数)。

平均耗时avg,即一个请求从被接收到,到处理完成所耗费的平均时间。
上述三者有一个关系即:并发数=QPS * avg。
这个公式可以这么理解:假设qps=1000,avg=50ms,设并发数为x。那么这x个请求是系统正在处理的,他们平均需要50ms处理完成。那么50ms内系统能处理多少请求呢?就是1000 50ms=1000 0.05s=50个。也就是当前的并发数x=50。
再比如,每秒钟能处理100个请求(qps)。每个请求处理2秒(avg)。那么每个时刻都有200个请求(并发量)在处理,并发数为200。
系统实时并发数低,并不代表系统的处理能力差。相反,在系统处理较快时,没有请求积压,并发数接近于0。
压测思路:(可以使用jmeter等进行压测)设定x个线程去同时请求接口(人为指定并发数为x),测得此时的qps、平均耗时等值。然后逐渐增大并发数进行测试,随着并发数的增大qps会逐渐增大直到达到一个最大值。这时我们就得到了系统的一个qps上限。这时如果并发数继续增大,因为qps已经到达上限了,那么为了满足并发=qps*avg的公式,只能增大耗时,也就是会看到耗时的增加,接口响应变慢。
此外,还可以不断增大并发数直到接口响应出现error,测得一个系统能承载的最大并发数。
实际上,更多人更倾向更直观的qps来表示系统能处理的能力,而不是服务端并发数,因为它不容易理解。
另外,还有一个并发用户数,指的是用户侧同时发起的并发请求数。很容易跟系统服务端的并发数混淆。注意区分这二者的区别。

系统性能测试
经过上述的说明,我们知道要测试系统的性能,需要我们收集系统的Throughput和Latency这两个值。
首先,需要定义Latency这个值,比如说,对于网站系统响应时间必需是5秒以内(对于某些实时系统可能需要定义的更短,比如5ms以内,这个更根据不同的业务来定义)
其次,开发性能测试工具,一个工具用来制造高强度的Throughput,另一个工具用来测量Latency。对于第一个工具,你可以参考一下“十个免费的Web压力测试工具”,关于如何测量Latency,你可以在代码中测量,但是这样会影响程序的执行,而且只能测试到程序内部的Latency,真正的Latency是整个系统都算上,包括操作系统和网络的延时,你可以使用Wireshark来抓网络包来测量。这两个工具具体怎么做,这个还请大家自己思考去了。
最后,开始性能测试。你需要不断地提升测试的Throughput,然后观察系统的负载情况,如果系统顶得住,那就观察Latency的值。这样,你就可以找到系统的最大负载,并且你可以知道系统的响应延时是多少。
关于Latency,如果吞吐量很少,这个值估计会非常稳定,当吞吐量越来越大时,系统的Latency会出现非常剧烈的抖动,所以,我们在测量Latency的时候,我们需要注意到Latency的分布,也就是说,有百分之几的在我们允许的范围,有百分之几的超出了,有百分之几的完全不可接受。也许,平均下来的Latency达标了,但是其中仅有50%的达到了我们可接受的范围。那也没有意义。
关于性能测试,我们还需要定义一个时间段。比如:在某个吞吐量上持续15分钟。因为当负载到达的时候,系统会变得不稳定,当过了一两分钟后,系统才会稳定。另外,也有可能是,你的系统在这个负载下前几分钟还表现正常,然后就不稳定了,甚至垮了。所以,需要这么一段时间。这个值,我们叫做峰值极限。
性能测试还需要做Soak Test,也就是在某个吞吐量下,系统可以持续跑一周甚至更长。这个值,我们叫做系统的正常运行的负载极限。
性能测试有很多很复要的东西,比如:burst test等。 这里不能一一详述,这里只说了一些和性能调优相关的东西。总之,性能测试是一细活和累活。
定位性能瓶颈
有了上面的铺垫,我们就可以测试到到系统的性能了,再调优之前,我们先来说说如何找到性能的瓶颈。
查看操作系统负载
首先,当我们系统有问题的时候,我们不要急于去调查我们代码,这个毫无意义。我们首要需要看的是操作系统的报告。看看操作系统的CPU利用率,看看内存使用率,看看操作系统的IO,还有网络的IO,网络链接数,等等。Windows下的perfmon是一个很不错的工具,Linux下也有很多相关的命令和工具,比如:SystemTap,LatencyTOP,vmstat, sar, iostat, top, tcpdump等等 。通过观察这些数据,我们就可以知道我们的软件的性能基本上出在哪里。比如: 1)先看CPU利用率,如果CPU利用率不高,但是系统的Throughput和Latency上不去了,这说明我们的程序并没有忙于计算,而是忙于别的一些事,比如IO。(另外,CPU的利用率还要看内核态的和用户态的,内核态的一上去了,整个系统的性能就下来了。而对于多核CPU来说,CPU 0 是相当关键的,如果CPU 0的负载高,那么会影响其它核的性能,因为CPU各核间是需要有调度的,这靠CPU0完成)
2)然后,我们可以看一下IO大不大,IO和CPU一般是反着来的,CPU利用率高则IO不大,IO大则CPU就小。关于IO,我们要看三个事,一个是磁盘文件IO,一个是驱动程序的IO(如:网卡),一个是内存换页率。这三个事都会影响系统性能。
3)然后,查看一下网络带宽使用情况,在Linux下,你可以使用iftop, iptraf, ntop, tcpdump这些命令来查看。或是用Wireshark来查看。
4)如果CPU不高,IO不高,内存使用不高,网络带宽使用不高。但是系统的性能上不去。这说明你的程序有问题,比如,你的程序被阻塞了。可能是因为等那个锁,可能是因为等某个资源,或者是在切换上下文。
通过了解操作系统的性能,我们才知道性能的问题,比如:带宽不够,内存不够,TCP缓冲区不够,等等,很多时候,不需要调整程序的,只需要调整一下硬件或操作系统的配置就可以了。
使用Profiler测试
接下来,我们需要使用性能检测工具,也就是使用某个Profiler来差看一下我们程序的运行性能。如:Java的JProfiler/TPTP/CodePro Profiler,GNU的gprof,IBM的PurifyPlus,Intel的VTune,AMD的CodeAnalyst,还有Linux下的OProfile/perf,后面两个可以让你对你的代码优化到CPU的微指令级别,如果你关心CPU的L1/L2的缓存调优,那么你需要考虑一下使用VTune。
使用这些Profiler工具,可以让你程序中各个模块函数甚至指令的很多东西,如:运行的时间 ,调用的次数,CPU的利用率,等等。这些东西对我们来说非常有用。
我们重点观察运行时间最多,调用次数最多的那些函数和指令。这里注意一下,对于调用次数多但是时间很短的函数,你可能只需要轻微优化一下,你的性能就上去了(比如:某函数一秒种被调用100万次,你想想如果你让这个函数提高0.01毫秒的时间 ,这会给你带来多大的性能)
使用Profiler有个问题我们需要注意一下,因为Profiler会让你的程序运行的性能变低,像PurifyPlus这样的工具会在你的代码中插入很多代码,会导致你的程序运行效率变低,从而没发测试出在高吞吐量下的系统的性能,对此,一般有两个方法来定位系统瓶颈:
1)在你的代码中自己做统计,使用微秒级的计时器和函数调用计算器,每隔10秒把统计log到文件中。
2)分段注释你的代码块,让一些函数空转,做Hard Code的Mock,然后再测试一下系统的Throughput和Latency是否有质的变化,如果有,那么被注释的函数就是性能瓶颈,再在这个函数体内注释代码,直到找到最耗性能的语句。
最后再说一点,对于性能测试,不同的Throughput会出现不同的测试结果,不同的测试数据也会有不同的测试结果。所以,用于性能测试的数据非常重要,性能测试中,我们需要观测试不同Throughput的结果。
常见的系统瓶颈
太多了。参考陈皓博客原文,还有更多细分的笔记。
性能排查工具
我们可以从系统和应用程序两个角度,来进行性能优化。
- 从系统的角度来说,主要是对 CPU、内存、网络、磁盘 I/O 以及内核软件资源等进行优化。
- 而从应用程序的角度来说,主要是简化代码、降低 CPU 使用、减少网络请求和磁盘 I/O,并借助缓存、异步处理、多进程和多线程等,提高应用程序的吞吐能力。
性能优化最好逐步完善,动态进行。不要追求一步到位,而要首先保证能满足当前的性能要求。性能优化通常意味着复杂度的提升,也意味着可维护性的降低。
如果你发现单机的性能调优带来过高复杂度,一定不要沉迷於单机的极限性能,而要从软件架构的角度,以水平扩展的方法来提升性能。
工欲善其事,必先利其器。我们知道,在性能分析和优化时,借助合适的性能工具,可以让整个过程事半功倍。你还记得有哪些常用的性能工具吗?今天,我就带你一起梳理一下常用的性能工具,以便你在需要时,可以迅速找到自己想要的。
在梳理性能工具之前,首先给你提一个问题,那就是,在什么情况下,我们才需要去查找、挑选性能工具呢?你可以先自己想一下,再继续下面的内容。
其实在我看来,只有当你想了解某个性能指标,却不知道该怎么办的时候,才会想到,“要是有一个性能工具速查表就好了”这个问题。如果已知一个性能工具可用,我们更多会去查看这个工具的手册,找出它的功能、用法以及注意事项。
关于工具手册的查看,man 应该是我们最熟悉的方法,我在专栏中多次介绍过。实际上,除了 man 之外,还有另外一个查询命令手册的方法,也就是 info。
info 可以理解为 man 的详细版本,提供了诸如节点跳转等更强大的功能。相对来说,man 的输出比较简洁,而 info 的输出更详细。所以,我们通常使用 man 来查询工具的使用方法,只有在 man 的输出不太好理解时,才会再去参考 info 文档。
当然,我说过了,要查询手册,前提一定是已知哪个工具可用。如果你还不知道要用哪个工具,就要根据想了解的指标,去查找有哪些工具可用。这其中:
- 有些工具不需要额外安装,就可以直接使用,比如内核的 /proc 文件系统;
- 而有些工具,则需要安装额外的软件包,比如 sar、pidstat、iostat 等。
所以,在选择性能工具时,除了要考虑性能指标这个目的外,还要结合待分析的环境来综合考虑。比如,实际环境是否允许安装软件包,是否需要新的内核版本等。
明白了工具选择的基本原则后,我们来看 Linux 的性能工具。首先还是要推荐下面这张图,也就是 Brendan Gregg 整理的性能工具谱图。我在专栏中多次提到过,你肯定也已经参考过。
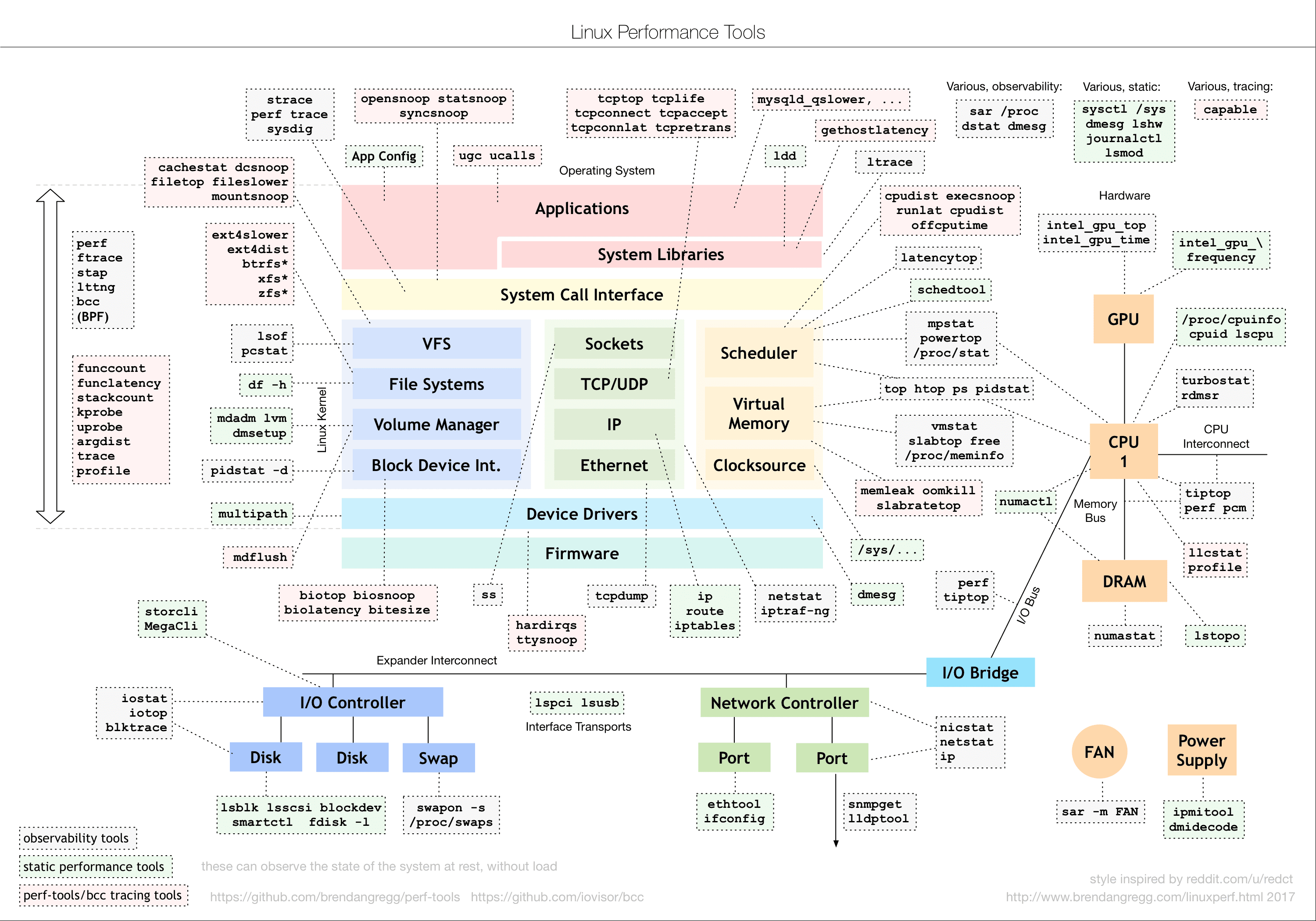 (图片来自 brendangregg.com)
(图片来自 brendangregg.com)
这张图从 Linux 内核的各个子系统出发,汇总了对各个子系统进行性能分析时,你可以选择的工具。不过,虽然这个图是性能分析最好的参考资料之一,它其实还不够具体。
比如,当你需要查看某个性能指标时,这张图里对应的子系统部分,可能有多个性能工具可供选择。但实际上,并非所有这些工具都适用,具体要用哪个,还需要你去查找每个工具的手册,对比分析做出选择。
那么,有没有更好的方法来理解这些工具呢?我的建议,还是从性能指标出发,根据性能指标的不同,将性能工具划分为不同类型。比如,最常见的就是可以根据 CPU、内存、磁盘 I/O 以及网络的各类性能指标,将这些工具进行分类。
接下来,我就从 CPU、内存、磁盘 I/O 以及网络等几个角度,梳理这些常见的 Linux 性能工具,特别是从性能指标的角度出发,理清楚到底有哪些工具,可以用来监测特定的性能指标。这些工具,实际上贯穿在我们专栏各模块的各个案例中。为了方便你查看,我将它们都整理成了表格,并增加了每个工具的使用场景。
CPU 性能工具
首先,从 CPU 的角度来说,主要的性能指标就是 CPU 的使用率、上下文切换以及 CPU Cache 的命中率等。下面这张图就列出了常见的 CPU 性能指标。
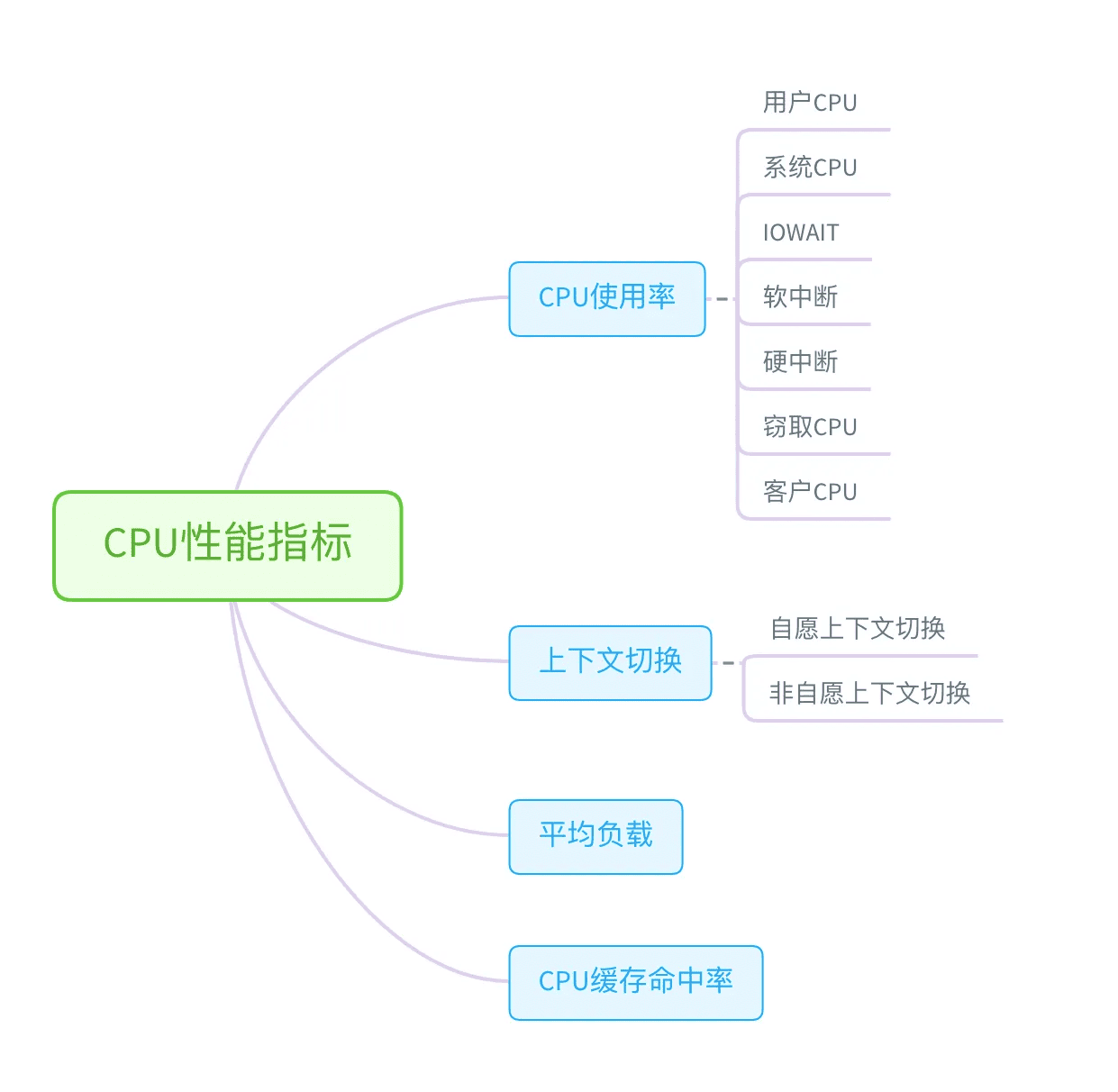
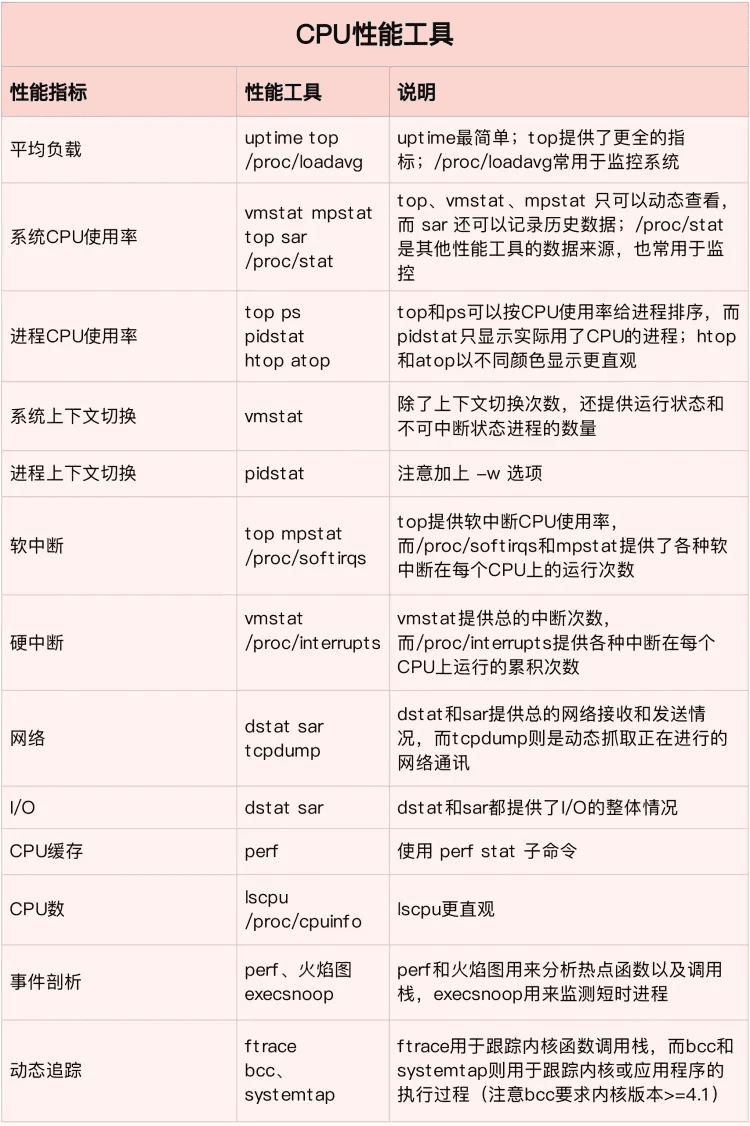
从这些指标出发,再把 CPU 使用率,划分为系统和进程两个维度,我们就可以得到,下面这个 CPU 性能工具速查表。注意,因为每种性能指标都可能对应多种工具,我在每个指标的说明中,都帮你总结了这些工具的特点和注意事项。这些也是你需要特别关注的地方。
内存性能工具
接着我们来看内存方面。从内存的角度来说,主要的性能指标,就是系统内存的分配和使用、进程内存的分配和使用以及 SWAP 的用量。下面这张图列出了常见的内存性能指标。
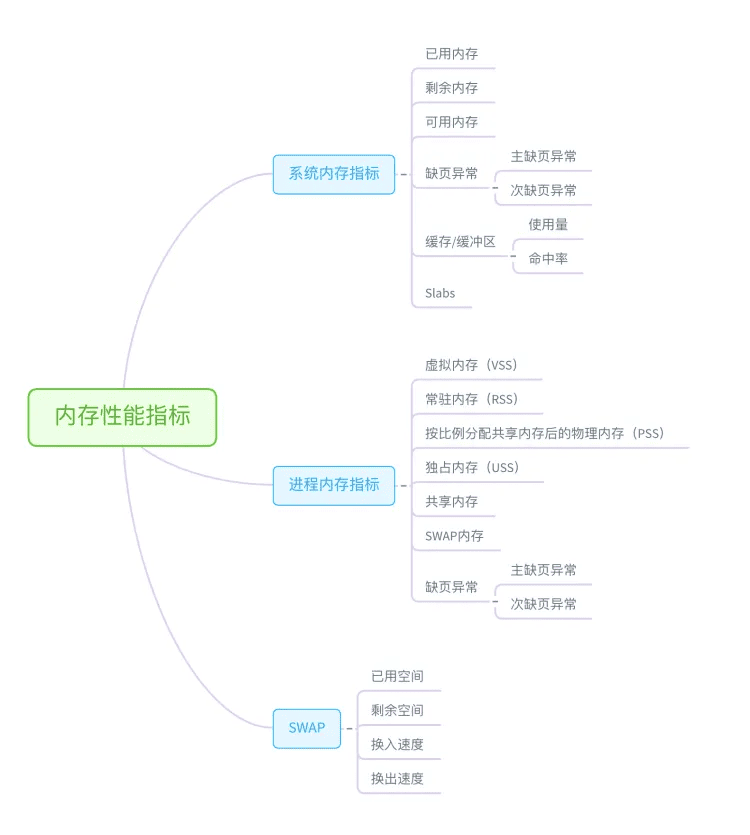
从这些指标出发,我们就可以得到如下表所示的内存性能工具速查表。同 CPU 性能工具一样,这儿我也帮你梳理了,常见工具的特点和注意事项。
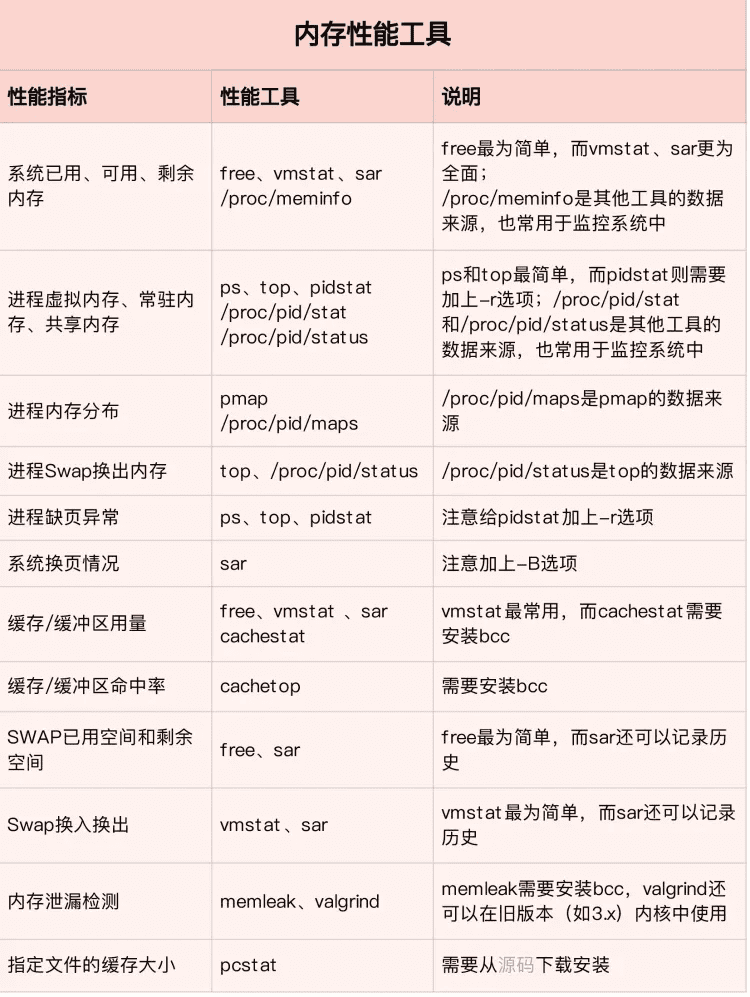
注:最后一行 pcstat 的源码链接为 https://github.com/tobert/pcstat
磁盘 I/O 性能工具
接下来,从文件系统和磁盘 I/O 的角度来说,主要性能指标,就是文件系统的使用、缓存和缓冲区的使用,以及磁盘 I/O 的使用率、吞吐量和延迟等。下面这张图列出了常见的 I/O 性能指标。
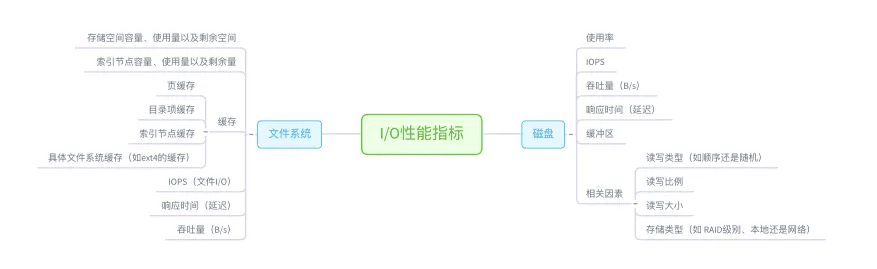
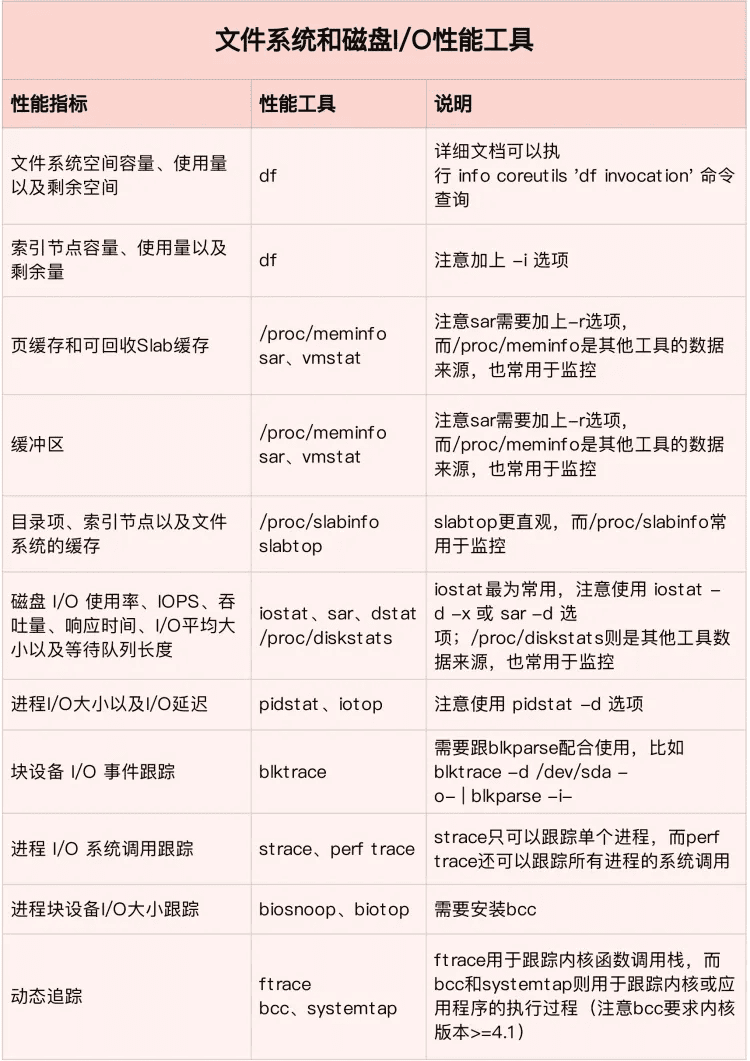
从这些指标出发,我们就可以得到,下面这个文件系统和磁盘 I/O 性能工具速查表。同 CPU 和内存性能工具一样,我也梳理出了这些工具的特点和注意事项。
网络性能工具
最后,从网络的角度来说,主要性能指标就是吞吐量、响应时间、连接数、丢包数等。根据 TCP/IP 网络协议栈的原理,我们可以把这些性能指标,进一步细化为每层协议的具体指标。这里我同样用一张图,分别从链路层、网络层、传输层和应用层,列出了各层的主要指标。
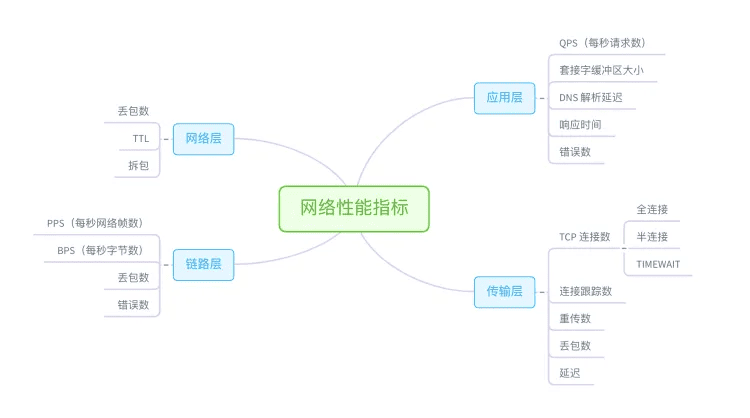
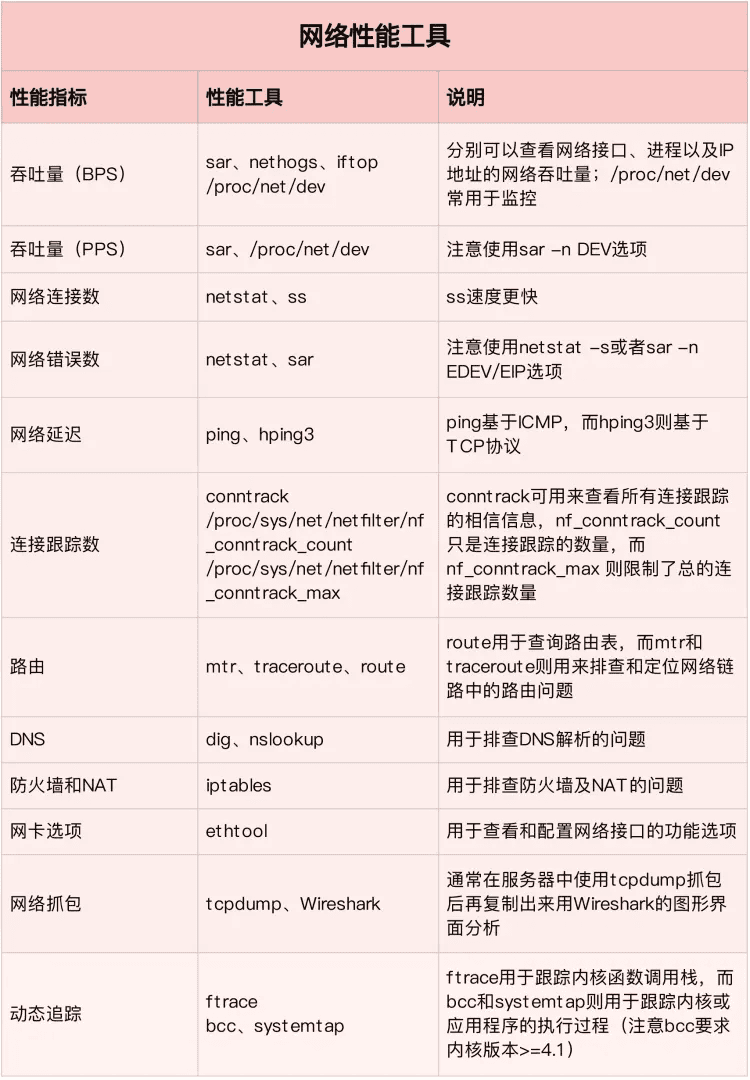
从这些指标出发,我们就可以得到下面的网络性能工具速查表。同样的,我也帮你梳理了各种工具的特点和注意事项。
基准测试工具
除了性能分析外,很多时候,我们还需要对系统性能进行基准测试。比如,
- 在文件系统和磁盘 I/O 模块中,我们使用 fio 工具,测试了磁盘 I/O 的性能。
- 在网络模块中,我们使用 iperf、pktgen 等,测试了网络的性能。
- 而在很多基于 Nginx 的案例中,我们则使用 ab、wrk 等,测试 Nginx 应用的性能。
除了专栏里介绍过的这些工具外,对于 Linux 的各个子系统来说,还有很多其他的基准测试工具可能会用到。下面这张图,是 Brendan Gregg 整理的 Linux 基准测试工具图谱,你可以保存下来,在需要时参考。
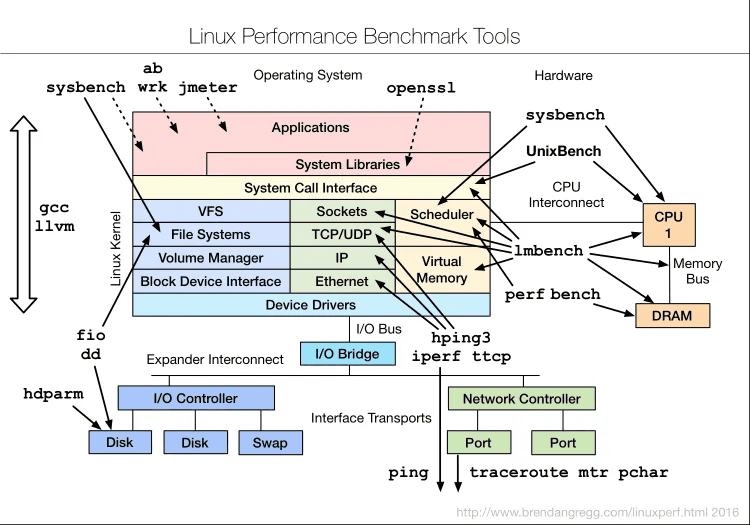
排查工具小结
今天,我们一起梳理了常见的性能工具,并从 CPU、内存、文件系统和磁盘 I/O、网络以及基准测试等不同的角度,汇总了各类性能指标所对应的性能工具速查表。 当分析性能问题时,大的来说,主要有这么两个步骤:
- 第一步,从性能瓶颈出发,根据系统和应用程序的运行原理,确认待分析的性能指标。
- 第二步,根据这些图表,选出最合适的性能工具,然后了解并使用工具,从而更快观测到需要的性能数据。
虽然 Linux 的性能指标和性能工具都比较多,但熟悉了各指标含义后,你自然就会发现这些工具同性能指标间的关联。顺着这个思路往下走,掌握这些工具的选用其实并不难。
当然,正如咱们专栏一直强调的,不要把性能工具当成性能分析和优化的全部。
- 一方面,性能分析和优化的核心,是对系统和应用程序运行原理的掌握,而性能工具只是辅助你更快完成这个过程的帮手。
- 另一方面,完善的监控系统,可以提供绝大部分性能分析所需的基准数据。从这些数据中,你很可能就能大致定位出性能瓶颈,也就不用再去手动执行各类工具了。