Linux进程相关笔记
进程与文件句柄
进程与文件句柄的区别

进程与文件句柄的关联

进程的组成
进程是操作系统进行资源分配和调度的基本单位,一个进程的完整组成通常包括以下几个部分:
进程控制块(Process Control Block, PCB):
- 这是操作系统用于跟踪和管理进程的数据结构,包含了进程的几乎所有状态信息,如进程ID、状态、优先级、调度信息、程序计数器、寄存器集合、堆栈指针、进程状态信息等。
程序代码:
- 进程执行的指令集,存储在内存的代码段中。
数据:
- 进程运行时需要的数据,包括全局变量、静态变量、堆栈等。
内存空间:
- 每个进程都有自己的虚拟地址空间,通常包括代码段、数据段、堆(heap)和栈(stack)。
文件描述符(File Descriptors):
- 进程打开的文件和网络连接的句柄集合。
环境变量(Environment Variables):
- 进程运行时的环境设置,包括变量和值。
信号处理(Signal Handling):
- 进程如何处理接收到的信号。
资源限制(Resource Limits):
- 进程可以使用的资源限制,如CPU时间、内存大小、文件句柄数等。
线程(Threads):
- 在多线程的进程中,除了主线程外,还可以有多个用户级线程。每个线程都有自己的堆栈和寄存器,但共享进程的代码段、数据段和环境变量。
进程状态:
- 包括就绪态、运行态、阻塞态等。
调度信息:
- 与进程调度相关的信息,如进程的优先级、调度策略等。
内存管理信息:
- 如页表、虚拟内存管理信息等。
I/O状态信息:
- 进程进行I/O操作的状态信息。
控制终端:
- 进程的控制终端信息,用于交互式进程。
会计信息:
- 进程的资源使用记录,如CPU时间、内存使用量等。
安全和权限信息:
- 进程的安全上下文和权限设置。
这些组件共同定义了一个进程的生命周期和行为。操作系统通过这些组件来创建、管理和终止进程,以及在进程之间进行资源分配和调度。
进程上下文
上下文(Context)确实是进程的一个重要组成部分,它属于进程的一部分。在操作系统中,上下文指的是CPU寄存器的集合,这些寄存器保存了进程执行的状态,包括程序计数器(PC)、各种通用寄存器、指令寄存器、状态寄存器和程序状态字(PSW)等。上下文切换(Context Switching)是指在多任务操作系统中,当CPU从一个进程切换到另一个进程时,保存当前进程的状态(上下文),并恢复下一个要执行的进程的状态的过程。
上下文是进程执行时的“快照”,它包括了以下内容:
程序计数器(Program Counter, PC):
- 指示下一条要执行的指令的位置。
寄存器集合:
- 包括通用寄存器、专用寄存器等,它们保存了进程执行时的中间数据。
程序状态字(Program Status Word, PSW):
- 包含CPU的状态信息,如中断标志、条件码等。
栈指针(Stack Pointer, SP):
- 指向进程栈的顶部,用于管理局部变量和函数调用。
帧指针(Frame Pointer, FP):
- 指向当前函数的栈帧的开始,用于访问函数的局部变量和参数。
浮点寄存器:
- 如果CPU支持浮点运算,还会有一组浮点寄存器。
上下文是进程控制块(PCB)中的一部分,PCB是操作系统用来管理进程的数据结构,包含了进程的所有必要信息,上下文信息是其中的关键部分。当进程被调度执行时,操作系统会将进程的上下文加载到CPU的寄存器中,以便进程能够从上次停止的地方继续执行。当进程被挂起或阻塞时,操作系统会保存进程的上下文,以便之后能够恢复执行。
修改文件描述符
关于文件描述符:
查看进程允许打开的最大文件句柄数:
bash
ulimit -n设置进程能打开的最大文件句柄数:
bash
ulimit -n xxx配置修改
编辑/etc/security/limits.conf
* soft nofile 65535
* soft noproc 65535
* hard nofile 65535
* hard noproc 65535
root soft nofile 65535
root soft noproc 65535
root hard nofile 65535
root hard noproc 65535如果只改文件描述符,不改进程数量:
* soft nofile 65535
* hard nofile 65535
root soft nofile 65535
root hard nofile 65535如果是debian系列,需要指出具体的用户,不能用通配符*,centos可以。
修改对应配置
编辑 /etc/systemd/user.conf 和 /etc/systemd/system.conf 文件(如果需要)。
在这两个文件中,你需要取消注释并设置 DefaultLimitNOFILE 的值为你想要的文件描述符限制值:
vim /etc/systemd/user.conf
DefaultLimitNOFILE=65536
DefaultLimitNPROC=65535该配置文件默认值(linuxmint下):
#DefaultLimitNPROC=
#DefaultLimitNOFILE=vim /etc/systemd/system.conf
DefaultLimitNOFILE=65536:655350
DefaultLimitNPROC=65535该配置文件默认值(linuxmint下):
#DefaultLimitNPROC=
#DefaultLimitNOFILE=1024:524288(格式与user里面的不一样。)配置项说明
root: 配置的目标用户
soft: 软限制
hard: 硬限制
nofile: 文件描述符限制
noproc: 进程数限制这里 * 表示对所有用户生效,soft 是软限制,hard 是硬限制。nofile 是文件描述符的限制。
请注意:
*号通配并不匹配 root 用户的行为,是 Debian 系列特有的;我们测试了 Centos 并看了 Centos 的文档,*号是可以匹配 root 用户。
你可以将 65535 替换为你希望的值。
修改相应配之后,你可能需要重启整个系统,以使更改生效。
检查修改:修改后,你可以使用 ulimit -n 命令来检查当前的文件描述符限制是否已经更新。
测试在linuxmint下面,修改完注销不生效,要重启服务器才行。也出现普通用户生效,但root用户不生效的场景。
总结最小必须的修改是以下:
* soft nofile 65535
* hard nofile 65535
root soft nofile 65535
root hard nofile 65535然后:
vim /etc/systemd/user.conf
DefaultLimitNOFILE=65536 必须应该要重启系统才能生效。这样普通用户和root用户使用ulimit -n就都生效了。
此外,需要修改内核参数,nginx参数等配合。
参考资料
- https://blog.csdn.net/u010844836/article/details/136058393
- https://www.163.com/dy/article/FAM1KC5C0511CUTF.html
进程与线程开销上的区别

一个是申请内存空间,给各个线程共用;线程主要用于计算。
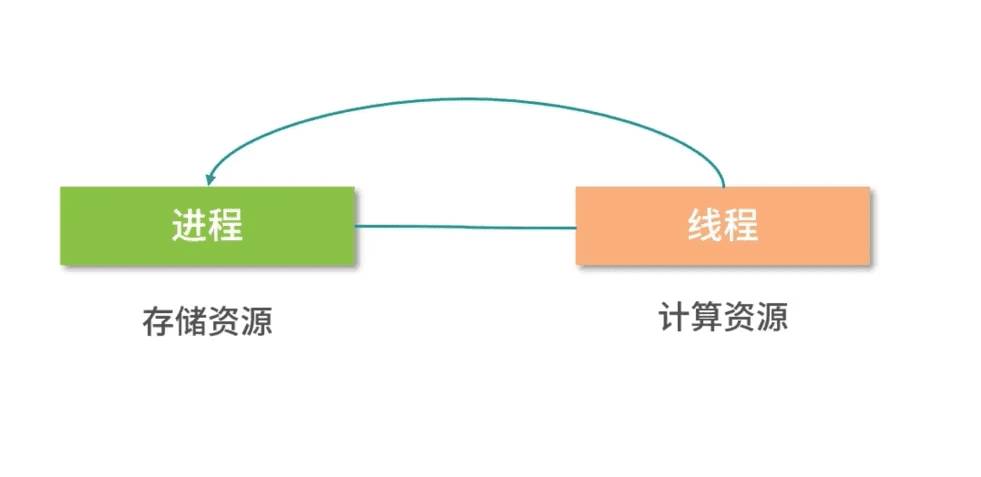
进程状态
我们挨个来看一下:
R是 Running 或 Runnable 的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行。D是 Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断。Z是 Zombie 的缩写,如果你玩过“植物大战僵尸”这款游戏,应该知道它的意思。它表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等)。S是 Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。I是 Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。前面说了,硬件交互导致的不可中断进程用 D 表示,但对某些内核线程来说,它们有可能实际上并没有任何负载,用 Idle 正是为了区分这种情况。要注意,D 状态的进程会导致平均负载升高, I 状态的进程却不会。
上面的示例并没有包括进程的所有状态。除了以上 5 个状态,进程还包括下面这 2 个状态。
第一个是 T 或者 t,也就是 Stopped 或 Traced 的缩写,表示进程处于暂停或者跟踪状态。
向一个进程发送 SIGSTOP 信号,它就会因响应这个信号变成暂停状态(Stopped);再向它发送 SIGCONT 信号,进程又会恢复运行(如果进程是终端里直接启动的,则需要你用 fg 命令,恢复到前台运行)。
而当你用调试器(如 gdb)调试一个进程时,在使用断点中断进程后,进程就会变成跟踪状态,这其实也是一种特殊的暂停状态,只不过你可以用调试器来跟踪并按需要控制进程的运行。
另一个是 X,也就是 Dead 的缩写,表示进程已经消亡,所以你不会在 top 或者 ps 命令中看到它。
了解了这些,我们再回到今天的主题。
先看不可中断状态,这其实是为了保证进程数据与硬件状态一致,并且正常情况下,不可中断状态在很短时间内就会结束。所以,短时的不可中断状态进程,我们一般可以忽略。
但如果系统或硬件发生了故障,进程可能会在不可中断状态保持很久,甚至导致系统中出现大量不可中断进程。这时,你就得注意下,系统是不是出现了 I/O 等性能问题。
再看僵尸进程,这是多进程应用很容易碰到的问题。正常情况下,当一个进程创建了子进程后,它应该通过系统调用 wait() 或者 waitpid() 等待子进程结束,回收子进程的资源;而子进程在结束时,会向它的父进程发送 SIGCHLD 信号,所以,父进程还可以注册 SIGCHLD 信号的处理函数,异步回收资源。
如果父进程没这么做,或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经提前退出,那这时的子进程就会变成僵尸进程。换句话说,父亲应该一直对儿子负责,善始善终,如果不作为或者跟不上,都会导致“问题少年”的出现。
通常,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程退出后,由 init 进程回收后也会消亡。
一旦父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸状态。大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建,所以这种情况一定要避免。
不可中断状态和僵尸状态,是我们今天学习的重点。
- 不可中断状态,表示进程正在跟硬件交互,为了保护进程数据和硬件的一致性,系统不允许其他进程或中断打断这个进程。进程长时间处于不可中断状态,通常表示系统有 I/O 性能问题。
- 僵尸进程表示进程已经退出,但它的父进程还没有回收子进程占用的资源。短暂的僵尸状态我们通常不必理会,但进程长时间处于僵尸状态,就应该注意了,可能有应用程序没有正常处理子进程的退出。
找出僵尸进程并kill掉,shell脚本示例:
sh
#!/bin/bash
ALL_PROCESS=$(ls /proc/ | egrep '[0-9]+')
running_count=0
stoped_count=0
sleeping_count=0
zombie_count=0
for pid in ${ALL_PROCESS[*]}
do
test -f /proc/$pid/status && state=$(egrep "State" /proc/$pid/status | awk '{print $2}')
case "$state" in
R)
running_count=$((running_count+1))
;;
T)
stoped_count=$((stoped_count+1))
;;
S)
sleeping_count=$((sleeping_count+1))
;;
Z)
zombie_count=$((zombie_count+1))
echo "$pid" >>zombie.txt
kill -9 "$pid"
;;
esac
done
echo -e "total: $((running_count+stoped_count+sleeping_count+zombie_count))\nrunning: $running_count\nstoped: $stoped_count\nsleeping: $sleeping_count\nzombie: $zombie_count"进程上下文说明
进程在竞争 CPU 的时候并没有真正运行,为什么还会导致系统的负载升高呢?看到今天的主题,你应该已经猜到了,CPU 上下文切换就是罪魁祸首。
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
CPU 上下文切换,是保证 Linux 系统正常工作的核心功能之一,一般情况下不需要我们特别关注。
但过多的上下文切换,会把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降。
查看上下文切换,使用vmstat工具。
vmstat 是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。
每5秒输出一次:
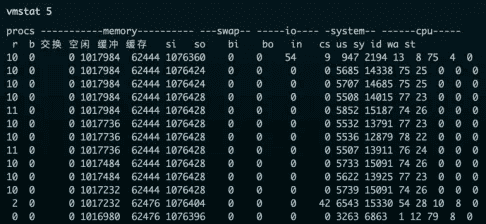
我们一起来看这个结果,你可以先试着自己解读每列的含义。在这里,我重点强调下,需要特别关注的四列内容:
- cs(context switch)是每秒上下文切换的次数。
- in(interrupt)则是每秒中断的次数。
- r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU的进程数。
- b(Blocked)则是处于不可中断睡眠状态的进程数。
vmstat 只给出了系统总体的上下文切换情况,要想查看每个进程的详细情况,就需要使用我们前面提到过的 pidstat 了。给它加上 -w 选项,你就可以查看每个进程上下文切换的情况了。

这个结果中有两列内容是我们的重点关注对象。一个是 cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是 nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
这两个概念你一定要牢牢记住,因为它们意味着不同的性能问题:
- 所谓自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
- 而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
案例模拟
我们将使用 sysbench 来模拟系统多线程调度切换的情况。
sysbench 是一个多线程的基准测试工具,一般用来评估不同系统参数下的数据库负载情况。当然,在这次案例中,我们只把它当成一个异常进程来看,作用是模拟上下文切换过多的问题。
bash
sudo apt install sysbench sysstat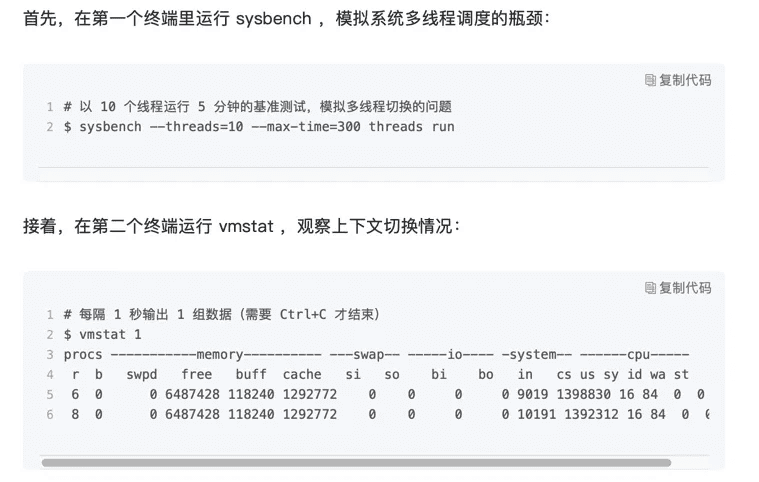
你应该可以发现,cs 列的上下文切换次数从之前的 35 骤然上升到了 139 万。同时,注意观察其他几个指标:
- r 列:就绪队列的长度已经到了 8,远远超过了系统 CPU 的个数 2,所以肯定会有大量的 CPU 竞争。
- us(user)和 sy(system)列:这两列的 CPU 使用率加起来上升到了 100%,其中系统 CPU 使用率,也就是 sy 列高达 84%,说明 CPU 主要是被内核占用了。
- in 列:中断次数也上升到了 1 万左右,说明中断处理也是个潜在的问题。
综合这几个指标,我们可以知道,系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高。
那么到底是什么进程导致了这些问题呢?
我们继续分析,在第三个终端再用 pidstat 来看一下, CPU 和进程上下文切换的情况:
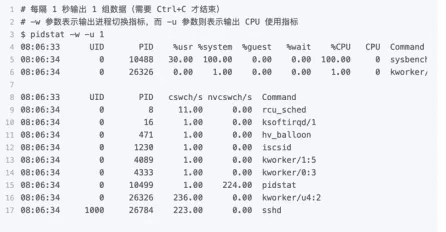
从 pidstat 的输出你可以发现,CPU 使用率的升高果然是 sysbench 导致的,它的 CPU 使用率已经达到了 100%。但上下文切换则是来自其他进程,包括非自愿上下文切换频率最高的 pidstat ,以及自愿上下文切换频率最高的内核线程 kworker 和 sshd。
不过,细心的你肯定也发现了一个怪异的事儿:pidstat 输出的上下文切换次数,加起来也就几百,比 vmstat 的 139 万明显小了太多。这是怎么回事呢?难道是工具本身出了错吗?
别着急,在怀疑工具之前,我们再来回想一下,前面讲到的几种上下文切换场景。其中有一点提到, Linux 调度的基本单位实际上是线程,而我们的场景 sysbench 模拟的也是线程的调度问题,那么,是不是 pidstat 忽略了线程的数据呢?
通过运行 man pidstat ,你会发现,pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标。
所以,我们可以在第三个终端里, Ctrl+C 停止刚才的 pidstat 命令,再加上 -t 参数,重试一下看看:
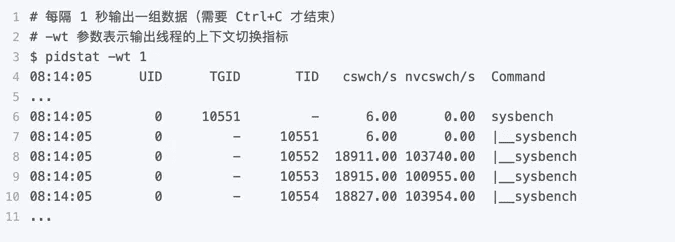
现在你就能看到了,虽然 sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。看来,上下文切换罪魁祸首,还是过多的 sysbench 线程。
我们已经找到了上下文切换次数增多的根源,那是不是到这儿就可以结束了呢?
当然不是。不知道你还记不记得,前面在观察系统指标时,除了上下文切换频率骤然升高,还有一个指标也有很大的变化。是的,正是中断次数。中断次数也上升到了 1 万,但到底是什么类型的中断上升了,现在还不清楚。我们接下来继续抽丝剥茧找源头。
既然是中断,我们都知道,它只发生在内核态,而 pidstat 只是一个进程的性能分析工具,并不提供任何关于中断的详细信息,怎样才能知道中断发生的类型呢?
没错,那就是从 /proc/interrupts 这个只读文件中读取。/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况。 我们还是在第三个终端里, Ctrl+C 停止刚才的 pidstat 命令,然后运行下面的命令,观察中断的变化情况:

观察一段时间,你可以发现,变化速度最快的是重调度中断(RES),这个中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同 CPU 的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)。
所以,这里的中断升高还是因为过多任务的调度问题,跟前面上下文切换次数的分析结果是一致的。
通过这个案例,你应该也发现了多工具、多方面指标对比观测的好处。如果最开始时,我们只用了 pidstat 观测,这些很严重的上下文切换线程,压根儿就发现不了了。
现在再回到最初的问题,每秒上下文切换多少次才算正常呢?
这个数值其实取决于系统本身的 CPU 性能。在我看来,如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。
这时,你还需要根据上下文切换的类型,再做具体分析。比方说:
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题;
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈;
- 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
通过一个 sysbench 的案例,给你讲了上下文切换问题的分析思路。碰到上下文切换次数过多的问题时,我们可以借助 vmstat 、 pidstat 和 /proc/interrupts 等工具,来辅助排查性能问题的根源。